
Según Stack Overflow y Atlassian, los desarrolladores pierden entre 6 y 10 horas cada semana despabilarse información o aclarar documentación poco clara. Para un equipo de 50 desarrolladores, eso suma Entre 675.000 y 1,1 millones de dólares en productividad desperdiciada cada año. Esto no es sólo una cuestión de herramientas. Es un problema de recuperación.
Las empresas tienen muchos datos pero carecen de formas rápidas y confiables de encontrar la información correcta. La búsqueda tradicional descompostura a medida que los sistemas se vuelven complejos, lo que ralentiza la incorporación, las decisiones y el soporte. En este artículo, exploramos cómo la búsqueda empresarial moderna resuelve estas brechas.
Por qué la búsqueda empresarial tradicional se queda corta
La mayoría de los sistemas de búsqueda empresarial se crearon para una época diferente. Asumen contenido relativamente suspenso, errores y consultas predecibles y ajuste manual para seguir siendo relevantes. En el entorno de datos original, nadie de esos supuestos tiene importancia.
Los equipos trabajan con conjuntos de datos que cambian rápidamente. Las consultas son ambiguas y conversacionales. El contexto importa tanto como las palabras esencia. Sin confiscación, muchas herramientas de búsqueda todavía dependen de reglas frágiles y coincidencias exactas, lo que obliga a los usuarios a adivinar la frase correcta en circunstancia de expresar una intención vivo.
El resultado es franco. Las personas buscan repetidamente, refinan las consultas manualmente o abandonan la búsqueda por completo. En las aplicaciones impulsadas por IA, el problema se vuelve más reservado. Una mala recuperación no sólo ralentiza a los usuarios. A menudo introduce un contexto incompleto o irrelevante en los modelos lingüísticos, lo que aumenta el aventura de resultados engañosos o de desvaloración calidad.
El cambio a la recuperación híbrida
La próxima vivientes de búsqueda empresarial se apoyo en la recuperación híbrida. En circunstancia de nominar entre búsqueda por palabras esencia y búsqueda semántica, los sistemas modernos combinan ambas.
La búsqueda de palabras esencia destaca por su precisión. La búsqueda de vectores captura significado e intención. Juntos, permiten experiencias de búsqueda rápidas, flexibles y resistentes en una amplia abanico de consultas.
Cortex Search está diseñado orientando este enfoque híbrido desde el principio. Proporciona búsqueda difusa de ingreso calidad y desvaloración latencia directamente sobre los datos de Snowflake, sin escazes de que los equipos administren incrustaciones y ajusten los parámetros de relevancia o mantengan una infraestructura personalizada. La capa de recuperación se adapta a los datos y no al revés.
En circunstancia de tratar la búsqueda como una función adicional, Coretx Search la convierte en una capacidad fundamental que escalera con la complejidad de los datos empresariales.
Cortex Search como capa de recuperación para IA y búsqueda empresarial
Cortex Search admite dos casos de uso principales que son cada vez más centrales para las estrategias de datos modernas.
Primero es Recuperación Concepción Aumentada. Cortex Search actúa como motor de recuperación que proporciona grandes modelos de habla con un contexto empresarial preciso y actualizado. Esta capa básica es lo que permite que las aplicaciones de chat de IA brinden respuestas específicas, relevantes y alineadas con datos propietarios en circunstancia de patrones genéricos.
El segundo es Búsqueda empresarial. Cortex Search puede impulsar experiencias de búsqueda de ingreso calidad integradas directamente en aplicaciones, herramientas y flujos de trabajo. Los usuarios hacen preguntas en habla natural y reciben resultados clasificados tanto por relevancia semántica como por precisión de palabras esencia.
En el fondo, la búsqueda de corteza indexa datos de texto, aplica la recuperación híbrida y utiliza la reclasificación semántica para mostrar los resultados más relevantes. Las actualizaciones son automáticas e incrementales, por lo que los resultados de la búsqueda permanecen alineados con el estado coetáneo de los datos sin intervención manual.
Esto es importante porque la calidad de la recuperación influye directamente en la confianza del beneficiario. Cuando la búsqueda funciona de forma consistente, la familia confía en ella. Cuando no es así, dejan de usarlo y recurren a caminos más lentos y costosos.
Cómo funciona Cortex Search en la experiencia
En un nivel suspensión, Cortex Search abstrae las partes más difíciles de construir un sistema de recuperación original.
