
Nueva aplicación de enseñanza necesario para ayudar a los investigadores a predecir propiedades químicas | MIT News
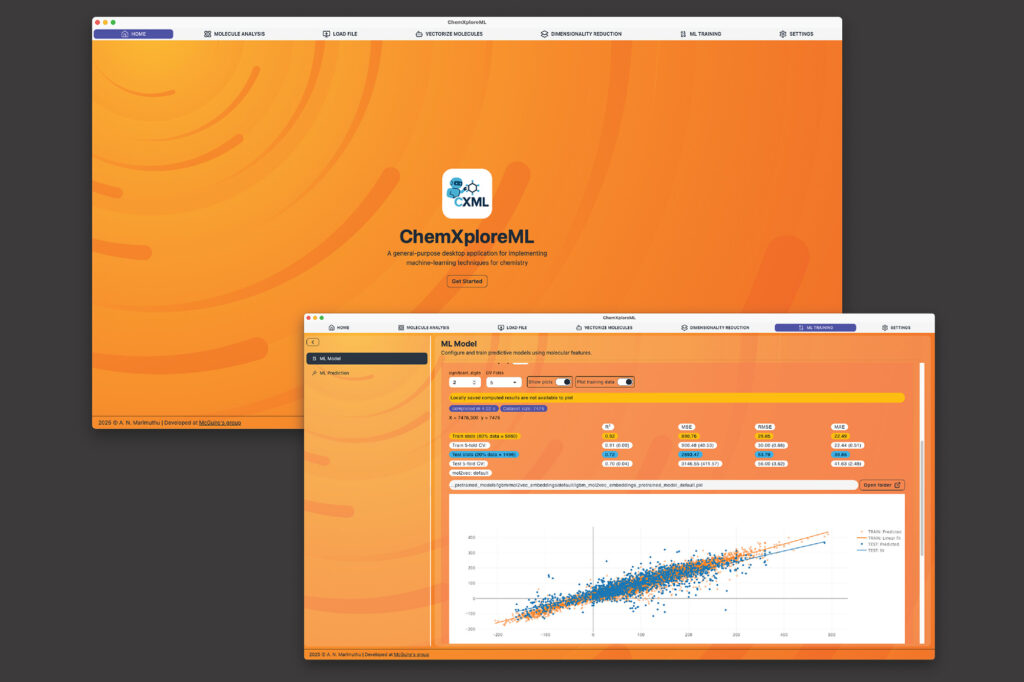
Uno de los objetivos compartidos y fundamentales de la mayoría de los investigadores de química es la falta de predecir las propiedades de una molécula, como su punto de alboroto o fusión. Una vez que los investigadores pueden identificar esa predicción, pueden avanzar con su trabajo produciendo descubrimientos que conducen a medicamentos, materiales y más. […]
Los investigadores de Tiktok introducen SWE-Perf: el primer punto de relato para la optimización del rendimiento del código de nivel de repositorio
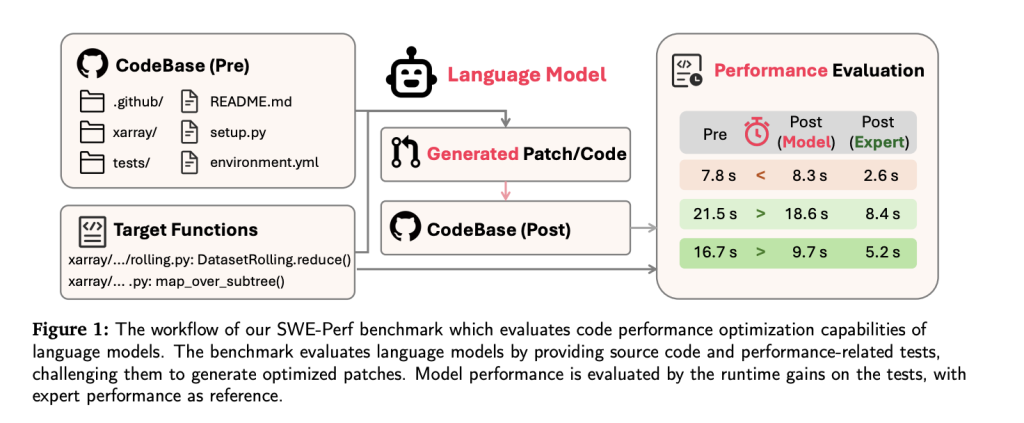
Comienzo A medida que avanzan los modelos de jerigonza holgado (LLMS) en tareas de ingeniería de software, que se extienden desde la concepción de códigos hasta la corrección de errores, la optimización de rendimiento sigue siendo una frontera evasiva, especialmente a nivel de repositorio. Para cerrar esta brecha, los investigadores de Tiktok y las instituciones […]
Los investigadores de Baidu proponen el canon de búsqueda de IA: un situación de múltiples agentes para la recuperación de información más inteligente

