
¿Hasta dónde puede datar un maniquí de jerga de tamaño mediano si la verdadera innovación pasa de la columna vertebral al andamio del agente y la pila de herramientas? Los investigadores de Meta y Harvard han atrevido Confucius Code Agent, un ingeniero de software de inteligencia sintético de código campechano construido sobre el SDK de Confucius que está diseñado para repositorios de software a escalera industrial y sesiones de larga duración. El sistema se enfoca en proyectos reales de GitHub, cadenas de herramientas de prueba complejas en el momento de la evaluación y resultados reproducibles en puntos de narración como SWE Bench Pro y SWE Bench Verified, al tiempo que expone el andamiada completo para los desarrolladores.
SDK de Confucio, andamiada rodeando del maniquí
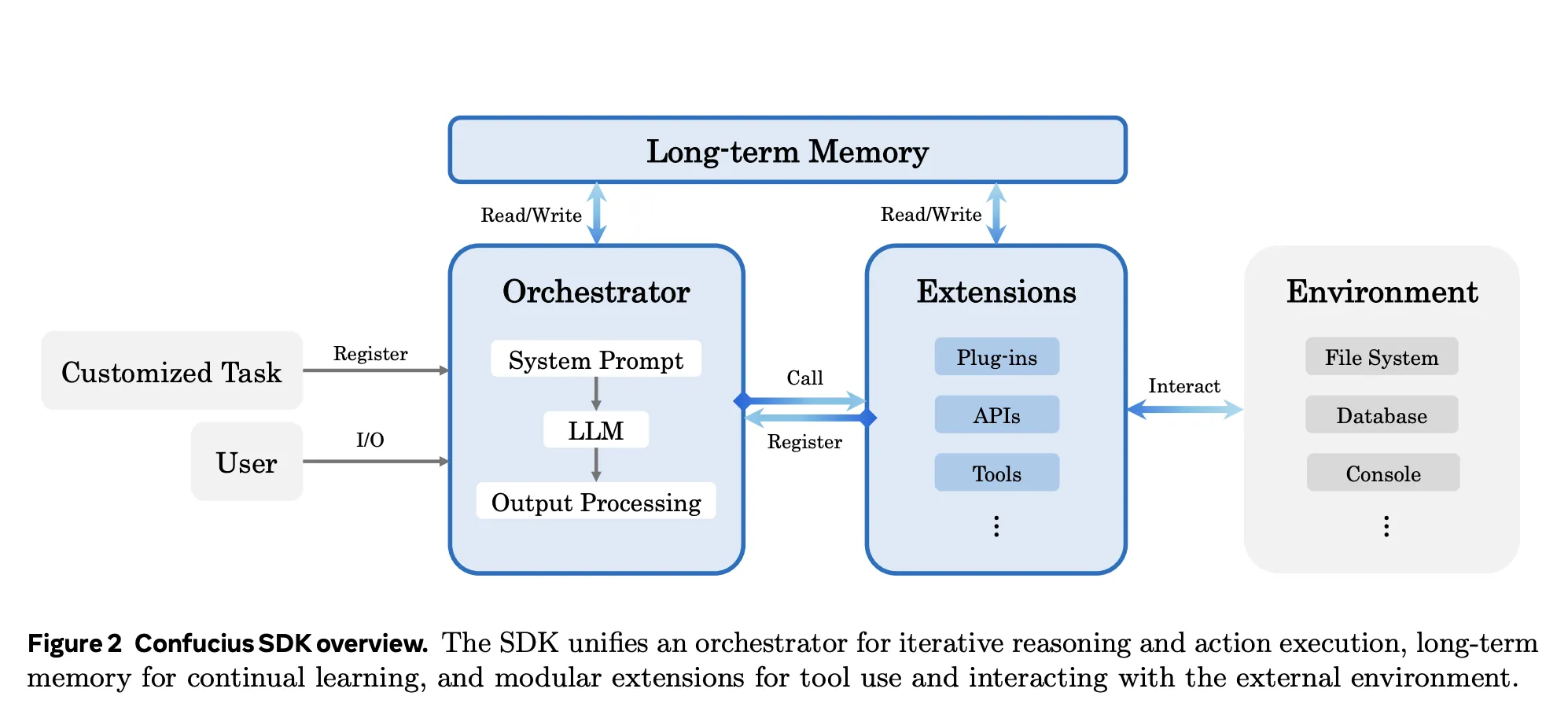
El SDK de Confucius es una plataforma de incremento de agentes que negociación el andamiada como un problema de diseño principal en espacio de una pinta flaca rodeando de un maniquí de jerga. Está organizado en torno a 3 ejes, Experiencia del agente, experiencia del favorecido y experiencia del desarrollador.
