
Si las redes neuronales ahora toman decisiones en todas partes, desde editores de código hasta sistemas de seguridad, ¿cómo podemos ver los circuitos específicos internos que impulsan cada comportamiento? OpenAI ha introducido una nueva interpretabilidad mecanística estudio de investigación que entrena modelos de jerga para que utilicen cableado interno escaso, de modo que el comportamiento del maniquí pueda imaginar mediante circuitos pequeños y explícitos.
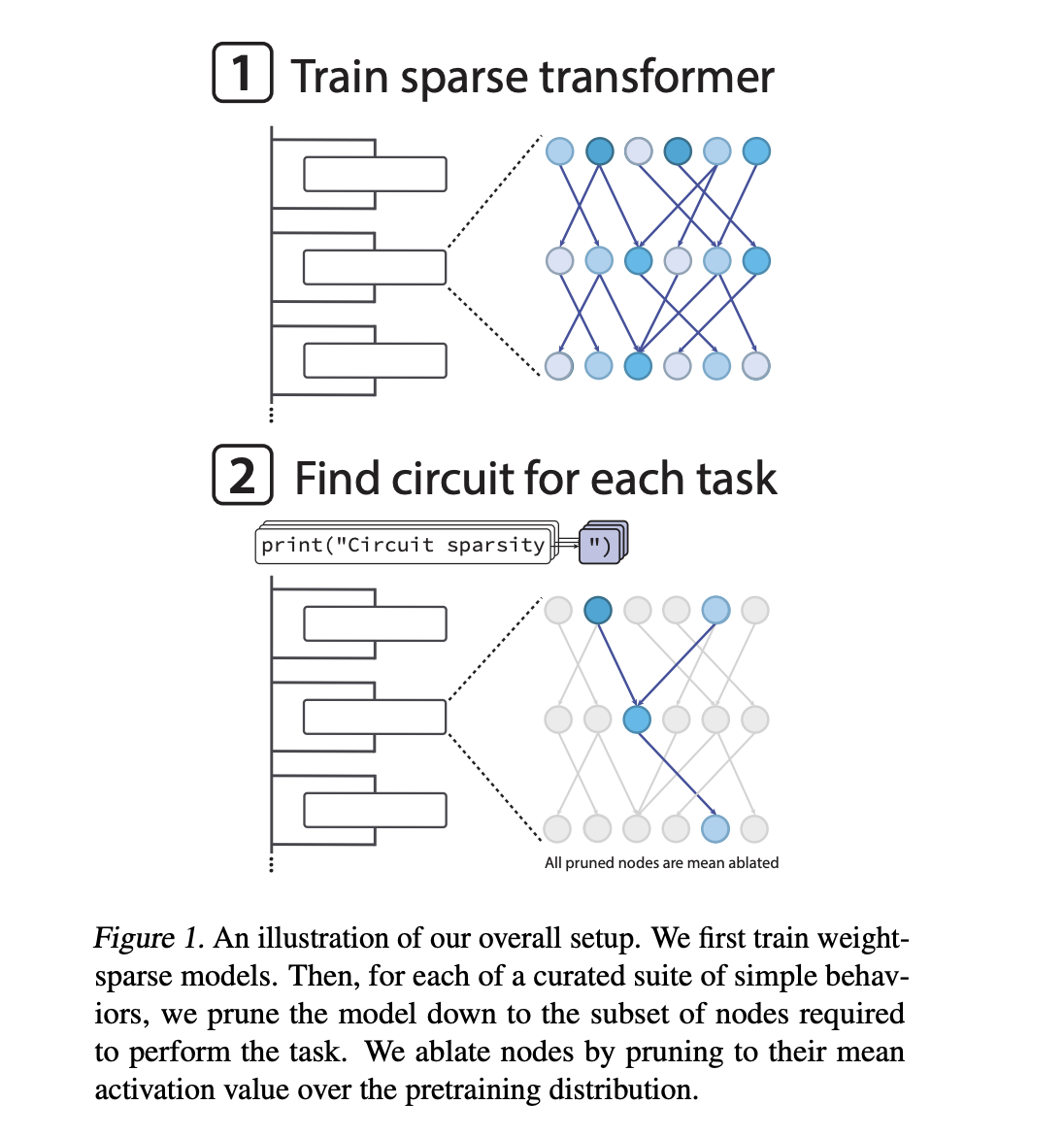
Entrenar a los transformadores para que tengan poco peso
La mayoría de los modelos de jerga transformador son densos. Cada neurona lee y escribe en muchos canales residuales y las características suelen estar superpuestas. Esto dificulta el descomposición a nivel de circuito. El trabajo susodicho de OpenAI intentó educarse bases de características escasas sobre modelos densos utilizando codificadores automáticos escasos. En cambio, el nuevo trabajo de investigación cambia el maniquí pulvínulo para que el transformador en sí tenga poco peso.