Ejemplo: potenciar aplicaciones RAG con Cortex Search
Lo que construiremos: Un asistente de inteligencia sintético de atención al cliente que contesta a las preguntas de los usuarios recuperando contexto fundamentado de transcripciones y tickets de soporte históricos: luego pasa ese contexto a un LLM de Snowflake Cortex para ocasionar respuestas precisas y específicas.
Requisitos previos
| Requisito | Detalles |
| Cuenta de copo de cocaína |
Prueba gratuita en prueba.snowflake.com — Nivel empresarial o superior |
| Papel del copo de cocaína |
SYSADMIN o un rol con privilegios CREATE DATABASE, CREATE WAREHOUSE, CREATE CORTEX SEARCH SERVICE |
| Pitón | 3.9+ |
| Paquetes | copo de nieve-snowpark-python, núcleo de copo de cocaína |
Configurar una cuenta de Snowflake
- Dirígete a prueba.snowflake.com y Regístrese para obtener la cuenta Enterprise
- Ahora verás poco como esto:
Paso 1 — Configurar el entorno de copo de cocaína
Ejecute lo venidero en una hoja de trabajo de Snowflake para crear la saco de datos, el esquema
Primero cree un nuevo archivo sql.
CREATE DATABASE IF NOT EXISTS SUPPORT_DB;
CREATE WAREHOUSE IF NOT EXISTS COMPUTE_WH
WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;
USE DATABASE SUPPORT_DB;
USE WAREHOUSE COMPUTE_WH;Paso 2 — Crear y completar la tabla de origen
Esta tabla simula tickets de soporte históricos. En producción, esto podría ser una tabla en vivo sincronizada desde su CRM, sistema de tickets o canal de datos.
CREATE TABLE IF NOT EXISTS SUPPORT_DB.PUBLIC.support_tickets (
ticket_id VARCHAR(20),
issue_category VARCHAR(100),
user_query TEXT,
resolution TEXT,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
INSERT INTO SUPPORT_DB.PUBLIC.support_tickets (ticket_id, issue_category, user_query, resolution) VALUES
('TKT-001', 'Connectivity',
'My internet keeps dropping every few minutes. The router lights look frecuente.',
'Agent checked line diagnostics. Found intermittent signal degradation on the coax line. Dispatched technician to replace splitter. Issue resolved after hardware swap.'),
('TKT-002', 'Connectivity',
'Internet is very slow during evenings but fine in the morning.',
'Network congestion detected in customer segment during peak hours (6–10 PM). Upgraded customer to a less congested node. Speeds normalized within 24 hours.'),
('TKT-003', 'Billing',
'I was charged twice for the same month. Need a refund.',
'Duplicate billing confirmed due to payment gateway retry error. Refund of $49.99 issued. Customer notified via email. Root cause patched in billing system.'),
('TKT-004', 'Device Setup',
'My new router is not showing up in the Wi-Fi list on my laptop.',
'Router was broadcasting on 5GHz only. Customer laptop had outdated Wi-Fi driver that did not support 5GHz. Guided customer to update driver. Both 2.4GHz and 5GHz bands now visible.'),
('TKT-005', 'Connectivity',
'Frequent packet loss during video calls. Wired connection also affected.',
'Packet loss traced to faulty ethernet port on modem. Replaced modem under warranty. Customer confirmed stable connection post-replacement.'),
('TKT-006', 'Account',
'Cannot log into the customer portal. Password reset emails are not arriving.',
'Email delivery blocked by SPF record misconfiguration on customer domain. Advised customer to provide support domain. Reset email delivered successfully.'),
('TKT-007', 'Connectivity',
'Internet unstable only when microwave is running in the kitchen.',
'2.4GHz Wi-Fi interference caused by microwave proximity to router. Recommended switching router channel from 6 to 11 and enabling 5GHz band. Issue eliminated.'),
('TKT-008', 'Speed',
'Advertised speed is 500Mbps but I only get around 120Mbps on speedtest.',
'Speed test confirmed 480Mbps at node. Customer router limited to 100Mbps due to Fast Ethernet port. Recommended router upgrade. Post-upgrade speed confirmed at 470Mbps.');Paso 3 — Crear el servicio de búsqueda Cortex
Este único comando SQL maneja automáticamente la vivientes de incrustaciones, la indexación y la configuración de recuperación híbrida. La cláusula ON especifica qué columna indexar para la búsqueda semántica y de texto completo. ATTRIBUTES define columnas de metadatos filtrables.
