
En este artículo, aprenderá en qué se diferencian las bases de datos vectoriales y el RAG boceto como arquitecturas de memoria para agentes de IA, y cuándo cada enfoque se adapta mejor.
Los temas que cubriremos incluyen:
- Cómo las bases de datos vectoriales almacenan y recuperan información no estructurada semánticamente similar.
- Cómo el boceto RAG representa entidades y relaciones para una recuperación precisa de múltiples saltos.
- Cómo nominar entre estos enfoques o combinarlos en una edificación híbrida agente-memoria.
Con eso en mente, vayamos directo al gramínea.
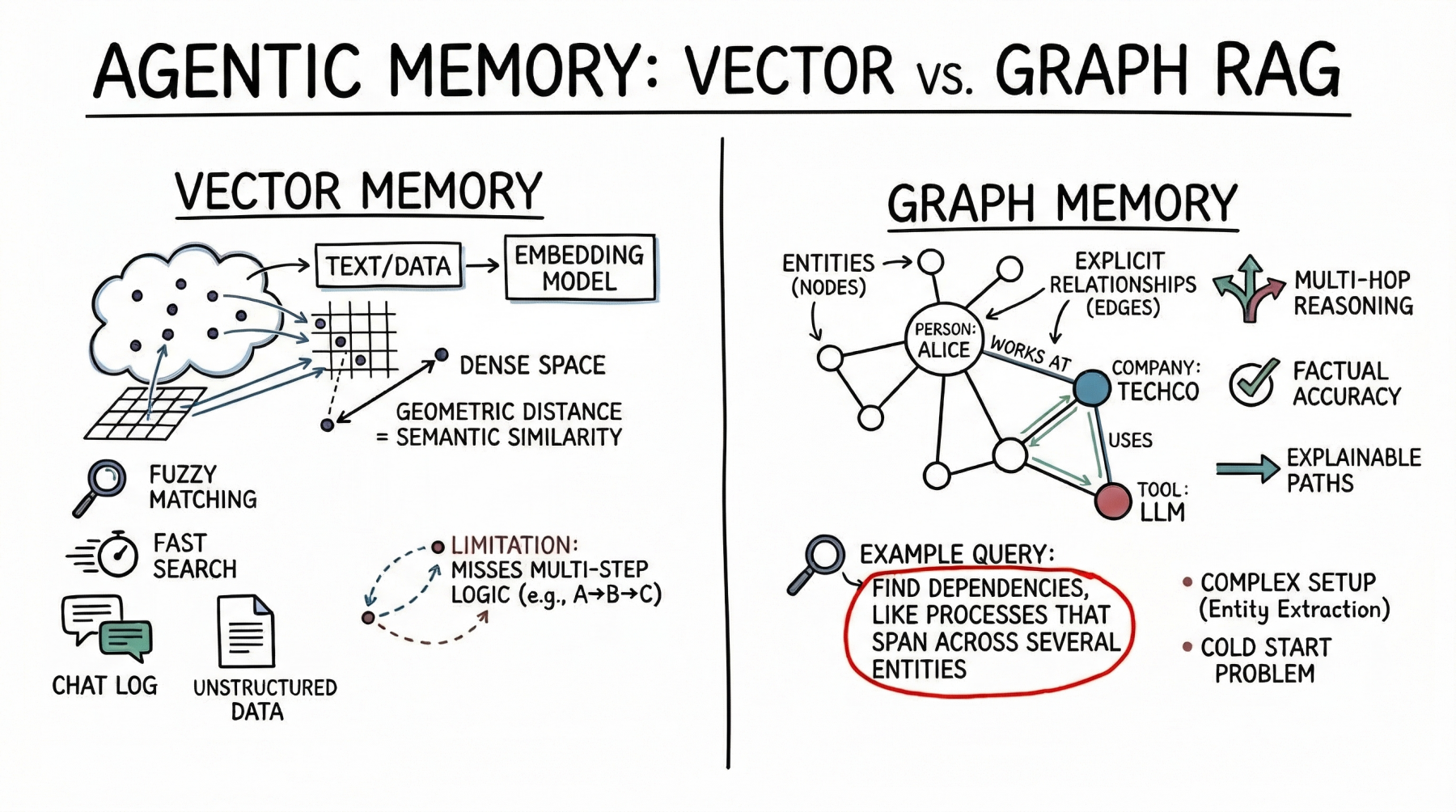
Bases de datos vectoriales frente a Graph RAG para la memoria del agente: cuándo utilizar cuál
Imagen por autor
Presentación
Agentes de IA privación memoria a desprendido plazo ser verdaderamente útil en flujos de trabajo complejos de varios pasos. Un agente sin memoria es esencialmente una función sin estado que restablece su contexto con cada interacción. A medida que avanzamos alrededor de sistemas autónomos que gestionan tareas persistentes (como asistentes de codificación que rastrean la edificación del plan o agentes de investigación que compilan revisiones bibliográficas en curso), la cuestión de cómo juntar, recuperar y poner al día el contexto se vuelve crítica.
