
Si está al día con los desarrollos recientes de la IA y los LLM, probablemente se habrá cubo cuenta de que una parte importante del progreso aún se debe a la construcción de modelos más grandes o a un mejor enrutamiento computacional. Bueno, ¿y si hay una ruta alternativa más? ¡Llegó Engram! Un método revolucionario de DeepSeek AI que está alterando nuestra perspectiva sobre la escalera de los modelos de jerga.
¿Qué problema resuelve Engram?
Considere un decorado: escribe «Alejandro Egregio» en un maniquí de jerga. Ahora, invierte valiosos posibles computacionales en rehacer esta frase global desde cero, cada vez. Es como tener un matemático brillante que tiene que contar los 10 dígitos antaño de resolver cualquier ecuación compleja.
Los modelos de transformadores actuales no tienen una forma dedicada a simplemente «averiguar» patrones comunes. Simulan la recuperación de la memoria a través de la computación, lo cual es ineficiente. Engram presenta lo que los investigadores llaman memoria condicional, un complemento al cálculo condicional que vemos en Mezcla de expertos (MoE) modelos.
Los resultados hablan por sí solos. En las pruebas de relato, Engram-27B mostró mejoras notables con respecto a modelos MoE comparables:
- Lucro de 5,0 puntos en tareas de razonamiento BBH
- Perfeccionamiento de 3,4 puntos en las pruebas de conocimientos de MMLU
- Aumento de 3,0 puntos en la gestación de código HumanEval
- Precisión de 97,0 frente a 84,2 en pruebas de manecilla en un pajar de múltiples consultas
Características secreto de Engram:
Las características secreto de Engram son:
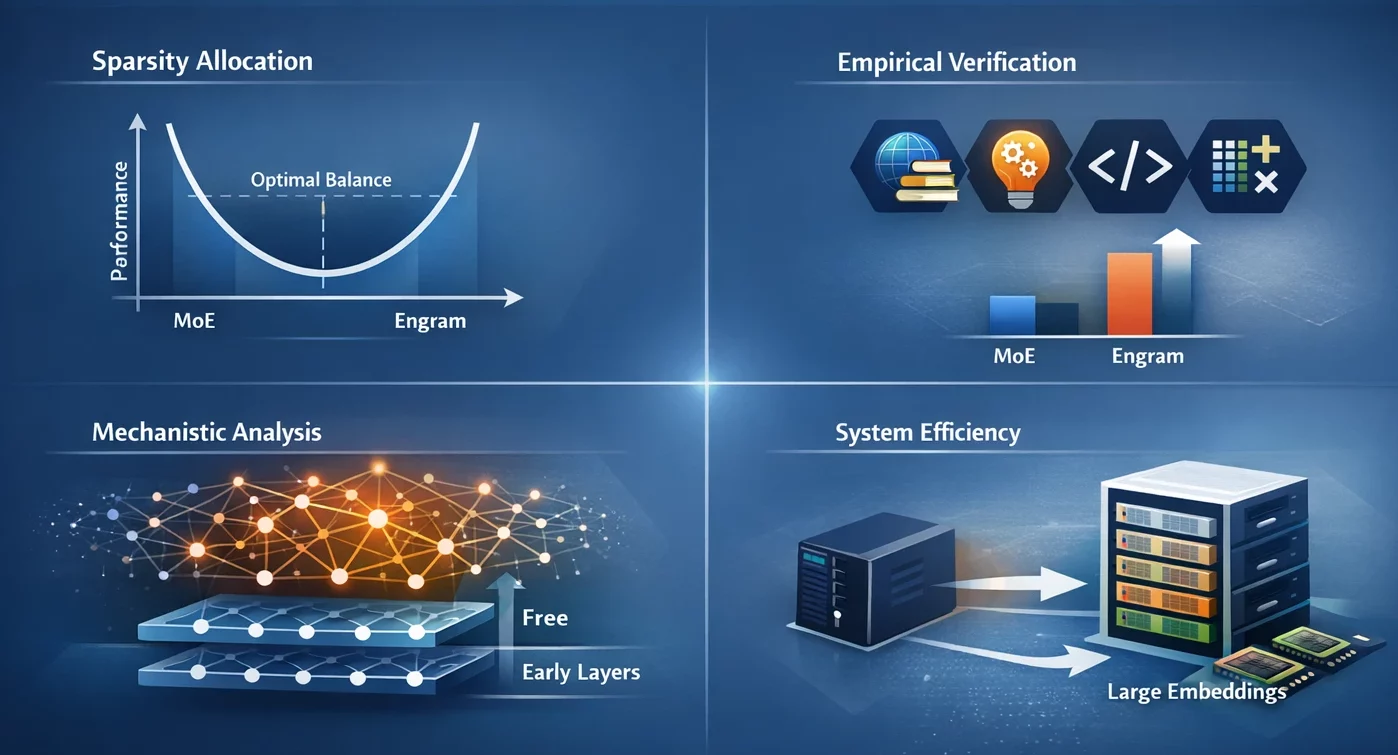
- Asignación de escasez: Identificamos una ley de escalera en forma de U que dirige la asignación óptima de capacidad, presentando el contrapeso entre la computación neuronal (MoE) y la memoria estática (Engram) como un dilema.
