
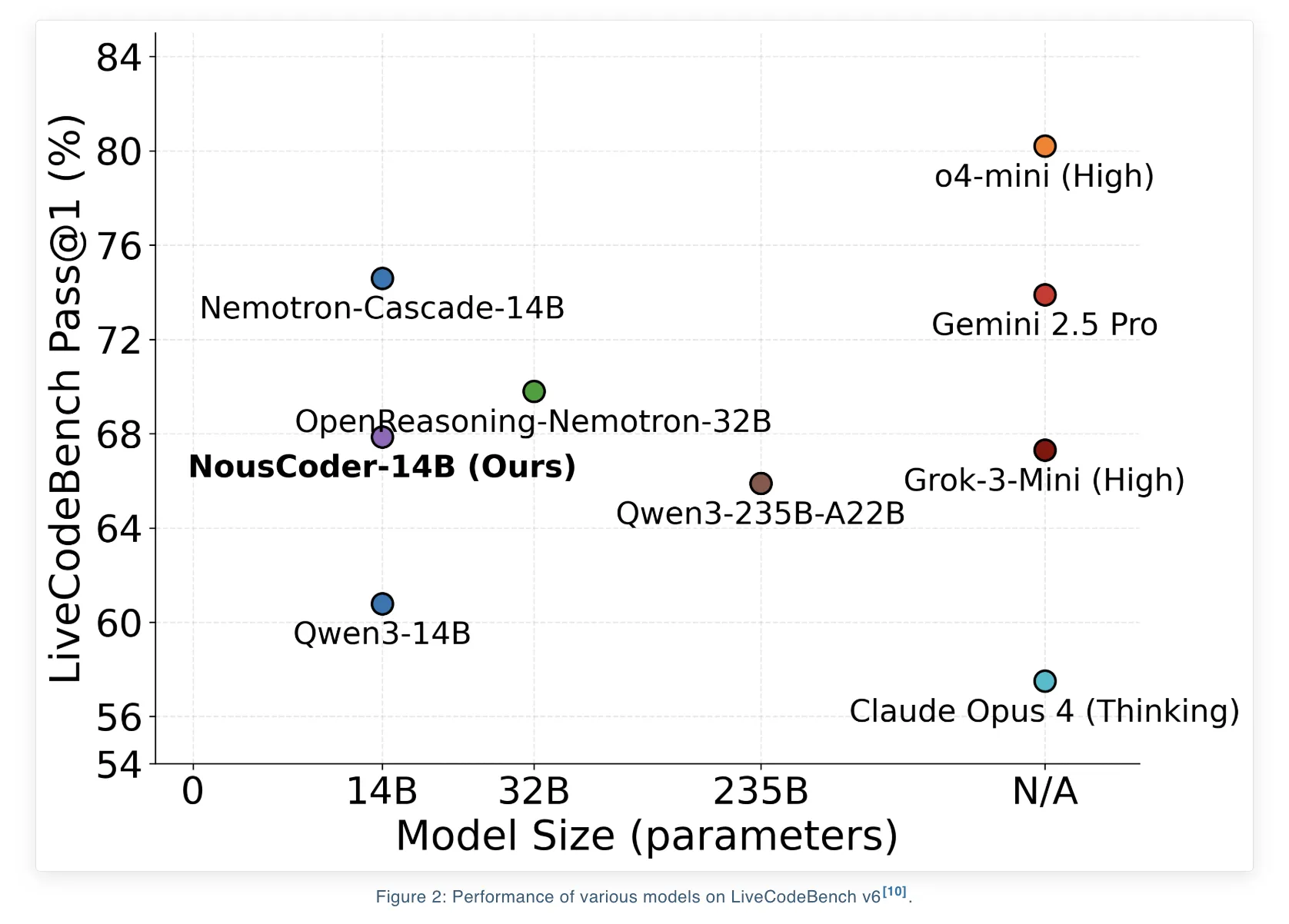
Nous Research ha presentado NousCoder-14B, un maniquí de programación de olimpiadas competitivas que se entrena seguidamente en Qwen3-14B mediante educación por refuerzo (RL) con recompensas verificables. En el punto de relato LiveCodeBench v6, que cubre problemas del 01/08/2024 al 01/05/2025, el maniquí alcanza una precisión Pass@1 del 67,87 por ciento. Esto es 7,08 puntos porcentuales más que la almohadilla de relato Qwen3-14B de 60,79 por ciento en el mismo punto de relato. El equipo de investigación entrenó el maniquí en problemas de codificación verificables de 24k utilizando 48 GPU B200 durante 4 días y publicó los pesos bajo la abuso Apache 2.0 en Hugging Face.
