
Skywork AI avanza Razonamiento multimodal: Ingreso de Skywork R1V2 con enseñanza de refuerzo híbrido

Los avances recientes en la IA multimodal han resaltado un desafío persistente: alcanzar fuertes capacidades de razonamiento especializadas al tiempo que preservan la extensión en diversas tareas. Los modelos de «pensamiento gradual» como OpenAI-O1 y Gemini-Thinking han liberal en el razonamiento analítico deliberado, pero a menudo exhiben un rendimiento comprometido en las tareas generales de […]
O3 y O4-Mini: desbloquear flujos de trabajo del agente empresarial con AI de razonamiento de próximo nivel con Azure Ai Foundry y GitHub

Estamos encantados de anunciar la disponibilidad de las últimas iteraciones en la serie de razonamiento O*: modelos O3 y O4-Mini en el servicio Microsoft Azure OpenAI. Estamos encantados de anunciar la disponibilidad de las últimas iteraciones en la Serie O de los modelos: OpenAI O3 y O4-Mini modelos de Servicio Microsoft Azure OpenAI en Azure […]
LLMS ahora puede resolver problemas matemáticos desafiantes con datos mínimos: los investigadores de UC Berkeley y AI2 presentan una prescripción de ajuste fino que desbloquea el razonamiento matemático a través de los niveles de dificultad

Los modelos de verbo han hecho avances significativos para tocar las tareas de razonamiento, incluso los enfoques de ajuste finos (SFT) supervisados a pequeña escalera (SFT), como la limusina y el S1, lo que demuestran mejoras notables en las capacidades matemáticas de resolución de problemas. Sin retención, quedan preguntas fundamentales sobre estos avances: ¿estos modelos […]
Google AI introduce el explorador de inteligencia médico articulado (AMIE): un maniquí de verbo amplio optimizado para el razonamiento dictamen y evalúa su capacidad para suscitar un dictamen diferencial

El expansión de un dictamen diferencial preciso (DDX) es una parte fundamental de la atención médica, típicamente lograda a través de un proceso paso a paso que integra el historial del paciente, los exámenes físicos y las pruebas de dictamen. Con el auge de las LLM, existe un potencial de creciente para apoyar y automatizar […]
Este artículo de IA presenta FastCurl: un situación de estudios de refuerzo curricular con extensión de contexto para una capacitación efectivo de modelos de razonamiento similar a R1

Los modelos de idiomas grandes han transformado cómo las máquinas comprenden y generan texto, especialmente en áreas complejas de resolución de problemas como el razonamiento matemático. Estos sistemas, conocidos como modelos tipo R1, están diseñados para pugnar procesos de pensamiento lentos y deliberados. Su fuerza esencia es manejar tareas complejas que requieren un razonamiento paso […]
Los investigadores de Tencent AI introducen Hunyuan-T1: un maniquí de estilo reaccionario magnate alimentado por mamba que redefine un razonamiento profundo, eficiencia contextual y estudios de refuerzo centrado en el ser humano

Los modelos de idiomas grandes luchan para procesar y razonar sobre textos largos y complejos sin perder un contexto esencial. Los modelos tradicionales a menudo sufren pérdida de contexto, manejo ineficiente de dependencias de grande importancia y dificultades para alinearse con las preferencias humanas, afectando la precisión y la eficiencia de sus respuestas. Hunyuan-T1 de […]
Meta AI presenta SWE-RL: un enfoque de IA para el razonamiento LLM basado en el educación de refuerzo de escalera para la ingeniería de software del mundo vivo

El progreso actual de software enfrenta una multitud de desafíos que se extienden más allá de la simple engendramiento de código o detección de errores. Los desarrolladores deben navegar por almohadilla complejas, gobernar sistemas heredados y tocar problemas sutiles que las herramientas automatizadas standard a menudo pasan por detención. Los enfoques tradicionales en la reparación […]
Meta AI publica ‘razonamiento natural’: un conjunto de datos de dominios múltiples con 2.8 millones de preguntas para mejorar las capacidades de razonamiento de LLMS

Los modelos de idiomas grandes (LLM) han mostrado avances notables en las capacidades de razonamiento para resolver tareas complejas. Mientras que modelos como Openi’s O1 y Deepseek’s R1 han mejorado significativamente los puntos de narración de razonamiento desafiantes, como las matemáticas de competencia, la codificación competitiva y el GPQA, las limitaciones críticas siguen siendo evaluando […]
¿Puede O3-Mini reemplazar Deepseek-R1 para un razonamiento metódico?
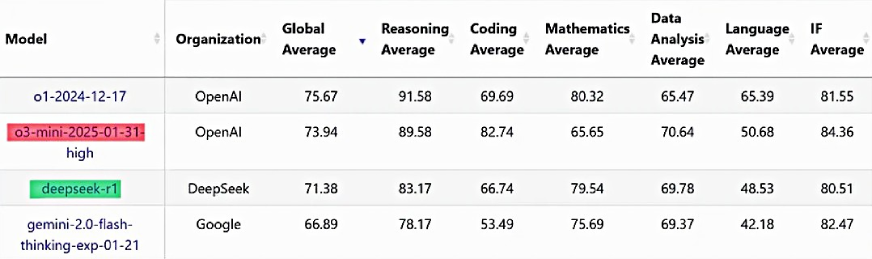
¡Los modelos de razonamiento con AI están tomando el mundo por asalto en 2025! Con el impulso de Deepseek-R1 y O3-Minihemos conocido niveles sin precedentes de capacidades lógicas de razonamiento en chatbots de IA. En este artículo, accederemos a estos modelos a través de sus API y evaluaremos sus habilidades de razonamiento metódico para investigar […]
El brinco de la India al razonamiento liberal de IA
La carrera de IA ha sido dominada por la Estados Unidos y China, Con modelos como Operai’s O3-Mini y Deepseek’s R1 Liderando en razonamiento y capacidades multilingües. Ahora, India está intensificando Sutra-R0un maniquí de razonamiento desarrollado por dos IA. Este maniquí no solo está dejando su marca; Está desafiando activamente las potencias globales de IA. […]