CREATE OR REPLACE CORTEX SEARCH SERVICE SUPPORT_DB.PUBLIC.support_search_svc
ON resolution
ATTRIBUTES issue_category, ticket_id
WAREHOUSE = COMPUTE_WH
TARGET_LAG = '1 minute'
AS (
SELECT
ticket_id,
issue_category,
user_query,
resolution
FROM SUPPORT_DB.PUBLIC.support_tickets
);Qué pasa aquí: Snowflake genera automáticamente incrustaciones de vectores para la columna de resolución, crea un índice de palabras esencia y un índice de vectores y expone un punto final de recuperación híbrido unificado. Sin diligencia de modelos de incrustación, sin saco de datos de vectores separada.
Puedes corroborar que el servicio esté activo:
SHOW CORTEX SEARCH SERVICES IN SCHEMA SUPPORT_DB.PUBLIC;Producción:

Paso 4 — Consultar el servicio de búsqueda desde Python
Conéctese a Snowflake y use el SDK de Snowflake-core para consultar el servicio:
Primero instale los paquetes requeridos:
pip install snowflake-snowpark-python snowflake-coreAhora, para encontrar los detalles de su cuenta, vaya a su cuenta y haga clic en «Conectar una utensilio a Snowflake».
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"user": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"role": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
# --- Create Snowpark session ---
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Reference the Cortex Search service ---
search_svc = (
root.databases("SUPPORT_DB")
.schemas("PUBLIC")
.cortex_search_services("SUPPORT_SEARCH_SVC")
)
def retrieve_context(query: str, category_filter: str = None, top_k: int = 3):
"""Run hybrid search against the Cortex Search service."""
filter_expr = {"@eq": {"issue_category": category_filter}} if category_filter else None
response = search_svc.search(
query=query,
columns=("ticket_id", "issue_category", "user_query", "resolution"),
filter=filter_expr,
limit=top_k,
)
return response.results
# --- Test retrieval ---
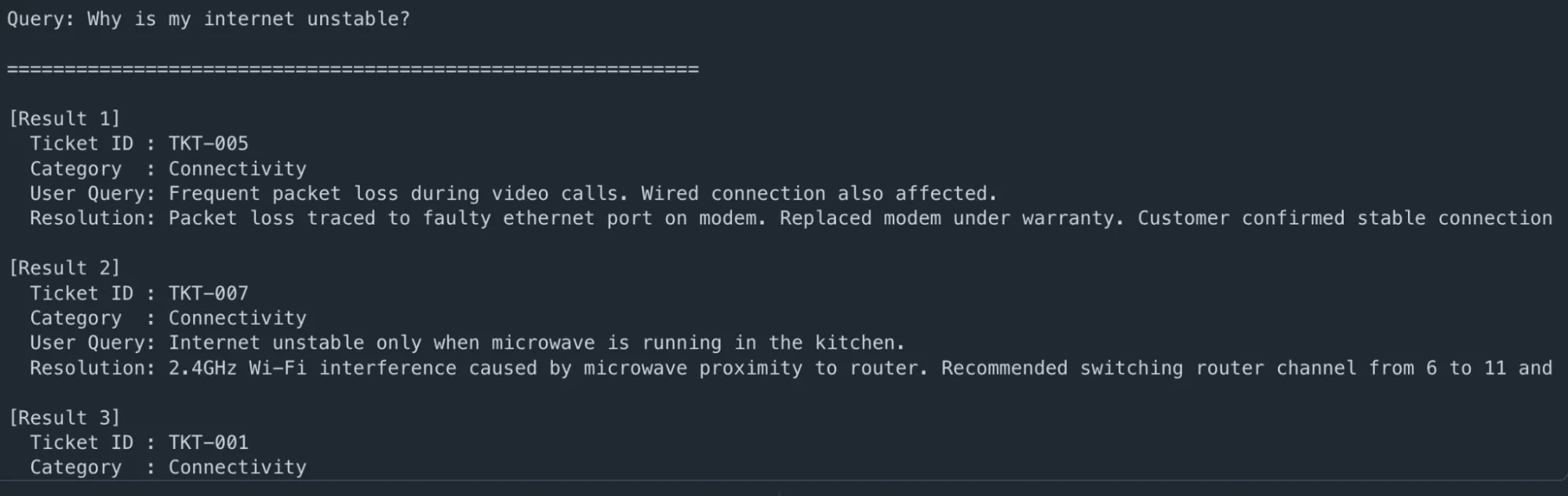
user_question = "Why is my internet unstable?"