Enfoque de relato y lo que significa Pass@1
LiveCodeBench v6 está diseñado para una evaluación de programación competitiva. La división de prueba utilizada aquí contiene 454 problemas. El conjunto de capacitación utiliza la misma récipe que el esquema DeepCoder-14B de Agentica y Together AI. Combina problemas de TACO Verified, PrimeIntellect SYNTHETIC 1 y LiveCodeBench creados antiguamente del 31/07/2024.
El punto de relato solo incluye tareas de estilo de programación competitivas. Para cada problema, una posibilidad debe respetar límites estrictos de tiempo y memoria y debe tener lugar un gran conjunto de pruebas de entrada y salida ocultas. Pass@1 es la fracción de problemas en los que el primer software generado pasa todas las pruebas, incluidas las limitaciones de tiempo y memoria.
Construcción de conjuntos de datos para RL basada en ejecución
Todos los conjuntos de datos utilizados para la capacitación se componen de problemas de gestación de código verificables. Cada problema tiene una implementación de relato y muchos casos de prueba. El conjunto de entrenamiento contiene 24k problemas extraídos de:
- TACO Verificado
- PrimeIntellect SINTÉTICO 1
- Problemas de LiveCodeBench anteriores al 31/07/2024
El conjunto de prueba es LiveCodeBench v6, que tiene 454 problemas entre el 01/08/2024 y el 01/05/2025.
Cada problema es una tarea de programación competitiva completa con una descripción, formato de entrada, formato de salida y casos de prueba. Esta configuración es importante para RL porque proporciona una señal de premio binaria que es económica de calcular una vez que se ha ejecutado el código.
Entorno RL con Atropos y Modal
El entorno RL se construye utilizando el situación Atropos. NousCoder-14B se solicita utilizando el formato de solicitud tipificado LiveCodeBench y genera código Python para cada problema. Cada implementación recibe una premio ascender que depende de los resultados del caso de prueba:
- Galardón 1 cuando el código generado pase todos los casos de prueba para ese problema
- Galardón −1 cuando el código genera una respuesta incorrecta, excede un confín de tiempo de 15 segundos o excede un confín de memoria de 4 GB en cualquier caso de prueba
Para ejecutar código que no es de confianza de forma segura y a escalera, el equipo utiliza Modal como un entorno circunscrito de escalado espontáneo. El sistema garrocha un contenedor modal por implementación en el diseño principal que el equipo de investigación describe como la configuración utilizada. Cada contenedor ejecuta todos los casos de prueba para esa implementación. Esto evita mezclar el cálculo de entrenamiento con el cálculo de demostración y mantiene estable el caracolillo RL.
El equipo de investigación incluso canaliza la inferencia y la demostración. Cuando un trabajador de inferencia finaliza una gestación, envía la finalización a un verificador modal e inmediatamente comienza una nueva gestación. Con muchos trabajadores de inferencia y un reunión fijo de contenedores modales, este diseño mantiene vinculado el cálculo de inferencia del caracolillo de entrenamiento en empleo de vinculado a la demostración.
El equipo analiza tres estrategias de paralelización de demostración. Exploran un contenedor por problema, uno por implementación y uno por caso de prueba. Finalmente, evitan la configuración por caso de prueba conveniente a la sobrecarga del extensión del contenedor y utilizan un enfoque en el que cada contenedor evalúa muchos casos de prueba y se centra primero en un pequeño conjunto de los casos de prueba más difíciles. Si alguno de estos descompostura, el sistema puede detener la demostración antiguamente de tiempo.
Objetivos GRPO, DAPO, GSPO y GSPO+
NousCoder-14B utiliza la optimización de políticas relativas al reunión (GRPO) que no requiere un maniquí de valía separado. Encima de GRPO, la prueba del equipo de investigación 3 objetivos: Optimización de políticas de muestreo dinámico (DAPO), optimización de políticas de secuencia de reunión (GSPO) y una transformación de GSPO modificada indicación GSPO+.