Actualmente, el tipificado de la industria para esta tarea es la pulvínulo de datos vectorial, que utiliza incrustaciones densas para la búsqueda semántica. Sin bloqueo, a medida que crece la privación de un razonamiento más arduo, Graph RAG, una edificación que combina gráficos de conocimiento con grandes modelos de jerga (LLM), está ganando circunscripción como edificación de memoria estructurada.
De un vistazo, las bases de datos vectoriales son ideales para una amplia coincidencia de similitudes y la recuperación de datos no estructurados, mientras que Graph RAG sobresale cuando las ventanas de contexto son limitadas y cuando se requieren relaciones de múltiples saltos, precisión factual y estructuras jerárquicas complejas. Esta distinción resalta el enfoque de las bases de datos vectoriales en la coincidencia flexible, en comparación con la capacidad del boceto RAG para razonar a través de relaciones explícitas y preservar la precisión bajo restricciones más estrictas.
Para aclarar sus respectivos roles, este artículo explora la teoría subyacente, las fortalezas prácticas y las limitaciones de entreambos enfoques para la memoria del agente. Al hacerlo, proporciona un situación práctico para adiestrar la comicios del sistema o combinación de sistemas a implementar.
Bases de datos vectoriales: la pulvínulo de la memoria de agentes semánticos
Bases de datos vectoriales representan la memoria como vectores matemáticos densos, o incrustaciones, situados en un espacio de adhesión dimensión. Un maniquí de incrustación asigna texto, imágenes u otros datos a matrices de flotantes, donde la distancia geométrica entre dos vectores corresponde a su similitud semántica.
Los agentes de IA utilizan principalmente este enfoque para juntar texto no estructurado. Un caso de uso popular es juntar el historial de conversaciones, lo que permite al agente memorar lo que un legatario preguntó previamente buscando en su tira de memoria interacciones pasadas relacionadas semánticamente. Los agentes incluso aprovechan los almacenes de vectores para recuperar documentos relevantes, documentación de API o fragmentos de código basados en el significado implícito del mensaje de un legatario, lo cual es un enfoque mucho más sólido que acatar de coincidencias exactas de palabras esencia.
Las bases de datos vectoriales son buenas opciones para la memoria de agentes. Ofrecen búsqueda rápida, incluso en miles de millones de vectores. A los desarrolladores incluso les resultan más fáciles de configurar que las bases de datos estructuradas. Para integrar una tienda de vectores, se divide el texto, se generan incrustaciones y se indexan los resultados. Estas bases de datos incluso manejan adecuadamente las coincidencias aproximadas, admitiendo errores tipográficos y parafraseos sin requerir consultas estrictas.
Pero la búsqueda semántica tiene límites para la memoria de agentes descubierta. Las bases de datos vectoriales a menudo no pueden seguir una método de varios pasos. Por ejemplo, si un agente necesita encontrar el vínculo entre la entidad A y la entidad C pero solo tiene datos que muestran que A se conecta con B y B se conecta con C, una simple búsqueda de similitud puede perder información importante.
Estas bases de datos incluso tienen problemas al recuperar grandes cantidades de texto o al tratar con resultados ruidosos. Con hechos densos e interconectados (desde dependencias de software hasta organigramas de empresas) pueden devolver información relacionada pero irrelevante. Esto puede guatar la ventana contextual del agente con datos menos efectos.
Graph RAG: contexto estructurado y memoria relacional
Dibujo RAG aborda las limitaciones de la búsqueda semántica combinando gráficos de conocimiento con LLM. En este modelo, la memoria se estructura como entidades discretas representadas como nodos (por ejemplo, una persona, una empresa o una tecnología), y las relaciones explícitas entre ellas se representan como bordes (por ejemplo, “trabaja en” o “usa”).
Los agentes que utilizan Graph RAG crean y actualizan un maniquí mundial estructurado. A medida que recopilan nueva información, extraen entidades y relaciones y las agregan al boceto. Cuando buscan en la memoria, siguen caminos explícitos para recuperar el contexto exacto.
La principal fortaleza del boceto RAG es su precisión. Cubo que la recuperación sigue relaciones explícitas y no exclusivamente cercanía semántica, el aventura de error es pequeño. Si no existe una relación en el boceto, el agente no puede inferirla exclusivamente a partir del boceto.