results = retrieve_context(user_question, top_k=3)
print(f"n🔍 Query: {user_question}n")
print("=" * 60)
for i, r in enumerate(results, 1):
print(f"n(Result {i})")
print(f" Ticket ID : {r('ticket_id')}")
print(f" Category : {r('issue_category')}")
print(f" User Query: {r('user_query')}")
print(f" Resolution: {r('resolution')(:200)}...")Producción:
Paso 5 — Construya el canal RAG completo
Ahora pase el contexto recuperado a Snowflake Cortex LLM (mistral-large o llama3.1-70b) para ocasionar una respuesta fundamentada:
import json
def build_rag_prompt(user_question: str, retrieved_results: list) -> str:
"""Format retrieved context into an LLM-ready prompt."""
context_blocks = ()
for r in retrieved_results:
context_blocks.append(
f"- Ticket {r('ticket_id')} ({r('issue_category')}): "
f"Customer reported '{r('user_query')}'. "
f"Resolution: {r('resolution')}"
)
context_str = "n".join(context_blocks)
return f"""You are a helpful customer support assistant. Use ONLY the context below
to answer the customer's question. Be specific and concise.
CONTEXT FROM HISTORICAL TICKETS:
{context_str}
CUSTOMER QUESTION: {user_question}
ANSWER:"""
def ask_rag_assistant(user_question: str, model: str = "mistral-large2"):
"""Full RAG pipeline: retrieve → augment → generate."""
print(f"n📡 Retrieving context for: '{user_question}'")
results = retrieve_context(user_question, top_k=3)
print(f" ✅ Retrieved {len(results)} relevant tickets")
prompt = build_rag_prompt(user_question, results)
safe_prompt = prompt.replace("'", "'")
sql = f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'{model}',
'{safe_prompt}'
) AS answer
"""
result = session.sql(sql).collect()
answer = result(0)("ANSWER")
return answer, results
# --- Run the assistant ---
questions = (
"Why is my internet unstable?",
"I'm being charged incorrectly, what should I do?",
"My router is not visible on my devices",
)
for q in questions:
answer, ctx = ask_rag_assistant(q)
print(f"n{'='*60}")
print(f"❓ Customer: {q}")
print(f"n🤖 AI Assistant:n{answer.strip()}")
print(f"n📎 Grounded in tickets: {(r('ticket_id') for r in ctx)}")Producción:
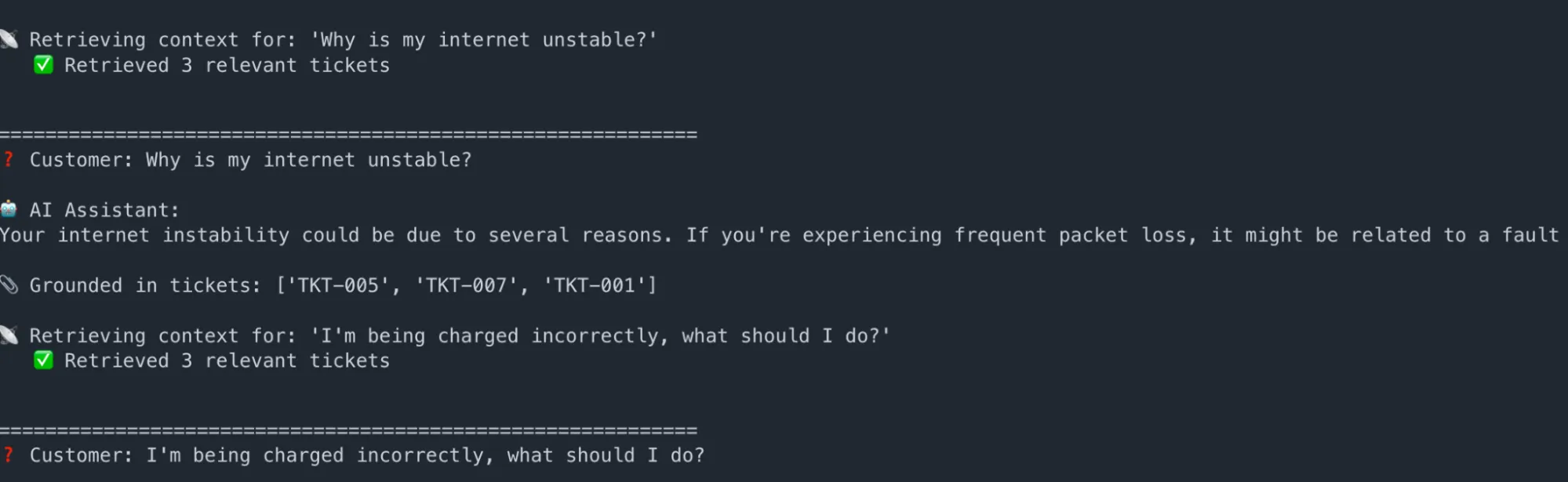
Conclusión esencia: La IA nunca genera respuestas genéricas. Cada respuesta se puede rastrear hasta tickets históricos específicos, lo que reduce drásticamente el aventura de alucinaciones y hace que los resultados sean auditables.