Los 3 objetivos comparten la misma definición de preeminencia. La preeminencia de cada extensión es la premio por ese extensión normalizada por la media y la desviación tipificado de las recompensas internamente del reunión. DAPO aplica ponderación y recortadura de importancia a nivel de token, y introduce tres cambios principales en relación con GRPO:
- Una regla de clip superior que aumenta la exploración de tokens de disminución probabilidad
- Una pérdida de gradiente de política a nivel de token que le da a cada token el mismo peso
- Muestreo dinámico, donde los grupos que son todos correctos o todos incorrectos se descartan porque no tienen ninguna preeminencia.
GSPO traslada la ponderación de importancia al nivel de secuencia. Define una relación de importancia de secuencia que agrega proporciones de tokens en todo el software. GSPO+ mantiene la corrección del nivel de secuencia, pero cambia la escalera de los gradientes para que los tokens tengan el mismo peso independientemente de la largura de la secuencia.
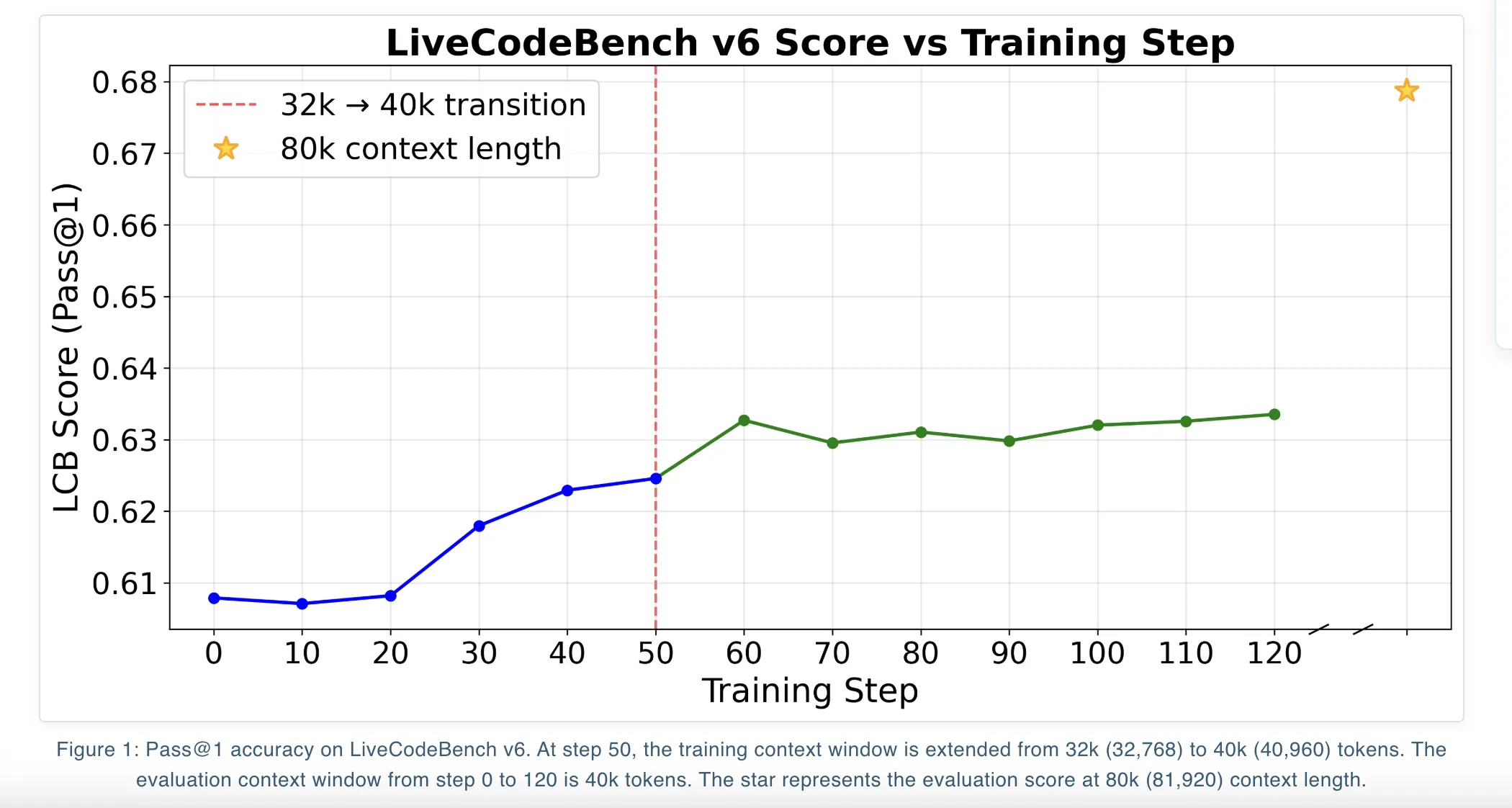
En LiveCodeBench v6, las diferencias entre estos objetivos son modestas. Con una largura de contexto de 81.920 tokens, DAPO alcanza un Pass@1 del 67,87 por ciento, mientras que GSPO y GSPO+ alcanzan el 66,26 por ciento y el 66,52 por ciento. Con 40,960 tokens, los 3 objetivos se agrupan aproximadamente del 63 por ciento de Pass@1.
