
Los clientes que migran de bases de datos Oracle locales a AWS enfrentan un desafío: reubicar de modo competente tipos de datos de objetos (LOB) grandes al almacenamiento de objetos mientras se mantiene la integridad y el rendimiento de los datos. Este desafío se origina en el diseño tradicional de bases de datos empresariales donde los LOB se almacenan conexo con datos estructurados, lo que genera limitaciones de capacidad de almacenamiento, complejidad de respaldo y cuellos de botella en el rendimiento durante la recuperación y el procesamiento de datos. Los LOB, que pueden incluir imágenes, vídeos y otros archivos grandes, a menudo provocan que las migraciones de datos tradicionales sufran velocidades lentas y problemas de truncamiento de LOB. Estas cuestiones son particularmente problemáticas para las migraciones de larga duración que pueden durar varios primaveras.
En esta publicación, presentamos una opción escalable que utiliza Streaming administrado por Amazon para Apache Kafka (Amazon MSK), Estampación compatible con Amazon Aurora PostgreSQLy Conexión de Amazon MSK. La transmisión de datos permite la replicación de datos donde las modificaciones se envían y reciben en un flujo continuo, lo que permite que la saco de datos de destino acceda y aplique los cambios en tiempo efectivo. Esta opción genera eventos para acciones de la saco de datos como insertar, desempolvar y eliminar, activando AWS Lambda funciones para descargar LOB de la saco de datos Oracle de origen y cargarlos en Servicio de almacenamiento simple de Amazon (Amazon S3) cubos. Simultáneamente, los eventos de transmisión migran los datos estructurados de la saco de datos de Oracle a la saco de datos de destino mientras mantienen la vinculación adecuada con sus respectivos LOB.
La implementación completa está habitable en GitHubincluido Kit de incremento de la abundancia de AWS (AWS CDK), archivos de configuración e instrucciones de instalación.
Descripción normal de la opción
Aunque las migraciones tradicionales de bases de datos de Oracle manejan datos estructurados de modo efectiva, tienen dificultades con los LOB que pueden incluir imágenes, videos y documentos. Estas migraciones a menudo fallan oportuno a limitaciones de tamaño y problemas de truncamiento, lo que genera importantes riesgos comerciales, incluida la pérdida de datos, tiempos de inactividad prolongados y retrasos en los proyectos que pueden obligarlo a retrasar sus iniciativas de transformación en la abundancia. El problema se agudiza durante las migraciones de larga duración que abarcan varios primaveras, donde suministrar la continuidad operativa es fundamental. Esta opción aborda los desafíos secreto de la migración LOB, permitiendo operaciones continuas a extenso plazo sin comprometer el rendimiento o la confiabilidad.
Al eliminar las limitaciones de tamaño asociadas con las tecnologías de migración tradicionales, nuestra opción proporciona un situación sólido que le ayuda a reubicar los LOB sin problemas y al mismo tiempo facilita la integridad de los datos durante todo el proceso.
Nuestro enfoque utiliza una obra de transmisión moderna para aliviar las limitaciones tradicionales de la migración LOB de Oracle. La opción incluye los siguientes componentes principales:
- Amazon MSK – Proporciona la infraestructura de streaming.
- Conexión de Amazon MSK – Usando dos conectores:
- Conector Debezium para Oracle como conector de origen para capturar cambios a nivel de fila que ocurren en la saco de datos Oracle. El conector emite eventos de cambio y publica en un tema fuente de Kafka.
- Conector Debezium para JDBC como conector receptor para consumir eventos del tema fuente de Kafka y luego escribir esos eventos en Aurora compatible con PostgreSQL mediante un regulador JDBC.
- función lambda – Activado por una asignación de origen de evento a Amazon MSK. La función procesa eventos del tema fuente de Kafka y extrae la secreto principal de la fila de Oracle de cada carga útil del evento. Utiliza esta secreto para descargar los datos BLOB correspondientes de la saco de datos Oracle de origen y los carga en Amazon S3, organizando los archivos por carpetas de secreto principal para suministrar un vínculo simple con los registros de la saco de datos relacional.