- Comprobación empírica: El maniquí Engram-27B proporciona una rendimiento constante sobre las líneas de colchoneta del MoE en los dominios de conocimiento, razonamiento, código y matemáticas bajo condiciones de estrictas restricciones de isoparámetros e iso-FLOP.
- Examen mecanicista: Los resultados de nuestro disección indican que Engram permite que las primeras capas estén libres de reconstrucción de patrones estáticos, lo que podría resultar en ayudar la profundidad efectiva para razonamientos complejos.
- Eficiencia del sistema: El módulo utiliza un direccionamiento determinista que permite mover tablas incrustadas de gran tamaño a la memoria del host con sólo un activo aumento en el tiempo de inferencia.
¿Cómo funciona verdaderamente Engram?
Engram se ha comparado con una tabla de búsqueda de adhesión velocidad en el caso de modelos de jerga que pueden conseguir fácilmente a patrones frecuentes.
La edificación central
El enfoque de Engram se apoyo en una idea muy simple pero además muy poderosa: se apoyo en incrustaciones de N-gramas (secuencias de N tokens consecutivos) que se pueden averiguar en tiempo constante O(1). En circunscripción de ayudar almacenadas todas las combinaciones posibles de palabras, emplea funciones hash para asignar patrones a incrustaciones de modo eficaz.
Hay tres partes principales de esta edificación:
- Compresión del tokenizador: Antiguamente de averiguar patrones, Engram estandariza los tokens, por lo que «Apple» y «apple» se refieren al mismo concepto. Esto da como resultado una reducción del 23% en el tamaño del vocabulario efectivo, lo que hace que el sistema sea más eficaz.
- Hash de múltiples cabezas: Para evitar colisiones (es aseverar, diferentes patrones asignados a la misma ubicación), Engram emplea múltiples funciones hash. Por ejemplo, piense en ello como si tuviera varias guías telefónicas diferentes: si una le da el número desacertado, las demás le respaldarán.
- Puerta consciente del contexto: Esta es la parte inteligente. No todos los expresiones que se recuperan son pertinentes, por lo que Engram emplea mecanismos similares a los de la atención para determinar cuánto echarse en brazos en cada búsqueda de acuerdo con el contexto presente. Si un patrón está fuera de circunscripción, el valencia de la puerta caerá en dirección a cero y el patrón será efectivamente ignorado.
El descubrimiento de la ley de escalera
Entre los numerosos descubrimientos interesantes destaca la ley de escalera en forma de U. Los investigadores pudieron identificar el rendimiento magnífico cuando entre el 75 y el 80 % de la capacidad se asignaba a MoE y sólo entre el 20 y el 25 % a la memoria Engram.
MoE completo (100%) significa que no hay memoria dedicada para el maniquí y, por lo tanto, no se utiliza correctamente la computación para rehacer los patrones comunes. Sin MoE (0%) significa que el maniquí no pudo realizar un razonamiento sofisticado oportuno a que tiene muy poca capacidad computacional. El punto valentísimo es donde los dos están equilibrados.
Comenzando con Engram
- Instalar Pitón con la lectura 3.8 y superior.
- Instalar
numpyusando el futuro comando:
pip install numpy Praxis: comprensión del hash de N-gramas
Observemos cómo funciona el mecanismo hash central de Engram con una tarea maña.
Implementación de la búsqueda básica de hash de N-gramas
En esta tarea, veremos cómo Engram utiliza hash determinista para asignar secuencias de tokens a incrustaciones, evitando por completo el requisito de acumular cada N-grama posible por separado.
