
Esta publicación está coescrita por David Stewart y Matthew Persons de Oumi.
El ajuste de los modelos de lenguajes grandes (LLM) de código franco a menudo se estanca entre la experimentación y la producción. Las configuraciones de capacitación, la mandato de artefactos y la implementación escalable requieren herramientas diferentes, lo que crea fricciones al acontecer de una experimentación rápida a entornos seguros de nivel empresarial.
En esta publicación, mostramos cómo ajustar un maniquí de Fogosidad usando Oumi en Amazon EC2 (con la opción de crear datos sintéticos usando Oumi), juntar artefactos en amazon s3y desplegar en Roca Amazónica usando Importación de maniquí personalizado para inferencia gestionada. Si acertadamente usamos EC2 en este tutorial, se pueden realizar ajustes en otros servicios informáticos, como Amazon SageMaker o Servicio Amazon Elastic Kubernetesdependiendo de tus evacuación.
Beneficios de Oumi y Amazon Bedrock
Oumi es un sistema de código franco que agiliza el ciclo de vida del maniquí elemental, desde la preparación de datos y la capacitación hasta la evaluación. En ocupación de ensamblar herramientas separadas para cada etapa, usted define una configuración única y la reutiliza en todas las ejecuciones.
Beneficios secreto para este flujo de trabajo:
- Entrenamiento basado en recetas: Defina su configuración una vez y reutilícela en todos los experimentos, reduciendo el texto repetitivo y mejorando la reproducibilidad.
- Ajuste flexible: Elija métodos completos de ajuste fino o eficientes en parámetros como lorasegún tus limitaciones
- Evaluación integrada: Califique puntos de control utilizando puntos de remisión o LLM como mediador sin herramientas adicionales
- Síntesis de datos: Genere conjuntos de datos específicos de tareas cuando los datos de producción sean limitados
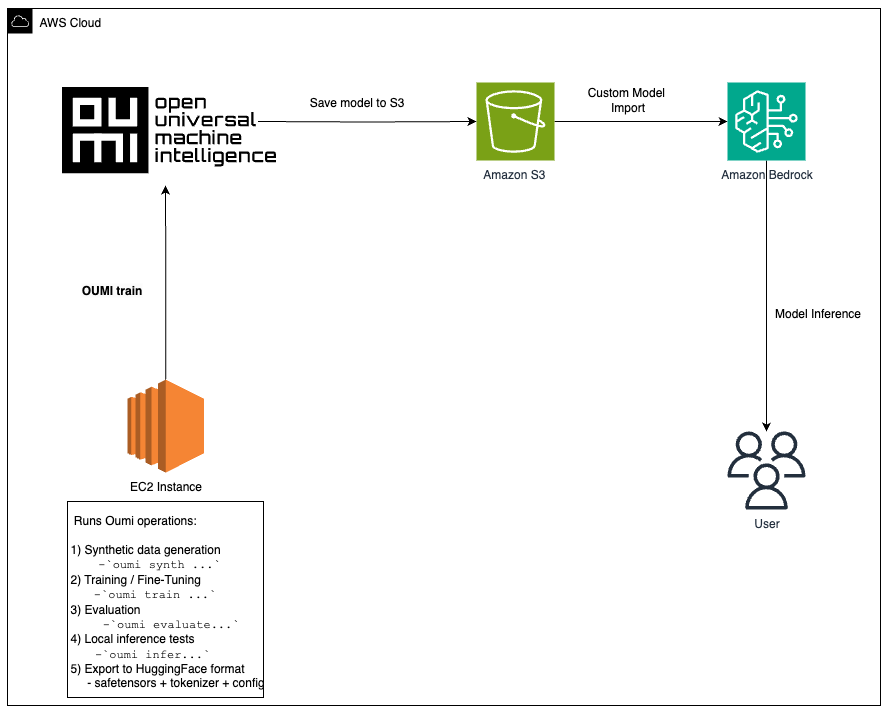
Amazon Bedrock complementa esto proporcionando inferencia administrada y sin servidor. Posteriormente de realizar ajustes con Oumi, importas tu maniquí a través de Importación de maniquí personalizado en tres pasos: cargarlo en S3, crear el trabajo de importación e invocarlo. No hay infraestructura de inferencia que encargar. El ulterior diagrama de inmueble muestra cómo estos componentes funcionan juntos.