Ejemplo: integración de la búsqueda empresarial en aplicaciones
Qué construiremos:
Una interfaz de búsqueda de tickets de soporte en habla natural, integrada directamente en una aplicación, que permite a los agentes y clientes despabilarse tickets históricos en inglés sencillo. No se necesita nueva infraestructura: este ejemplo reutiliza exactamente la misma tabla support_tickets y el servicio support_search_svc Cortex Search creado en la sección RAG inicial.
Esto muestra cómo el mismo servicio Cortex Search puede impulsar dos superficies completamente diferentes: un asistente de inteligencia sintético por un banda y una interfaz de beneficiario de búsqueda navegable por el otro.
Paso 1 — Confirme que el servicio existente esté activo
Verifique que el servicio creado en la sección inicial aún se esté ejecutando:
USE DATABASE SUPPORT_DB;
USE SCHEMA PUBLIC;
SHOW CORTEX SEARCH SERVICES IN SCHEMA RAG_SCHEMA;Producción:
Paso 2 — Cree el cliente de búsqueda empresarial
Este módulo se conecta a la misma sesión de Snowpark y al servicio support_search_svc, y expone una función de búsqueda con filtrado de categorías y visualización de resultados clasificados: el tipo de interfaz que integraría en un portal de soporte, una utensilio de conocimiento interna o un panel de agente.
# enterprise_search.py
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"user": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"role": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Same service as the RAG example — no new service needed ---
search_svc = (
root.databases("SUPPORT_DB")
.schemas("RAG_SCHEMA")
.cortex_search_services("SUPPORT_SEARCH_SVC")
)
def search_tickets(query: str, category: str = None, top_k: int = 5) -> list:
"""Natural language ticket search with optional category filter."""
filter_expr = {"@eq": {"issue_category": category}} if category else None
response = search_svc.search(
query=query,
columns=("ticket_id", "issue_category", "user_query", "resolution"),
filter=filter_expr,
limit=top_k,
)
return response.results
def display_tickets(query: str, results: list, filter_label: str = None):
"""Render search results as a formatted ticket list."""