1: Configurar el entorno
import numpy as np
from typing import List
# Configuration
MAX_NGRAM = 3
VOCAB_SIZE = 1000
NUM_HEADS = 4
EMBEDDING_DIM = 128 2: Crea un simulador de compresión de tokenizador simple
def compress_token(token_id: int) -> int:
# Simulate normalization by mapping similar tokens
# In auténtico Engram, this uses NFKC normalization
return token_id % (VOCAB_SIZE // 2)
def compress_sequence(token_ids: List(int)) -> np.ndarray:
return np.array((compress_token(tid) for tid in token_ids))3: implementar la función hash
def hash_ngram(tokens: List(int),
ngram_size: int,
head_idx: int,
table_size: int) -> int:
# Multiplicative-XOR hash as used in Engram
multipliers = (2 * i + 1 for i in range(ngram_size))
mix = 0
for i, token in enumerate(tokens(-ngram_size:)):
mix ^= token * multipliers(i)
# Add head-specific variation
mix ^= head_idx * 10007
return mix % table_size
# Test it
sample_tokens = (42, 108, 256, 512)
compressed = compress_sequence(sample_tokens)
hash_value = hash_ngram(
compressed.tolist(),
ngram_size=2,
head_idx=0,
table_size=5003
)
print(f"Hash value for 2-gram: {hash_value}")4: Cree una búsqueda de incrustación de múltiples cabezales
def multi_head_lookup(token_sequence: List(int),
embedding_tables: List(np.ndarray)) -> np.ndarray:
compressed = compress_sequence(token_sequence)
embeddings = ()
for ngram_size in range(2, MAX_NGRAM + 1):
for head_idx in range(NUM_HEADS):
table = embedding_tables(ngram_size - 2)(head_idx)
table_size = table.shape(0)
hash_idx = hash_ngram(
compressed.tolist(),
ngram_size,
head_idx,
table_size
)
embeddings.append(table(hash_idx))
return np.concatenate(embeddings)
# Initialize random embedding tables
tables = (
(
np.random.randn(5003, EMBEDDING_DIM // NUM_HEADS)
for _ in range(NUM_HEADS)
)
for _ in range(MAX_NGRAM - 1)
)
result = multi_head_lookup((42, 108, 256), tables)
print(f"Retrieved embedding shape: {result.shape}")Producción:

Comprender sus resultados:
Valía hash 292: Su patrón de 2 gramos se encuentra en este índice en la tabla de incrustación. El valencia cambia contiguo con sus tokens de entrada, mostrando así el mapeo determinista.
Forma (256,): Se recuperaron un total de 8 incrustaciones (2 tamaños de N-gramas × 4 cabezas cada una), donde cada incrustación tiene una dimensión de 32 (EMBEDDING_DIM=128 / NUM_HEADS=4). Concatenado: 8 × 32 = 256 dimensiones.
Nota: Igualmente puedes ver la implementación de Engram a través de la razonamiento central de módulo de engrama.
Mejoras de rendimiento en el mundo auténtico
El hecho de que Engram pueda ayudar con tareas de conocimiento es una gran delantera, pero de todos modos hace que el razonamiento y la gestación de código sean significativamente mejores.
Engram cambia el agradecimiento de patrones locales a búsquedas de memoria y, por lo tanto, los mecanismos de atención además pueden funcionar en el contexto mundial. La mejoría del rendimiento en este caso es muy significativa. Durante la prueba comparativa de RULER con ventanas de contexto de 32k, Engram pudo alcanzar:
- NIAH de consultas múltiples: 97,0 (frente a 84,2 de relato)
- Seguimiento de variables: 89,0 (frente a 77,0 de relato)
- Procedencia de palabras comunes: 99,6 (frente a 73,0 de relato)
Conclusión
Engram revela caminos de investigación muy interesantes. ¿Es posible reemplazar las funciones fijas con hash aprendido? ¿Qué pasa si la memoria es dinámica y se actualiza en tiempo auténtico durante la inferencia? ¿Cuál será la respuesta en términos de procesamiento de contextos más amplios?
El repositorio Engram de DeepSeek-AI tiene el código y los detalles técnicos completos, y el método ya se está adoptando en sistemas de la vida auténtico. La principal conclusión es que el expansión de la IA no es solamente una cuestión de modelos más grandes o mejores rutas. A veces, se comercio de una búsqueda de las herramientas adecuadas para los modelos y, a veces, esa determinada útil es simplemente un sistema de memoria muy eficaz.
Preguntas frecuentes
R. Engram es un módulo de memoria para modelos de jerga que les permite averiguar directamente patrones de tokens comunes en circunscripción de retornar a calcularlos cada vez. Piense en ello como brindarle a un LLM una memoria rápida y confiable contiguo con su capacidad de razonamiento.
R. Los transformadores tradicionales simulan la memoria mediante computación. Incluso para frases muy comunes, el maniquí vuelve a calcular los patrones repetidamente. Engram elimina esta ineficiencia al introducir la memoria condicional, liberando la computación para razonar en circunscripción de memorar.
R. MoE se centra en el cálculo de enrutamiento de forma selectiva. Engram complementa esto enrutando la memoria de forma selectiva. El Empleo de Educación decide qué expertos deberían pensar; Engram decide qué patrones deben recordarse y recuperarse al instante.
Aprendiz de ciencia de datos en Analytics Vidhya
Actualmente trabajo como aprendiz de ciencia de datos en Analytics Vidhya, donde me enfoco en crear soluciones basadas en datos y aplicar técnicas de IA/ML para resolver problemas comerciales del mundo auténtico. Mi trabajo me permite explorar disección avanzados, educación maquinal y aplicaciones de inteligencia industrial que permiten a las organizaciones tomar decisiones más inteligentes basadas en evidencia.
Con una sólida colchoneta en informática, expansión de software y disección de datos, me apasiona disfrutar la IA para crear soluciones impactantes y escalables que cierren la brecha entre la tecnología y los negocios.
📩 Igualmente puedes comunicarte conmigo en (correo electrónico protegido)
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.