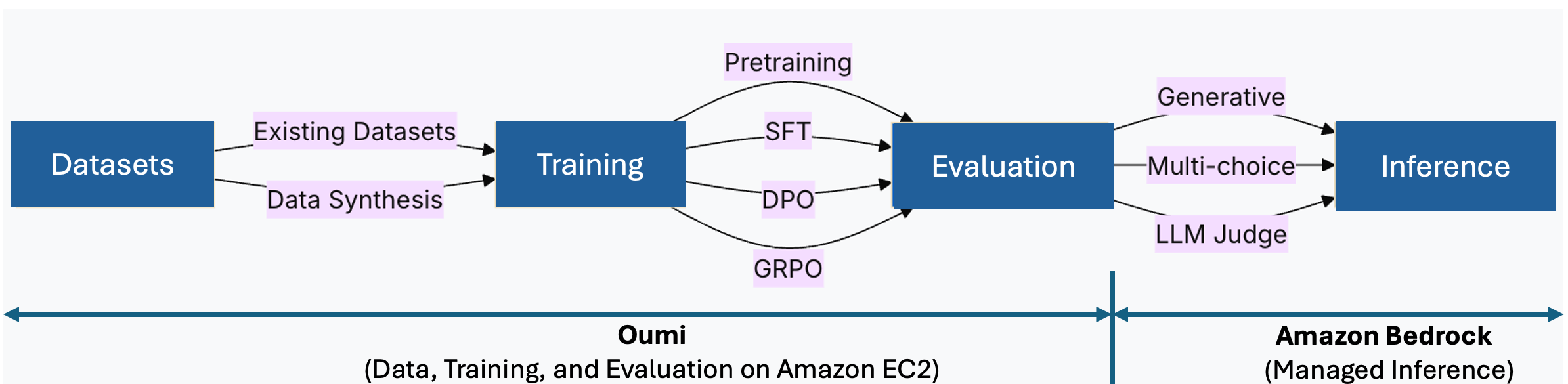
Figura 1: Oumi gestiona datos, capacitación y evaluación en EC2. Amazon Bedrock proporciona inferencia administrada mediante la importación de modelos personalizados.
Descripción normal de la decisión
Este flujo de trabajo consta de tres etapas:
- Afinar con Oumi en EC2: Inicie una instancia optimizada para GPU (por ejemplo, g5.12xlarge o p4d.24xlarge), instalar Oumiy ejecute el entrenamiento con su configuración. Para modelos más grandes, Oumi admite el entrenamiento distribuido con estrategias de datos paralelos totalmente fragmentados (FSDP), DeepSpeed y datos distribuidos paralelos (DDP) en configuraciones de múltiples GPU o múltiples nodos.
- Juntar artefactos en S3: Cargue pesos de modelos, puntos de control y registros para un almacenamiento duradero.
- Implementación en Amazon Bedrock: Crear un Trabajo de importación de maniquí personalizado apuntando a sus artefactos S3. Amazon Bedrock proporciona infraestructura de inferencia automáticamente. Las aplicaciones cliente llaman al maniquí importado usando el API de tiempo de ejecución de Amazon Bedrock.
Esta inmueble aborda desafíos comunes al acontecer modelos ajustados a producción:
Implementación técnica
Repasemos un flujo de trabajo práctico utilizando el meta-llama/Fogosidad-3.2-1B-Instruir maniquí como ejemplo. Si acertadamente seleccionamos este maniquí porque combina acertadamente con el ajuste fino en un AWS g6.12xlarge En la instancia EC2, el mismo flujo de trabajo se puede replicar en muchos otros modelos de código franco (tenga en cuenta que los modelos más grandes pueden requerir instancias más grandes o capacitación distribuida entre instancias). Para obtener más información, consulte la Recetas de ajuste del maniquí Oumi y Arquitecturas de modelos personalizados de Amazon Bedrock.
Requisitos previos
Para completar este tutorial, necesita:
Configurar fortuna de AWS
- Clona este repositorio en tu máquina restringido:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- Ejecute el script de configuración para crear roles de IAM, un depósito S3 y divulgar una instancia EC2 optimizada para GPU:
./scripts/setup-aws-env.sh (--dry-run)El script solicita su región de AWS, el nombre del depósito S3, el nombre del par de claves EC2 y el ID del rama de seguridad y luego crea todos los fortuna necesarios. Títulos predeterminados: instancia g6.12xlarge, AMI colchoneta de educación profundo con CUDA única (Amazon Linux 2023) y 100 GB de almacenamiento gp3. Nota: Si no tiene permisos para crear roles de IAM o iniciar instancias EC2, comparta este repositorio con su administrador de TI y pídale que complete esta sección para configurar su entorno de AWS.
- Una vez que la instancia se está ejecutando, el script genera el comando SSH y el ARN del rol de importación de Amazon Bedrock (necesario en el paso 5). SSH en la instancia y continúe con el Paso 1 a continuación.
Ver el iam/README.md para obtener detalles de la política de IAM, orientación sobre el valor y pasos de subsistencia.
Paso 1: configurar el entorno EC2
Complete los siguientes pasos para configurar el entorno EC2.
- En la instancia EC2 (Amazon Linux 2023), actualice el sistema e instale las dependencias básicas:
sudo yum update -y
sudo yum install python3 python3-pip git -y- Clona el repositorio complementario:
git clone https://github.com/aws-samples/sample-oumi-fine-tuning-bedrock-cmi.git
cd sample-oumi-fine-tuning-bedrock-cmi- Configure las variables de entorno (reemplace los títulos con su región verdadero y el nombre del depósito del script de configuración):
export AWS_REGION=us-west-2
export S3_BUCKET=your-bucket-name
export S3_PREFIX=your-s3-prefix
aws configure set default.region "$AWS_REGION"- Ejecute el script de configuración para crear un entorno imaginario Python, instale Oumi, valide la disponibilidad de la GPU y configure la autenticación Hugging Face. Ver configuración-entorno.sh para opciones.