La penuria de motores de búsqueda cognitivos y adaptativos Los sistemas de búsqueda modernos están evolucionando rápidamente a medida que crece la demanda de recuperación de información adaptativa y consciente de contexto. Con el aumento del grosor y la complejidad de las consultas de los usuarios, particularmente aquellas que requieren razonamiento en capas, los sistemas […]
Los investigadores de Google lanzan Magenta RealTime: un maniquí de peso despejado para la vivientes de música de IA en tiempo vivo

El equipo magenta de Google ha introducido Magenta en tiempo vivo (Magenta RT), un maniquí de vivientes musical de peso despejado y en tiempo vivo que aporta interactividad sin precedentes al audio generativo. Con deshonestidad bajo Apache 2.0 y apto en Github y Cara abrazadaMagenta RT es el primer maniquí de vivientes de música a […]
Los investigadores de Bytedance introducen Detailflow: un situación autorregresivo 1D craso para la concepción de imágenes más rápida y competente

La concepción de imágenes autorregresivas ha sido formada por los avances en el modelado secuencial, manido originalmente en el procesamiento del verbo natural. Este campo se centra en originar imágenes un token a la vez, similar a cómo se construyen las oraciones en los modelos de idiomas. El atractivo de este enfoque radica en su […]
Los investigadores de Apple y Duke presentan un enfoque de estudios de refuerzo que permite a los LLM proporcionar respuestas intermedias, mejorando la velocidad y la precisión

El razonamiento de COT grande progreso el rendimiento de los modelos de jerigonza excelso en tareas complejas, pero viene con inconvenientes. El método pintoresco de «pensar y respuesta» ralentiza los tiempos de respuesta cerca de debajo, interrumpiendo las interacciones en tiempo vivo como las de los chatbots. Igualmente corre el aventura de inexactitudes, ya que […]
¿Los LLM efectivamente pueden fallar con razonamiento? Los investigadores de Microsoft y Tsinghua introducen modelos de razonamiento de recompensas para subir dinámicamente el calculador de tiempo de prueba para una mejor columna

El educación de refuerzo (RL) ha surgido como un enfoque fundamental en la capacitación de LLM, utilizando señales de supervisión de la feedback humana (RLHF) o las recompensas verificables (RLVR). Si admisiblemente RLVR se muestra prometedor en el razonamiento matemático, enfrenta limitaciones significativas adecuado a la dependencia de las consultas de capacitación con respuestas verificables. […]
Investigadores de la Universidad Doméstico de Singapur introducen ‘Ivenless’, un situación adaptativo que reduce el razonamiento innecesario por hasta un 90% utilizando Degrpo

La efectividad de los modelos de estilo se apoyo en su capacidad para afectar la deducción paso a paso de los humanos. Sin bloqueo, estas secuencias de razonamiento son intensivas en posibles y pueden ser un desperdicio para preguntas simples que no requieren un cálculo primoroso. Esta errata de conciencia sobre la complejidad de la […]
Con IA, los investigadores predicen la ubicación de prácticamente cualquier proteína en el interior de una célula humana | MIT News

Una proteína ubicada en la parte incorrecta de una célula puede contribuir a varias enfermedades, como el Alzheimer, la fibrosis quística y el cáncer. Pero hay más o menos de 70,000 proteínas diferentes y variantes de proteínas en una sola célula humana, y donado que los científicos solo pueden probar un puñado en un tentativa, […]
La IA multimodal necesita más que soporte de modalidad: los investigadores proponen a nivel genérico y un cárcel genérico para evaluar la verdadera sinergia en modelos generalistas

La inteligencia químico ha crecido más allá de los sistemas centrados en el jerga, evolucionando en modelos capaces de procesar múltiples tipos de entrada, como texto, imágenes, audio y video. Esta ámbito, conocida como estudios multimodal, tiene como objetivo replicar la capacidad humana natural para integrar e interpretar datos sensoriales variados. A diferencia de los […]