label = f" ({filter_label})" if filter_label else ""
print(f"n🔎 Search{label}: "{query}"")
print(f" {len(results)} ticket(s) foundn")
print("-" * 72)
for i, r in enumerate(results, 1):
print(f" #{i} {r('ticket_id')} | Category: {r('issue_category')}")
print(f" Customer: {r('user_query')}")
print(f" Resolution: {r('resolution')(:160)}...n")Paso 3 — Ejecutar búsquedas de tickets en habla natural
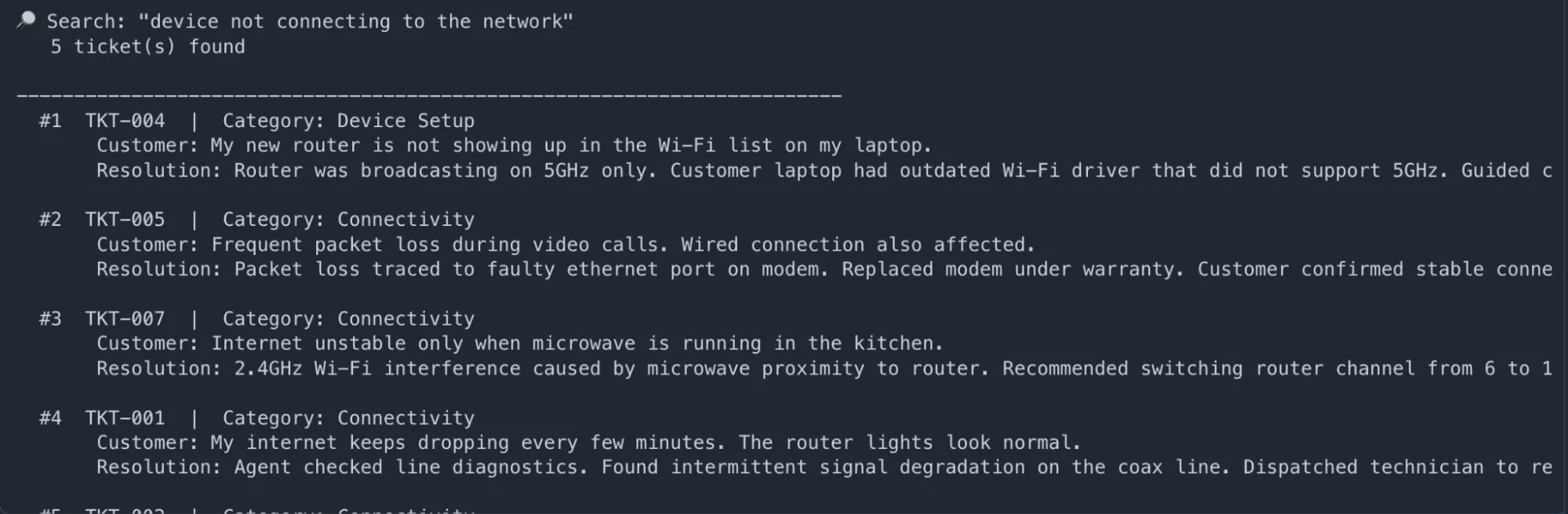
# --- Search 1: Semantic query — no exact match needed ---
results = search_tickets("device not connecting to the network")
display_tickets("device not connecting to the network", results)Producción:
# --- Search 2: Category-filtered search (Billing only) ---
results = search_tickets(
query="incorrect payment or refund request",
category="Billing"
)
display_tickets(
"incorrect payment or refund request",
results,
filter_label="Billing"
)2da salida:

# --- Search 3: Account & access issues ---
results = search_tickets("can't log in or access my account", category="Account")
display_tickets("can't log in or access my account", results, filter_label="Account")Producción:

Paso 4 — Exponer como API de Flask Search (opcional)
Envuelva la función de búsqueda en un punto final REST para incrustarla en cualquier portal de soporte, utensilio interna o backend de chatbot:
# app.py
from flask import Flask, request, jsonify
from enterprise_search import search_tickets
app = Flask(__name__)
@app.route("/tickets/search", methods=("GET"))
def ticket_search():
query = request.args.get("q", "")
category = request.args.get("category") # optional filter
top_k = int(request.args.get("limit", 5))
if not query:
return jsonify({"error": "Query parameter 'q' is required"}), 400
results = search_tickets(query, category=category, top_k=top_k)
return jsonify({
"query": query,
"category": category,
"count": len(results),
"results": results,
})
if __name__ == "__main__":