./scripts/setup-environment.sh
source .venv/bin/activate- Autentíquese con Hugging Face para conseguir a los pesos de los modelos cerrados. Producir un token de entrada en huggingface.co/settings/tokensluego ejecuta:
hf auth loginPaso 2: configurar el entrenamiento
El conjunto de datos predeterminado es tatsu-laboratorio/alpacaconfigurado en configs/oumi-config.yaml. Oumi lo descarga automáticamente durante el entrenamiento, no es necesaria ninguna descarga manual. Para utilizar un conjunto de datos diferente, actualice el dataset_name parámetro en configs/oumi-config.yaml. Ver el Documentos del conjunto de datos de Oumi para formatos compatibles.
(Opcional) Genera datos de entrenamiento sintéticos con Oumi:
Para gestar datos sintéticos utilizando Amazon Bedrock como backend de inferencia, actualice la model_name registrador de posición en configs/síntesis-config.yaml con un ID de maniquí de Amazon Bedrock al que tiene entrada (p. ej. anthropic.claude-sonnet-4-6). Ver Documentos de síntesis de datos de Oumi para más detalles. Luego ejecuta:
oumi synth -c configs/synthesis-config.yamlPaso 3: afina el maniquí
Afina el maniquí utilizando el entrenamiento integrado de Oumi prescripción para Fogosidad-3.2-1B-Instrucción:
./scripts/fine-tune.sh --config configs/oumi-config.yaml --output-dir models/final (--dry-run)Para personalizar los hiperparámetros, edite oumi-config.yaml.
Nota: Si generó datos sintéticos en el Paso 2, actualice la ruta del conjunto de datos en la configuración antaño del entrenamiento.
Supervise la utilización de la GPU con nvidia-smi o Agente de Amazon CloudWatch. Para trabajos de larga duración, configure Recuperación cibernética de instancias de Amazon EC2 para manejar interrupciones de instancia.
Paso 4: Evaluar el maniquí (opcional)
Puede evaluar el maniquí adecuado utilizando puntos de remisión estereotipado:
oumi evaluate -c configs/evaluation-config.yamlLa configuración de evaluación especifica la ruta del maniquí y las tareas de remisión (por ejemplo, MMLU). Para personalizar, editar evaluación-config.yaml. Para conocer enfoques de LLM como mediador y puntos de remisión adicionales, consulte Oumi’s consejero de evaluación.
Paso 5: Implementación en Amazon Bedrock
Complete los siguientes pasos para implementar el maniquí en Amazon Bedrock:
- Cargue los artefactos del maniquí a S3 e valor el maniquí a Amazon Bedrock.
./scripts/upload-to-s3.sh --bucket $S3_BUCKET --source models/final --prefix $S3_PREFIX
./scripts/import-to-bedrock.sh --model-name my-fine-tuned-llama --s3-uri s3://$S3_BUCKET/$S3_PREFIX --role-arn $BEDROCK_ROLE_ARN --wait- El script de importación genera el ARN del maniquí al finalizar. Colocar
MODEL_ARNa este valía (formato:arn:aws:bedrock:).: :imported-model/ - Invocar el maniquí en Amazon Bedrock
./scripts/invoke-model.sh --model-id $MODEL_ARN --prompt "Translate this text to French: What is the haber of France?"- Amazon Bedrock crea automáticamente un entorno de inferencia administrado. Para configurar el rol de IAM, consulte bedrock-import-role.json.
- Habilitar S3 versionando en el depósito para aprobar la reversión de las revisiones del maniquí. Para el secreto SSE-KMS y el refuerzo de políticas de depósitos, consulte la scripts de seguridad en el repositorio complementario.
Paso 6: extirpar
Para evitar costos continuos, elimine los fortuna creados durante este tutorial:
aws ec2 terminate-instances --instance-ids $INSTANCE_ID
aws s3 rm s3://$S3_BUCKET/$S3_PREFIX/ --recursive
aws bedrock delete-imported-model --model-identifier $MODEL_ARNConclusión
En esta publicación, aprendió cómo ajustar un maniquí colchoneta Fogosidad-3.2-1B-Instruct usando Oumi en EC2 e implementarlo usando Amazon Bedrock Custom Model Import. Este enfoque le brinda control total sobre el ajuste de sus propios datos mientras utiliza la inferencia administrada en Amazon Bedrock.
el compañero muestra-oumi-ajuste-fino-bedrock-cmi El repositorio proporciona scripts, configuraciones y políticas de IAM para comenzar. Clónelo, intercambie su conjunto de datos e implemente un maniquí personalizado en Amazon Bedrock.
Para comenzar, explore los fortuna a continuación y comience a crear su propio proceso de ajuste hasta la implementación en Oumi y AWS. ¡Atinado edificio!
Más información
Examen
Un agradecimiento peculiar a Pronoy Chopra y Jon Turdiev por su contribución.
Sobre los autores