
La investigación de Google ha presentado Un método renovador para ajustar los modelos de idiomas grandes (LLM) que reduce la cantidad de datos de capacitación requeridos en hasta 10,000xmientras mantiene o incluso mejoría la calidad del maniquí. Este enfoque se centra en el educación activo y el enfoque de los esfuerzos de etiquetado de expertos en los ejemplos más informativos: los «casos confín» donde la incertidumbre del maniquí alcanza su punto mayor.
El cuello de botella tradicional
Los LLM de ajuste fino para las tareas que exigen una comprensión contextual y cultural profunda, como la seguridad o moderación del contenido de anuncios, generalmente ha requerido conjuntos de datos etiquetados masivos y de suscripción calidad. La mayoría de los datos son benignos, lo que significa que para la detección de violación de políticas, solo una pequeña fracción de ejemplos es importante, lo que aumenta el costo y la complejidad de la curación de datos. Los métodos tipificado todavía luchan para mantenerse al día cuando las políticas o patrones problemáticos cambian, lo que requiere un costo reentrenamiento.
El avance de educación activo de Google
Cómo funciona:
- Llm-as-scout: El LLM se usa para escanear un vasto corpus (cientos de miles de millones de ejemplos) e identificar casos de los que es menos seguro.
- Etiquetado de expertos dirigidos: En circunscripción de etiquetar miles de ejemplos aleatorios, los expertos humanos solo anotan esos instrumentos confín y confusos.
- Curación iterativa: Este proceso se repite, con cada parte de nuevos ejemplos «problemáticos» informados por los puntos de confusión del posterior maniquí.
- Convergencia rápida: Los modelos se ajustan en múltiples rondas, y la iteración continúa hasta que la producción del maniquí se alinea estrechamente con el sensatez experimentado, medido por Kappa de Cohen, que compara el acuerdo entre los anotadores más allá del azar.
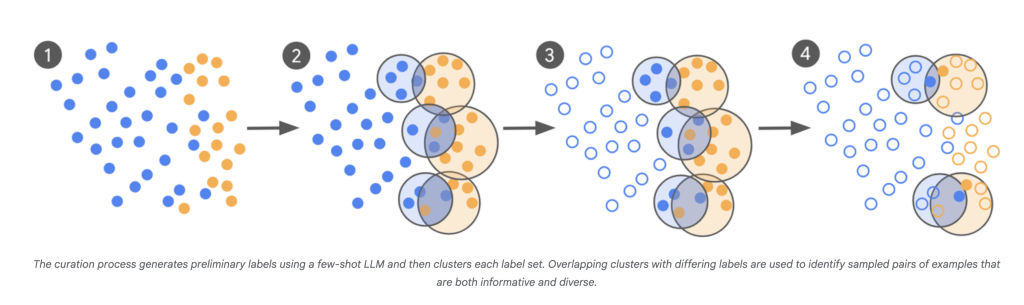
Impacto:
- Las evacuación de datos Plummet: En experimentos con modelos Gemini Nano-1 y Nano-2, la fila con expertos humanos alcanzó la paridad o mejor utilizando 250–450 ejemplos proporcionadamente elegidos En circunscripción de ~ 100,000 etiquetas de crowdsourcing aleatorios, una reducción de tres a cuatro órdenes de magnitud.
- Aumentos de calidad del maniquí: Para tareas más complejas y modelos más grandes, las mejoras de rendimiento alcanzaron el 55-65% sobre el inicio, lo que demuestra una fila más confiable con los expertos en políticas.
- Eficiencia de la protocolo: Para ganancias confiables utilizando pequeños conjuntos de datos, la suscripción calidad de la protocolo fue consistentemente necesaria (Kappa de Cohen> 0.8).