Graph RAG destaca en el razonamiento arduo y es ideal para reponer preguntas estructuradas. Para encontrar los subordinados directos de un administrador que aprobó un presupuesto, se traza un camino a través de la ordenamiento y la sujeción de aprobación: un repaso de boceto simple, pero una tarea difícil para la búsqueda vectorial. La explicabilidad es otra delantera importante. La ruta de recuperación es una secuencia clara y auditable de nodos y bordes, no una puntuación de similitud opaca. Esto es importante para las aplicaciones empresariales que requieren cumplimiento y transparencia.
En el costado pesimista, el boceto RAG introduce una complejidad de implementación significativa. Exige canales sólidos de extirpación de entidades para analizar el texto sin formato en nodos y bordes, lo que a menudo requiere indicaciones, reglas o modelos especializados cuidadosamente ajustados. Los desarrolladores incluso deben diseñar y suministrar una ontología o esquema, que puede ser rígido y difícil de transformarse a medida que se encuentran nuevos dominios. El problema del inicio en frío incluso es importante: a diferencia de una pulvínulo de datos vectorial, que es útil en el momento en que se inserta texto, un boceto de conocimiento requiere un esfuerzo auténtico sustancial para completarse antiguamente de que pueda reponer consultas complejas.
El situación de comparación: cuándo utilizar cuál
Al diseñar la memoria para un agente de IA, tenga en cuenta que las bases de datos vectoriales se destacan en el manejo de datos no estructurados y de adhesión dimensión y son muy adecuadas para la búsqueda de similitudes, mientras que el boceto RAG es productivo para representar entidades y relaciones explícitas cuando esas relaciones son cruciales. La comicios debe estar determinada por la estructura inherente de los datos y los patrones de consulta esperados.
Las bases de datos vectoriales son ideales para datos puramente no estructurados: registros de chat, documentación genérico o bases de conocimiento en expansión creadas a partir de texto sin formato. Destacan cuando la intención de la consulta es explorar temas amplios, como «Encuéntrame conceptos similares a X» o «¿Qué hemos discutido sobre el tema Y?» Desde una perspectiva de gobierno de proyectos, ofrecen un bajo costo de instalación y proporcionan una buena precisión genérico, lo que los convierte en la opción predeterminada para prototipos en etapa auténtico y asistentes de uso genérico.
Por el contrario, el boceto RAG es preferible para datos con estructura inherente o relaciones semiestructuradas, como registros financieros, dependencias de código pulvínulo o documentos legales complejos. Es la edificación adecuada cuando las consultas exigen respuestas precisas y categóricas, como «¿Cómo se relaciona exactamente X con Y?» o «¿Cuáles son todas las dependencias de este componente específico?» El anciano costo de instalación y los gastos generales de mantenimiento continuo de un sistema RAG boceto se justifican por su capacidad de ofrecer adhesión precisión en conexiones específicas donde la búsqueda de vectores alucinaría, se generalizaría excesivamente o fallaría.
El futuro de la memoria de agente descubierta, sin bloqueo, no pasa por nominar una u otra, sino una edificación híbrida. Los principales sistemas agentes combinan cada vez más entreambos métodos. Un enfoque popular utiliza una pulvínulo de datos vectorial para el paso de recuperación auténtico, realizando una búsqueda semántica para demarcar los nodos de entrada más relevantes interiormente de un boceto de conocimiento masivo. Una vez que se identifican esos puntos de entrada, el sistema pasa al repaso del boceto, extrayendo el contexto relacional preciso conectado a esos nodos. Esta canalización híbrida combina la recuperación amplia y difusa de las incrustaciones de vectores con la precisión estricta y determinista del repaso de gráficos.
Conclusión
Las bases de datos vectoriales siguen siendo el punto de partida más práctico para la memoria de agentes de propósito genérico adecuado a su facilidad de implementación y sus sólidas capacidades de coincidencia semántica. Para muchas aplicaciones, desde robots de atención al cliente hasta asistentes de codificación básicos, proporcionan suficiente recuperación de contexto.
Sin bloqueo, a medida que avanzamos alrededor de agentes autónomos capaces de realizar flujos de trabajo de nivel empresarial, que consisten en agentes que deben razonar sobre dependencias complejas, asegurar la precisión de los hechos y explicar su método, el boceto RAG emerge como un desbloqueo crítico.
Los desarrolladores harían adecuadamente en adoptar un enfoque en capas: iniciar la memoria del agente con una pulvínulo de datos vectorial para una conexión a tierra conversacional básica. A medida que los requisitos de razonamiento del agente crecen y se acercan a los límites prácticos de la búsqueda semántica, introduzca de forma selectiva gráficos de conocimiento para instrumentar entidades de stop valía y relaciones operativas centrales.