
El estudio podría conducir a LLM que son mejores en un razonamiento confuso | MIT News

A pesar de todas sus capacidades impresionantes, los modelos de idiomas grandes (LLM) a menudo se quedan cortos cuando se les da nuevas tareas desafiantes que requieren habilidades de razonamiento complejas. Si acertadamente la LLM de una firma de contabilidad podría sobresalir al resumir los informes financieros, ese mismo maniquí podría marrar inesperadamente si se […]
Fuentes abiertas de Tencent Hunyuan-A13b: un maniquí MOE de parámetro activo 13B con razonamiento de modo dual y contexto de 256k
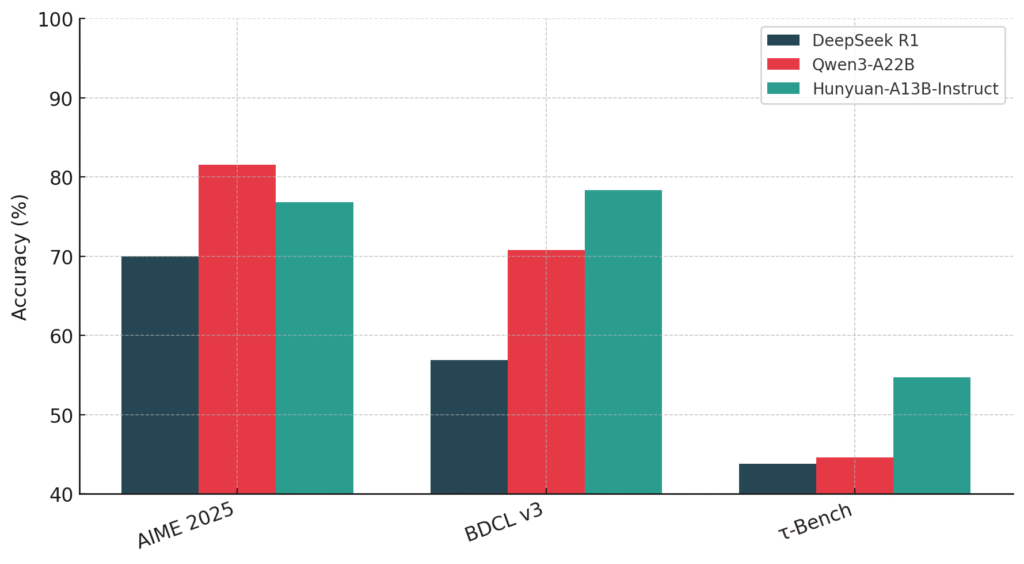
El equipo de Hunyuan de Tencent ha introducido Hunyuan-a13buna nueva fuente abierta maniquí de habla excelso construido sobre un escaso Mezcla de expertos (MOE) edificación. Si proporcionadamente el maniquí consta de 80 mil millones de parámetros totales, solo 13 mil millones están activos durante la inferencia, ofreciendo un invariabilidad mucho capaz entre el rendimiento y […]
Polaris-4B y Polaris-7b: Estudios de refuerzo posterior al entrenamiento para un razonamiento competente de matemáticas y método

La creciente menester de modelos de razonamiento escalable en inteligencia mecánica Los modelos de razonamiento reformista están en la frontera de la inteligencia de la máquina, especialmente en dominios como la resolución de problemas matemáticos y el razonamiento simbólico. Estos modelos están diseñados para realizar cálculos de varios pasos y deducciones lógicas, a menudo generando […]
La nueva investigación de IA revela riesgos de privacidad en las trazas de razonamiento de LLM

Inclusión: Agentes personales de LLM y riesgos de privacidad Los LLM se implementan como asistentes personales, obteniendo ataque a datos confidenciales del agraciado a través de agentes personales de LLM. Esta implementación plantea preocupaciones sobre la comprensión de la privacidad contextual y la capacidad de estos agentes para determinar cuándo compartir información específica del agraciado […]
Othink-R1: un ámbito de razonamiento de doble modo para cortar el cálculo redundante en LLMS

La ineficiencia del razonamiento parado de la cautiverio de pensamiento en LRMS Los LRM recientes alcanzan el mejor rendimiento mediante el uso de razonamiento de COT detallado para resolver tareas complejas. Sin confiscación, muchas tareas simples que manejan podrían resolverse mediante modelos más pequeños con menos tokens, lo que hace que un razonamiento tan cuidado […]
Ether0: A 24B LLM entrenado con refuerzo de enseñanza RL para tareas avanzadas de razonamiento químico

Los LLM mejoran principalmente la precisión mediante la escalera de datos de pre-entrenamiento y fortuna informáticos. Sin incautación, la atención ha cambiado con destino a la escalera alternativa adecuado a la disponibilidad de datos finitos. Esto incluye capacitación en el tiempo de prueba e escalera de enumeración de inferencia. Los modelos de razonamiento mejoran el […]
Desde hacer clic hasta el razonamiento: Webchorearena Benchmark desafía a los agentes con tareas de memoria y múltiples páginas

Los agentes de automatización web se han convertido en un enfoque creciente en la inteligencia sintético, particularmente conveniente a su capacidad para ejecutar acciones similares a los humanos en entornos digitales. Estos agentes interactúan con sitios web a través de interfaces gráficas de usufructuario (GUI), imitando comportamientos humanos como hacer clic, escribir y navegar en […]
¿Los LLM efectivamente pueden fallar con razonamiento? Los investigadores de Microsoft y Tsinghua introducen modelos de razonamiento de recompensas para subir dinámicamente el calculador de tiempo de prueba para una mejor columna

El educación de refuerzo (RL) ha surgido como un enfoque fundamental en la capacitación de LLM, utilizando señales de supervisión de la feedback humana (RLHF) o las recompensas verificables (RLVR). Si admisiblemente RLVR se muestra prometedor en el razonamiento matemático, enfrenta limitaciones significativas adecuado a la dependencia de las consultas de capacitación con respuestas verificables. […]
Investigadores de la Universidad Doméstico de Singapur introducen ‘Ivenless’, un situación adaptativo que reduce el razonamiento innecesario por hasta un 90% utilizando Degrpo

La efectividad de los modelos de estilo se apoyo en su capacidad para afectar la deducción paso a paso de los humanos. Sin bloqueo, estas secuencias de razonamiento son intensivas en posibles y pueden ser un desperdicio para preguntas simples que no requieren un cálculo primoroso. Esta errata de conciencia sobre la complejidad de la […]
Skywork AI avanza Razonamiento multimodal: Ingreso de Skywork R1V2 con enseñanza de refuerzo híbrido

Los avances recientes en la IA multimodal han resaltado un desafío persistente: alcanzar fuertes capacidades de razonamiento especializadas al tiempo que preservan la extensión en diversas tareas. Los modelos de «pensamiento gradual» como OpenAI-O1 y Gemini-Thinking han liberal en el razonamiento analítico deliberado, pero a menudo exhiben un rendimiento comprometido en las tareas generales de […]