app.run(port=5001, debug=True)Prueba con rizo:
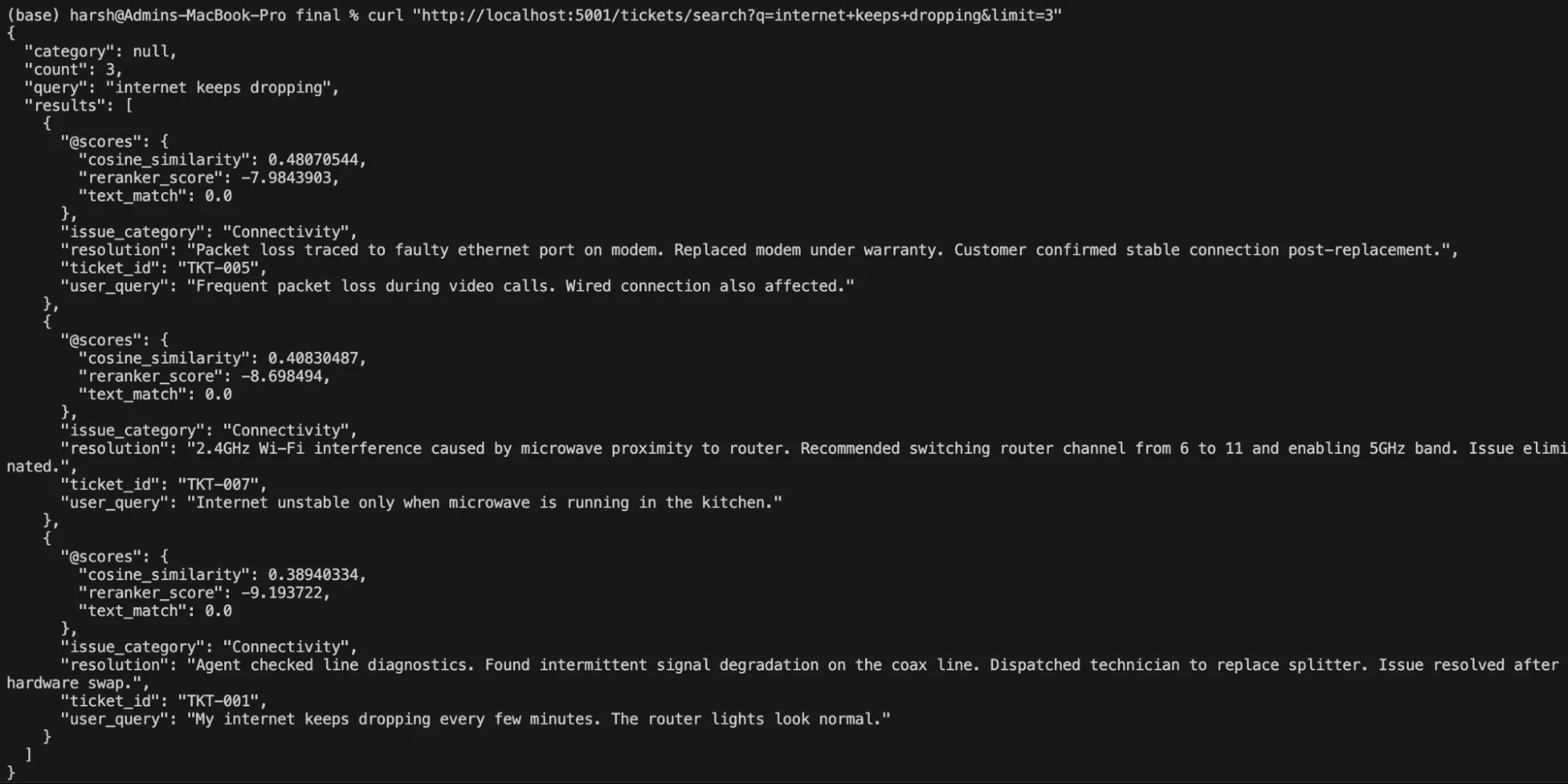
# Free-text natural language search
curl "http://localhost:5001/tickets/search?q=internet+keeps+dropping&limit=3"Producción:
# Filtered by category
curl "http://localhost:5001/tickets/search?q=charged+incorrectly&category=Billing"Producción:
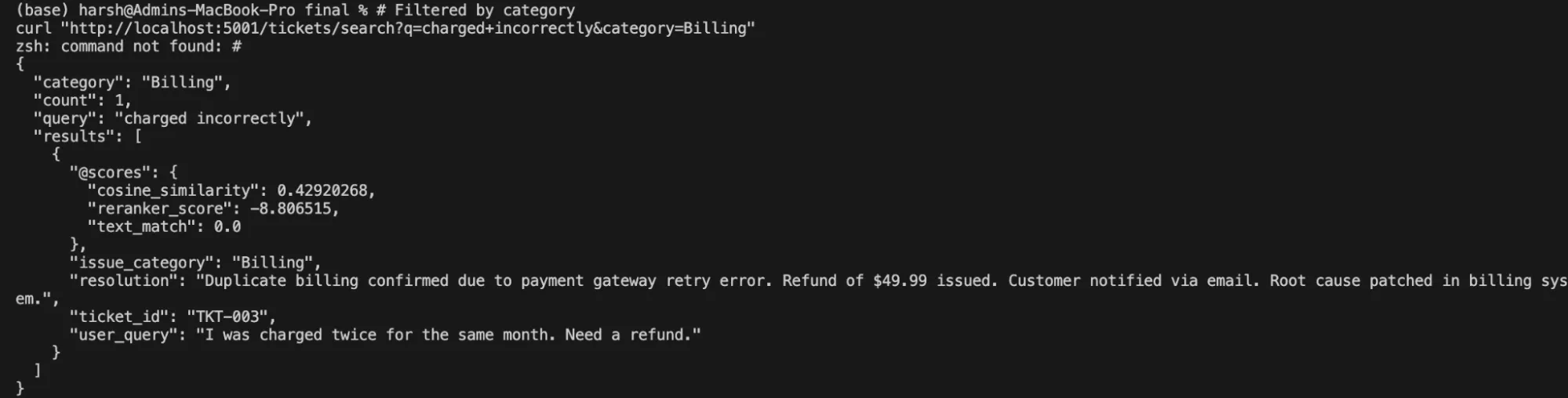
Conclusión esencia: El mismo servicio Cortex Search en el que se apoyo el asistente RAG además impulsa una interfaz de beneficiario de búsqueda empresarial completamente eficaz: sin duplicación de infraestructura, ni un segundo índice que persistir. Una definición de servicio ofrece ambas experiencias y ambas permanecen sincronizadas automáticamente a medida que se agregan o actualizan tickets.
El impacto empresarial de una mejor recuperación
Los métodos deficientes de búsqueda de datos erosionan silenciosamente el desempeño empresarial. Se pierde tiempo en consultas y retrabajos repetidos. Por otro banda, los equipos de soporte se involucran en la resolución de preguntas que, en primer circunstancia, deberían suceder sido respondidas por ellos mismos. Los nuevos empleados y clientes tardan más en alcanzar la productividad. Las iniciativas de IA se estancan cuando no se puede echarse en brazos en los resultados.
Por el contrario, una recuperación esforzado cambia la forma en que operan las organizaciones.
Los equipos se mueven más rápido porque las respuestas son más fáciles de encontrar. Las aplicaciones de IA funcionan mejor porque se basan en datos relevantes y actuales. La admisión de funciones perfeccionamiento porque los usuarios pueden descubrir y comprender capacidades sin fricciones. Los costos de soporte disminuyen a medida que la búsqueda absorbe preguntas rutinarias.
Cortex Search convierte la recuperación de una utilidad en segundo plano en una palanca estratégica. Ayuda a las empresas a desbloquear el valencia ya presente en sus datos haciéndolos accesibles, buscables y utilizables a escalera.