- Amazon RDS para Oracle – Servicio de saco de datos relacional de Amazon (Amazon RDS) para Oracle se utiliza como saco de datos de origen para disimular una saco de datos Oracle recinto.
- Compatible con Aurora PostgreSQL – Se utiliza como saco de datos de destino para los datos migrados.
- amazon s3 – Se utiliza como almacenamiento de objetos para juntar los datos BLOB de la saco de datos de origen.
El ulterior diagrama muestra la opción de obra de migración de datos LOB de Oracle.
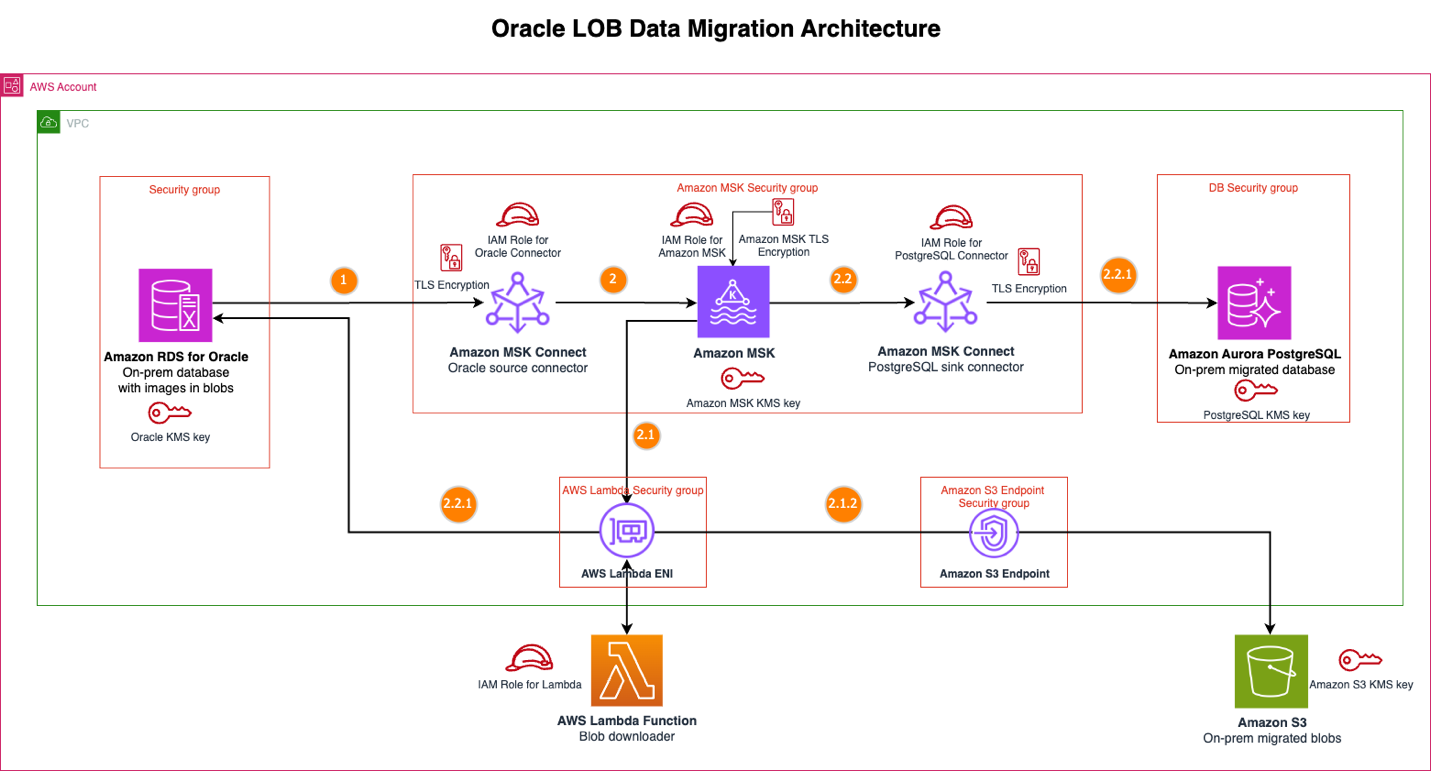
Flujo de mensajes
Cuando se producen cambios en los datos en la saco de datos de origen de Amazon RDS para Oracle, la opción ejecuta la ulterior secuencia, pasando por la detección y publicación de eventos, el procesamiento de BLOB con Lambda y el procesamiento de datos estructurados:
- El conector de origen de Oracle captura los eventos de captura de datos modificados (CDC), incluido el cambio en la columna de datos BLOB. Este conector configura la columna de datos BLOB para excluirla del evento Kafka para optimizar la carga útil de Kafka.