Experiencia del agente controla lo que ve el maniquí, incluido el diseño del contexto, la memoria de trabajo y los resultados de la aparejo. Experiencia de favorecido se centra en rastros legibles, diferencias de código y salvaguardias para ingenieros humanos. Experiencia del desarrollador se centra en la observabilidad, configuración y depuración del propio agente.
El SDK presenta tres mecanismos centrales: un orquestador unificado con memoria de trabajo jerárquica, un sistema de toma de notas persistente y una interfaz de extensión modular para herramientas. Luego, un metaagente automatiza la síntesis y el refinamiento de las configuraciones del agente a través de un ciclo de creación, prueba y alivio. El Agente de Código Confucio es una instancia concreta de este andamio para la ingeniería de software.
Memoria de trabajo jerárquica para codificación de dilatado horizonte
Las tareas de software reales en SWE Bench Pro a menudo requieren razonamiento sobre docenas de archivos y muchos pasos de interacción. El orquestador en Confucius SDK mantiene una memoria de trabajo jerárquica, que divide una trayectoria en alcances, resume los pasos pasados y mantiene el contexto comprimido para turnos posteriores.
Este diseño ayuda a ayudar las indicaciones interiormente de los límites del contexto del maniquí y al mismo tiempo preserva artefactos importantes como parches, registros de errores y decisiones de diseño. El punto secreto es que los agentes de codificación basados en herramientas eficaces necesitan una cimentación de memoria explícita, no sólo una ventana deslizante de mensajes anteriores.
Toma de notas persistente para el estudios entre sesiones
El segundo mecanismo es un sistema de toma de notas que utiliza un agente dedicado para escribir notas estructuradas de Markdown a partir de seguimientos de ejecución. Estas notas capturan estrategias específicas de tareas, convenciones de repositorio y modos de falta comunes, y se almacenan como memoria a dilatado plazo que se puede reutilizar en todas las sesiones.
El equipo de investigación ejecutó Confucius Code Agent dos veces en 151 instancias de SWE Bench Pro con Claude 4.5 Sonnet. En la primera ejecución, el agente resuelve tareas desde cero y genera notas. En la segunda ejecución, el agente lee estas notas. En esta configuración, los turnos promedio caen de 64 a 61, el uso de tokens cae de aproximadamente 104k a 93k y Resolve@1 alivio de 53,0 a 54,4. Esto muestra que las notas no son sólo registros, sino que funcionan como una memoria eficaz entre sesiones.
Extensiones modulares y sofisticación en el uso de herramientas.
Confucius SDK expone herramientas como extensiones, por ejemplo, impresión de archivos, ejecución de comandos, ejecutores de pruebas y búsqueda de código. Cada extensión puede ayudar su propio estado y cableado rápido.
El equipo de investigación estudia el impacto de la sofisticación del uso de herramientas mediante una separación en un subconjunto de 100 ejemplos de SWE Bench Pro. Con Claude 4 Sonnet, ocurrir de una configuración sin funciones de contexto avanzadas a una con contexto reformista aumenta Resolve@1 de 42,0 a 48,6. Con Claude 4.5 Sonnet, una configuración de uso de herramientas simple alcanza 44.0, mientras que el manejo de herramientas más rico alcanza 51.6, con 51.0 para una reforma intermedia. Estos números indican que la forma en que el agente elige y secuencia las herramientas es casi tan importante como la referéndum del maniquí principal.
Metaagente para el diseño inconsciente de agentes.
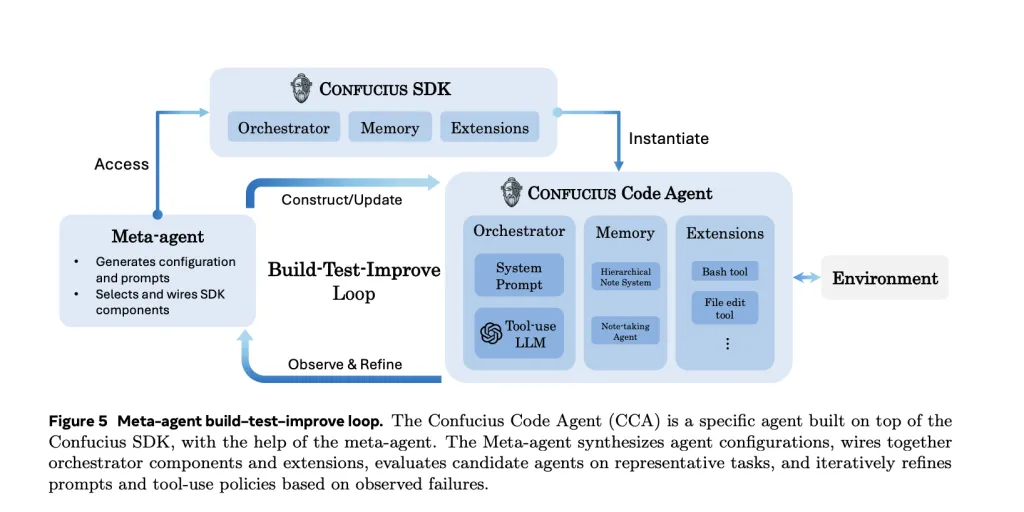
Adicionalmente de estos mecanismos, el SDK de Confucius incluye un metaagente que toma una aclaración de jerga natural de un agente y propone de forma iterativa configuraciones, indicaciones y conjuntos de extensiones. Luego ejecuta el agente candidato en tareas, inspecciona seguimientos y métricas y edita la configuración en un ciclo de compilación, prueba y alivio.