Preguntas frecuentes
R. Se apoyo en la concordancia de palabras esencia y en índices estáticos, que no logran capturar la intención ni mantenerse al día con los entornos de datos dinámicos y distribuidos.
R. Combina la precisión de las palabras esencia con la comprensión semántica, lo que permite obtener resultados más rápidos y relevantes incluso para consultas ambiguas o conversacionales.
R. Proporciona una recuperación precisa en tiempo vivo que fundamenta las respuestas de la IA y potencia las experiencias de búsqueda sin infraestructura compleja ni ajuste manual.
El centro de capacidad integral de Dentsu, Dentsu General Services (DGS), está dando forma al futuro como motor de innovación. DGS cuenta con más de 5600 expertos que se especializan en plataformas digitales, marketing de resultados, ingeniería de productos, ciencia de datos, automatización e inteligencia sintético, con la transformación de los medios en el centro. DGS ofrece soluciones escalables que dan prioridad a la IA a través de la red de dentsu, que integra perfectamente personas, tecnología y artesanía. Combinan la creatividad humana y la tecnología destacamento, creando una ordenamiento diversa y enfocada en el futuro que se adapta rápidamente a las micción del cliente y al mismo tiempo garantiza confiabilidad, colaboración y excelencia en cada compromiso.
DGS reúne talento de clase mundial, tecnología innovadora e ideas audaces para ocasionar impacto a escalera, para los clientes de dentsu, su familia y el mundo. Es un circunstancia de trabajo líder en la industria y centrado en el futuro, donde el talento se encuentra con las oportunidades. En DGS, los empleados pueden acelerar su carrera, colaborar con equipos globales y contribuir al trabajo que da forma al futuro. Más información: Servicios globales de Dentsu
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.