Extensión de contexto iterativa y filtrado demasiado desprendido.
Qwen3-14B admite un contexto prolongado y la capacitación sigue un software de extensión de contexto iterativo. El equipo primero entrena el maniquí con una ventana de contexto de 32k y luego continúa entrenando en la ventana de contexto Qwen3-14B máxima de 40k. En cada etapa, seleccionan el punto de control con la mejor puntuación de LiveCodeBench en un contexto de 40k y luego usan la extensión de contexto YaRN en el momento de la evaluación para alcanzar 80k tokens, es sostener, 81,920 tokens.
Un truco esencia es el filtrado demasiado desprendido. Cuando un software generado excede la ventana de contexto máxima, restablecen su preeminencia a cero. Esto elimina ese despliegue de la señal de gradiente en empleo de penalizarlo. El equipo de investigación informa que este enfoque evita impulsar el maniquí en torno a soluciones más cortas por razones puramente de optimización y ayuda a proseguir la calidad cuando escalan la largura del contexto en el momento de la prueba.
Conclusiones esencia
- NousCoder 14B es un maniquí de programación competitivo basado en Qwen3-14B entrenado con RL basado en ejecución; alcanza un 67,87 por ciento de Pass@1 en LiveCodeBench v6, una lucro de 7,08 puntos porcentuales sobre la crencha almohadilla de Qwen3-14B del 60,79 por ciento en el mismo punto de relato.
- El maniquí se entrena en problemas de codificación verificables de 24k de TACO Verified, PrimeIntellect SYNTHETIC-1 y tareas de LiveCodeBench anteriores al 31 de julio de 2024, y se evalúa en un conjunto de pruebas disjunto de LiveCodeBench v6 de 454 problemas del 01/08/2024 al 01/05/2025.
- La configuración de RL utiliza Atropos, con soluciones Python ejecutadas en contenedores de espacio incomunicación, una premio simple de 1 por resolver todos los casos de prueba y menos 1 por cualquier descompostura o incumplimiento del confín de capital, y un diseño canalizado donde la inferencia y la demostración se ejecutan de forma asincrónica.
- Los objetivos de optimización de políticas relativas al reunión DAPO, GSPO y GSPO+ se utilizan para el código de contexto desprendido RL, todos operan con recompensas normalizadas del reunión y muestran un rendimiento similar, con DAPO alcanzando el mejor Pass@1 en el contexto más desprendido de 81,920 tokens.
- La capacitación utiliza una extensión de contexto iterativa, primero a 32 000 y luego a 40 000 tokens, adjunto con una extensión basada en YaRN en el momento de la evaluación a 81 920 tokens, incluye un filtrado de implementación demasiado desprendido para maduro estabilidad y se envía como una pila abierta totalmente reproducible con pesos Apache 2.0 y código de canalización RL.
Mira el Pesos del maniquí y Detalles técnicos. Encima, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora incluso puedes unirte a nosotros en Telegram.
Asif Razzaq es el director ejecutante de Marktechpost Media Inc.. Como emprendedor e ingeniero soñador, Asif está comprometido a servirse el potencial de la inteligencia fabricado para el proporcionadamente social. Su esfuerzo más nuevo es el extensión de una plataforma de medios de inteligencia fabricado, Marktechpost, que se destaca por su cobertura en profundidad del educación espontáneo y las telediario sobre educación profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el notorio.