El Agente del Código Confucio que evalúa el equipo de investigación se produce con la ayuda de este metaagente, en espacio de solo ajustarse manualmente. Este enfoque convierte parte del proceso de ingeniería del agente en un problema de optimización guiado por LLM.
Resultados en SWE Bench Pro y SWE Bench Verified
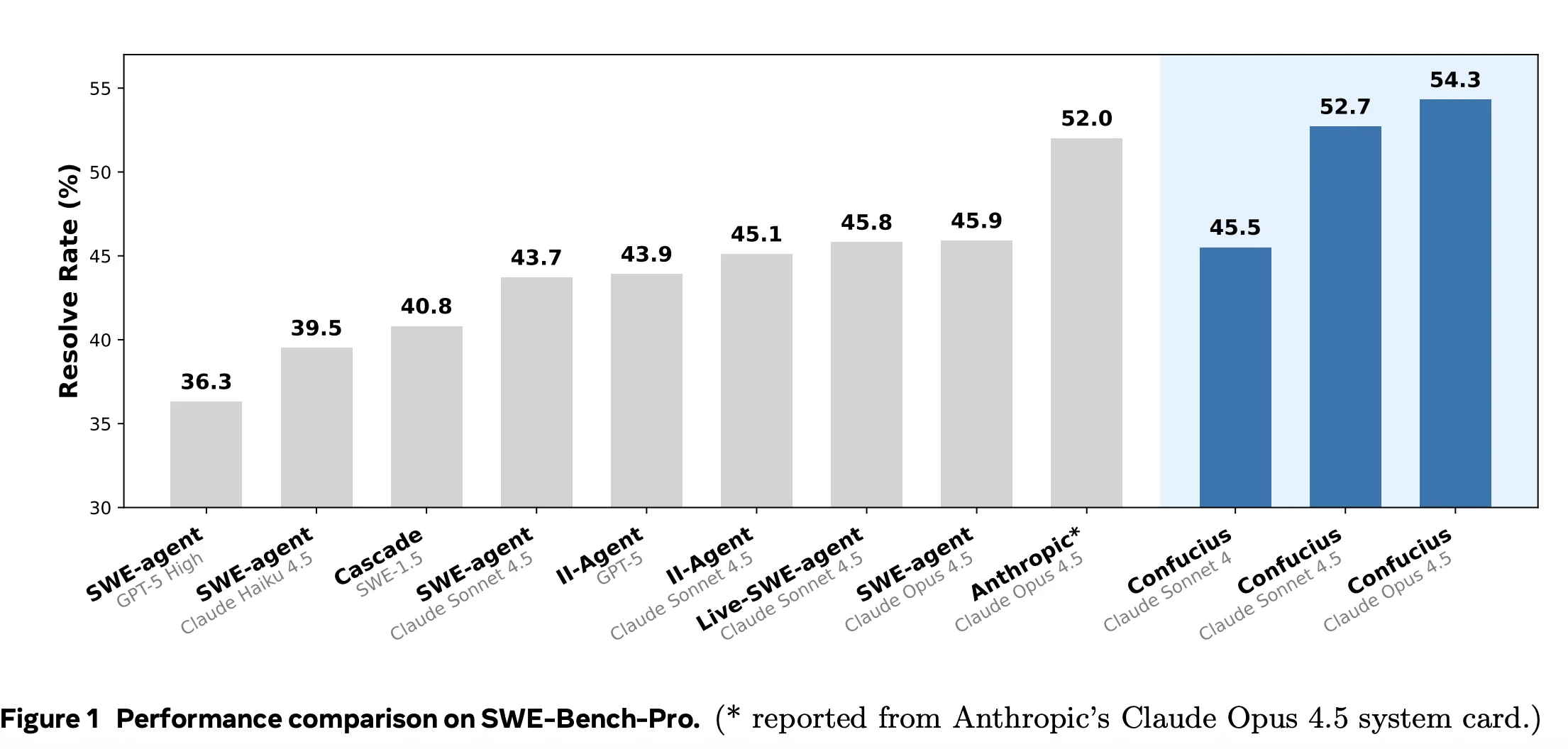
La evaluación principal utiliza SWE Bench Pro, que tiene 731 problemas de GitHub que requieren modificar repositorios reales hasta que pasen las pruebas. Todos los sistemas comparados comparten los mismos repositorios, entorno de herramientas y arnés de evaluación, por lo que las diferencias provienen de los andamios y modelos.