- El conector publica este evento en un tema de MSK.
- El evento MSK activa la función BLOB Downloader Lambda para los eventos CDC.
- La función Lambda examina dos condiciones secreto: el código de evento de Debezium (específicamente verificando crear (c) o desempolvar (u)) y la directorio configurada de nombres de tablas BLOB de Oracle conexo con sus nombres de columnas. Cuando un mensaje de Kafka coincide con la directorio de tablas configuradas y los eventos válidos de Debezium, la función Lambda inicia la descarga de datos BLOB desde la fuente de Oracle utilizando la secreto principal y el nombre de la tabla; de lo contrario, la función omite el proceso de descarga de BLOB. Este enfoque selectivo garantiza que la función Lambda solo ejecute consultas SQL cuando procese mensajes Kafka para tablas que contienen datos BLOB, optimizando las interacciones de la saco de datos.
- La función Lambda carga el BLOB en Amazon S3, organizándolo por carpetas de secreto principal con nombres de objetos únicos, lo que permite vincular entre registros de bases de datos estructuradas y sus datos BLOB correspondientes en Amazon S3.
- El conector receptor de PostgreSQL recibe el evento del tema MSK.
- El conector aplica estos cambios a la saco de datos Aurora PostgreSQL para los cambios de la saco de datos Oracle, excepto la columna de datos BLOB. La columna de datos BLOB está excluida por el conector de origen de Oracle.
- El evento MSK activa la función BLOB Downloader Lambda para los eventos CDC.
Beneficios secreto
La opción ofrece las siguientes ventajas secreto:
- Optimización de costes y licencias. – Nuestro enfoque ofrece importantes beneficios de optimización de costos al resumir el tamaño total de su saco de datos y aliviar su obligación de costosas licencias asociadas con bases de datos tradicionales y tecnologías de replicación. Al desacoplar el almacenamiento LOB de la saco de datos y utilizar Amazon S3, puede resumir el espacio total de la saco de datos y resumir los costos asociados con las tecnologías tradicionales de replicación y licencias. La obra de transmisión además minimiza la sobrecarga de su infraestructura durante migraciones de larga duración.
- Evita restricciones de tamaño y errores de migración – Las herramientas de migración tradicionales a menudo imponen limitaciones de tamaño en las transferencias de LOB, lo que genera problemas de truncamiento y migraciones fallidas. Esta opción elimina esas restricciones por completo, por lo que puede portar LOB de diferentes tamaños manteniendo la integridad de los datos. La obra basada en eventos permite la replicación de datos casi en tiempo efectivo, lo que permite que sus sistemas de origen permanezcan operativos durante la migración.
- Continuidad del negocio y excelencia operativa – Los cambios fluyen continuamente en dirección a su entorno objetivo, lo que permite la continuidad del negocio. La opción preserva las relaciones entre los registros de bases de datos estructuradas y sus LOB correspondientes a través de una estructura basada en claves primarias en Amazon S3, lo que permite la integridad referencial y al mismo tiempo proporciona la flexibilidad del almacenamiento de objetos para archivos grandes.
- Ventajas arquitectónicas – Juntar LOB en Amazon S3 mientras se mantienen datos estructurados en Aurora PostgreSQL-Compatible crea una separación clara. Esta obra simplifica sus operaciones de respaldo y recuperación, mejoría el rendimiento de las consultas en datos estructurados y proporciona patrones de llegada flexibles para objetos binarios a través de Amazon S3.