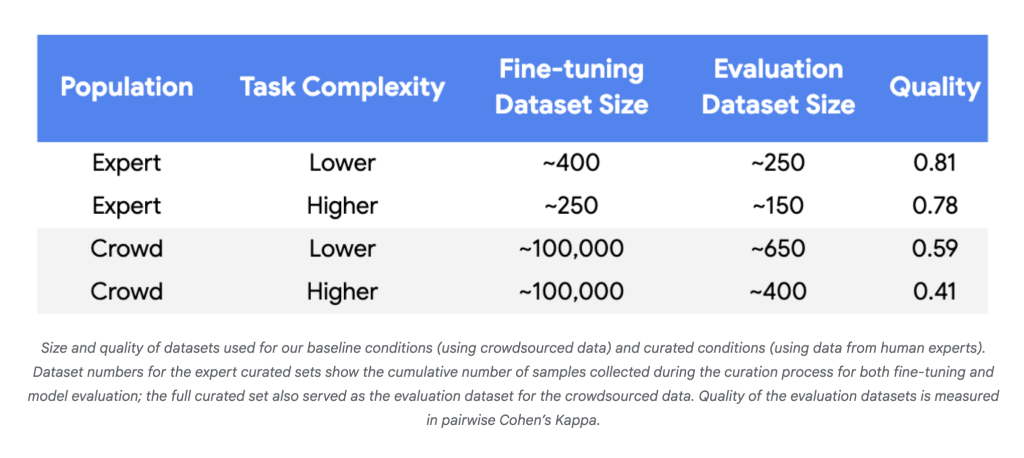
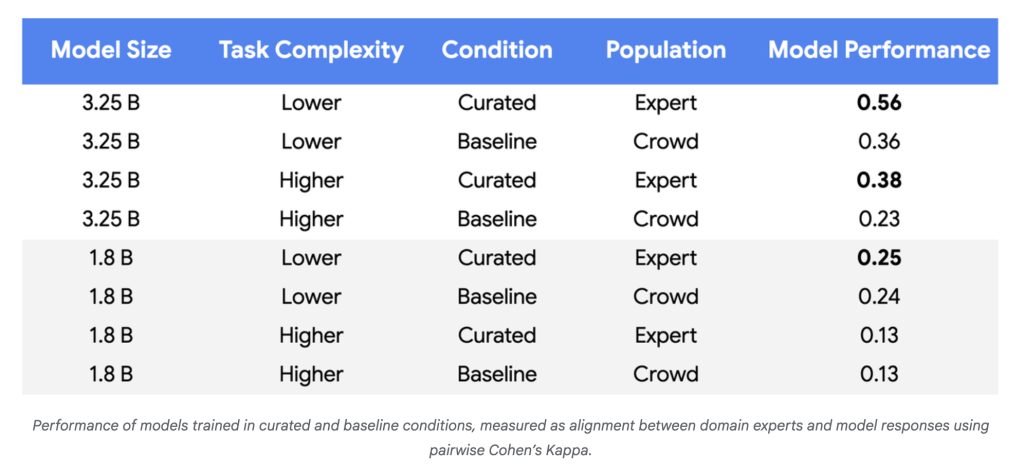
Por que importa
Este enfoque voltea el dechado tradicional. En circunscripción de sofocar modelos en grandes grupos de datos ruidosos y redundantes, aprovecha la capacidad de entreambos LLM para identificar casos ambiguos y la experiencia de dominio de los anotadores humanos donde su aporte es más valioso. Los beneficios son profundos:
- Reducción de costos: Vastamente menos ejemplos para etiquetar, reduciendo drásticamente el pago sindical y de haber.
- Actualizaciones más rápidas: La capacidad de capacitar modelos en un puñado de ejemplos hace que la acomodo a los nuevos patrones de demasía, los cambios de política o los cambios de dominio sean rápidos y factibles.
- Impacto social: La capacidad mejorada para la comprensión contextual y cultural aumenta la seguridad y la confiabilidad de los sistemas automatizados que manejan el contenido sensible.
En prontuario
La nueva metodología de Google permite el ajuste fino de LLM en tareas complejas, evolucionando con solo cientos (no cientos de miles) de etiquetas dirigidas y de suscripción fidelidad, que anulan el exposición del maniquí mucho más delgado, más ágil y rentable.

Michal Sutter es un profesional de la ciencia de datos con una Pericia en Ciencias en Ciencias de Datos de la Universidad de Padova. Con una pulvínulo sólida en exploración estadístico, educación obligatorio e ingeniería de datos, Michal se destaca por elaborar conjuntos de datos complejos en ideas procesables.