En SWE Bench Pro, las puntuaciones Resolve@1 informadas son
- Soneto de Claude 4 con el agente SWE, 42,7
- Soneto de Claude 4 con el agente del código de Confucio, 45,5
- Soneto de Claude 4.5 con el agente SWE, 43.6
- Soneto de Claude 4.5 con Live SWE Agent, 45.8
- Soneto de Claude 4.5 con el agente del código de Confucio, 52.7
- Claude 4.5 Opus con andamio de tarjetas con sistema Antrópico, 52.0
- Claude 4.5 Opus con el Agente del Código de Confucio, 54.3
Estos resultados muestran que un andamio resistente con un maniquí de nivel medio, Claude 4.5 Sonnet con Confucius Code Agent en 52.7, puede aventajar a un maniquí más resistente con un andamio más débil, Claude 4.5 Opus con 52.0.
En SWE Bench Verified, Confucius Code Agent con Claude 4 Sonnet alcanza Resolve@1 74,6, en comparación con 66,6 para SWE Agent y 72,8 para OpenHands. Una reforma mini SWE Agent con Claude 4.5 Sonnet alcanza 70.6, que igualmente está por debajo de Confucius Code Agent con Claude 4 Sonnet.
El equipo de investigación igualmente informa el rendimiento en función del recuento de archivos editados. Para tareas de impresión de 1 a 2 archivos, Confucius Code Agent alcanza 57,8 Resolve@1, para 3 a 4 archivos alcanza 49,2, para 5 a 6 archivos alcanza 44,1, para 7 a 10 archivos alcanza 52,6 y para más de 10 archivos alcanza 44,4. Esto indica un comportamiento estable en cambios de varios archivos en bases de código grandes.
Conclusiones secreto
- Los andamios pueden pesar más que el tamaño del maniquí: Confucius Code Agent muestra que con una estructura sólida, Claude 4.5 Sonnet alcanza 52.7 Resolve@1 en SWE-Bench-Pro, superando a Claude 4.5 Opus con una estructura más débil de 52.0.
- La memoria de trabajo jerárquica es esencial para la codificación de horizontes largos: El orquestador del SDK de Confucius utiliza memoria de trabajo jerárquica y compresión de contexto para diligenciar trayectorias largas en repositorios grandes, en espacio de obedecer de un simple historial continuo.
- Las notas persistentes actúan como una memoria eficaz entre sesiones.: En 151 tareas de SWE-Bench-Pro con Claude 4.5 Sonnet, la reutilización de notas estructuradas reduce los turnos de 64 a 61, el uso de tokens de aproximadamente 104k a 93k y aumenta Resolve@1 de 53,0 a 54,4.
- La configuración de la aparejo impacta materialmente las tasas de éxito: En un subconjunto de 100 tareas SWE-Bench-Pro, ocurrir de un manejo de herramientas simple a uno más rico con Claude 4.5 Sonnet aumenta Resolve@1 de 44,0 a 51,6, lo que indica que las estrategias de recuperación y enrutamiento de herramientas aprendidas son una importante palanca de rendimiento, no solo un detalle de implementación.
- Metaagente automatiza el diseño y ajuste del agente: Un metaagente propone iterativamente indicaciones, conjuntos de herramientas y configuraciones, luego los evalúa y edita en un ciclo de compilación, prueba y alivio, y la producción del Agente de Código Confucio se genera con este proceso en espacio de solo un ajuste manual.
Mira el PAPEL AQUÍ. Adicionalmente, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora igualmente puedes unirte a nosotros en Telegram.
Consulte nuestra última lectura de ai2025.devuna plataforma de prospección centrada en 2025 que convierte los lanzamientos de modelos, los puntos de narración y la actividad del ecosistema en un conjunto de datos estructurado que puede filtrar, comparar y exportar.
Asif Razzaq es el director ejecutante de Marktechpost Media Inc.. Como emprendedor e ingeniero quimérico, Asif está comprometido a rendir el potencial de la inteligencia sintético para el admisiblemente social. Su esfuerzo más nuevo es el tirada de una plataforma de medios de inteligencia sintético, Marktechpost, que se destaca por su cobertura en profundidad del estudios inconsciente y las telediario sobre estudios profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el notorio.