Mejores prácticas de implementación
Considere las siguientes mejores prácticas al implementar esta opción:
- Comience poco a poco y escale gradualmente. Para implementar esta opción, comience con un tesina piloto utilizando datos que no sean de producción para validar su enfoque antaño de comprometerse con una migración a gran escalera. Esto le brinda la oportunidad de resolver problemas en un entorno controlado y perfeccionar su configuración sin afectar los sistemas de producción.
- Audición – Establecer un seguimiento integral a través de Amazon CloudWatch para realizar un seguimiento de métricas secreto como el retraso de Kafka, los errores de la función Lambda y la latencia de replicación. Establezca umbrales de alerta con anticipación para que pueda detectar y resolver problemas rápidamente antaño de que afecten su cronograma de migración. Dimensione su clúster MSK según el pandeo de CDC esperado y configure la simultaneidad reservada de Lambda para manejar las cargas máximas durante la sincronización original de datos.
- Seguridad – Por seguridad, utilice oculto en tránsito y en reposo tanto para datos estructurados como para LOB, y siga el principio de privilegio intrascendente al configurar Trámite de llegada e identidad de AWS (IAM) roles y políticas para su clúster MSK, funciones Lambda, depósitos S3 e instancias de bases de datos. Documente sus asignaciones de esquemas entre Oracle y Aurora PostgreSQL-Compatible, incluido cómo los registros de la saco de datos se vinculan con sus LOB correspondientes en Amazon S3.
- Pruebas y preparación – Antiguamente de comenzar a funcionar, pruebe minuciosamente sus procedimientos de conmutación por error y recuperación. Valide escenarios como fallas de la función Lambda, problemas del clúster MSK y problemas de conectividad de red para cerciorarse de estar preparado para posibles problemas. Finalmente, recuerde que esta obra de transmisión mantiene la coherencia eventual entre sus sistemas de origen y de destino, por lo que puede activo breves retrasos durante períodos de gran pandeo. Planifique su táctica de transición teniendo esto en cuenta.
Limitaciones y consideraciones
Aunque esta opción proporciona un enfoque sólido para portar bases de datos de Oracle con LOB a AWS, existen varias limitaciones inherentes que se deben comprender antaño de la implementación.
Esta opción requiere conectividad de red entre su saco de datos Oracle de origen y el entorno de AWS. Para bases de datos Oracle locales, debe establecer Conexión directa de AWS o vpn conectividad antaño de la implementación. El pancho de costado de la red afecta directamente la velocidad de replicación y el rendimiento normal de la migración, por lo que su conexión debe poder manejar el pandeo esperado de eventos CDC y transferencias LOB.
La opción utiliza Debezium Connector para Oracle como conector de origen y Debezium Connector para JDBC como conector receptor. Esta obra está diseñada específicamente para sus migraciones de Oracle a PostgreSQL. Otras combinaciones de bases de datos requieren configuraciones de conector diferentes o es posible que no sean compatibles con la implementación coetáneo. El rendimiento de la migración además está escaso por la capacidad del clúster MSK y los límites de simultaneidad de Lambda. Además puede exceder las cuotas de servicios de AWS para migraciones a gran escalera y es posible que deba solicitar aumentos de cuotas a través de AWS Enterprise Support.
Conclusión
En esta publicación, presentamos una opción que aborda el desafío crítico de portar sus grandes objetos binarios de Oracle a AWS mediante el uso de una obra de transmisión que separa el almacenamiento LOB de los datos estructurados. Este enfoque evita restricciones de tamaño, reduce los costos de osadía de Oracle y preserva la integridad de los datos durante períodos prolongados de migración.
¿Preparado para trocar su táctica de migración a Oracle? Invitado el GitHub repositorio, donde encontrará el código completo de implementación de AWS CDK, los archivos de configuración y las instrucciones paso a paso para comenzar.
Sobre los autores