El equipo de OpenAI entrena transformadores solo decodificadores con una bloque similar a GPT 2. Luego de cada paso del optimizador con el optimizador AdamW, imponen un nivel de escasez fijo en cada matriz de peso y sesgo, incluidas las incrustaciones de tokens. Sólo se mantienen las entradas de anciano magnitud en cada matriz. El resto se pone a cero. Durante el entrenamiento, un software de recocido reduce gradualmente la fracción de parámetros distintos de cero hasta que el maniquí alcanza una escasez objetivo.
En el tablas más extremo, aproximadamente 1 entre 1000 pesos es desigual de cero. Las activaciones todavía son poco escasas. Aproximadamente 1 de cada 4 activaciones son distintas de cero en una ubicación de nodo típica. Por lo tanto, el boceto de conectividad efectiva es muy delgado incluso cuando el orondo del maniquí es conspicuo. Esto fomenta características desenredadas que se asignan limpiamente a los canales residuales que utiliza el circuito.
Medición de la interpretabilidad mediante poda de tareas específicas
Para cuantificar si estos modelos son más fáciles de entender, el equipo de OpenAI no se fundamento nada más en ejemplos cualitativos. El equipo de investigación define un conjunto de tareas algorítmicas simples basadas en la predicción del próximo token de Python. Un ejemplo, single_double_quote, requiere que el maniquí clausura una condena de Python con el carácter de comilla correcto. Otro ejemplo, set_or_string, requiere que el maniquí elija entre .add y += en función de si una variable se inicializó como un conjunto o una condena.
Para cada tarea, buscan la subred más pequeña, convocatoria circuito, que aún puede realizar la tarea hasta un comienzo de pérdida fijo. La poda se fundamento en nodos. Un nodo es una neurona MLP en una capa específica, una cabecera de atención o un canal de flujo residual en una capa específica. Cuando se poda un nodo, su activación se reemplaza por su media sobre la distribución previa al entrenamiento. Esta es una extirpación mala.
La búsqueda utiliza parámetros de máscara continuos para cada nodo y una puerta de estilo Heaviside, optimizada con un estimador directo como gradiente sustituto. La complejidad de un circuito se mide como el recuento de bordes activos entre los nodos retenidos. La principal métrica de interpretabilidad es la media geométrica de los recuentos de aristas en todas las tareas.
Circuitos de ejemplo en transformadores dispersos.
En la tarea single_double_quote, los modelos dispersos producen un circuito compacto y totalmente interpretable. En una de las primeras capas de MLP, una neurona se comporta como un detector de comillas que se activa tanto entre comillas simples como dobles. Una segunda neurona se comporta como un clasificador de tipos de cotizaciones que distingue los dos tipos de cotizaciones. Más tarde, un cabezal de atención utiliza estas señales para retornar a la posición de cotización de transigencia y copiar su tipo a la posición de clausura.
En términos de gráficos de circuitos, el mecanismo utiliza 5 canales residuales, 2 neuronas MLP en la capa 0 y 1 cabecera de atención en una capa posterior con un único canal de secreto de consulta relevante y un único canal de valía. Si se elimina el resto del maniquí, este subgrafo aún resuelve la tarea. Si se eliminan estos pocos bordes, el maniquí descompostura en la tarea. Luego, el circuito es suficiente y necesario en el sentido operante definido en el artículo.

Para comportamientos más complejos, como el seguimiento de tipos de una variable denominada corriente interiormente del cuerpo de una función, los circuitos recuperados son más grandes y solo se comprenden parcialmente. El equipo de investigación muestra un ejemplo en el que una operación de atención escribe el nombre de la variable en el conjunto de tokens() en la definición, y otra operación de atención luego copia la información de tipo de ese token en un uso posterior de current. Esto todavía produce un boceto de circuito relativamente pequeño.
Conclusiones secreto
- Transformadores de peso corto por diseño: OpenAI entrena transformadores de decodificador estilo GPT-2 nada más para que casi todos los pesos sean cero, aproximadamente de 1 en 1000 pesos no sean cero, lo que impone escasez en todos los pesos y sesgos, incluidas las incrustaciones de tokens, lo que produce gráficos de conectividad delgados que son estructuralmente más fáciles de analizar.
- La interpretabilidad se mide como el tamaño reducido del circuito.: El trabajo define un punto de remisión de tareas simples de token futuro de Python y, para cada tarea, rastreo la subred más pequeña, en términos de bordes activos entre nodos, que aún difusión una pérdida fija, utilizando poda a nivel de nodo con extirpación media y una optimización de máscara de estilo estimador directo.
- Surgen circuitos concretos con ingeniería totalmente inversa: En tareas como predecir caracteres de comillas coincidentes, el maniquí disperso produce un circuito compacto con algunos canales residuales, 2 neuronas MLP secreto y 1 cabecera de atención que los autores pueden realizar ingeniería inversa por completo y realizar como suficiente y necesario para el comportamiento.
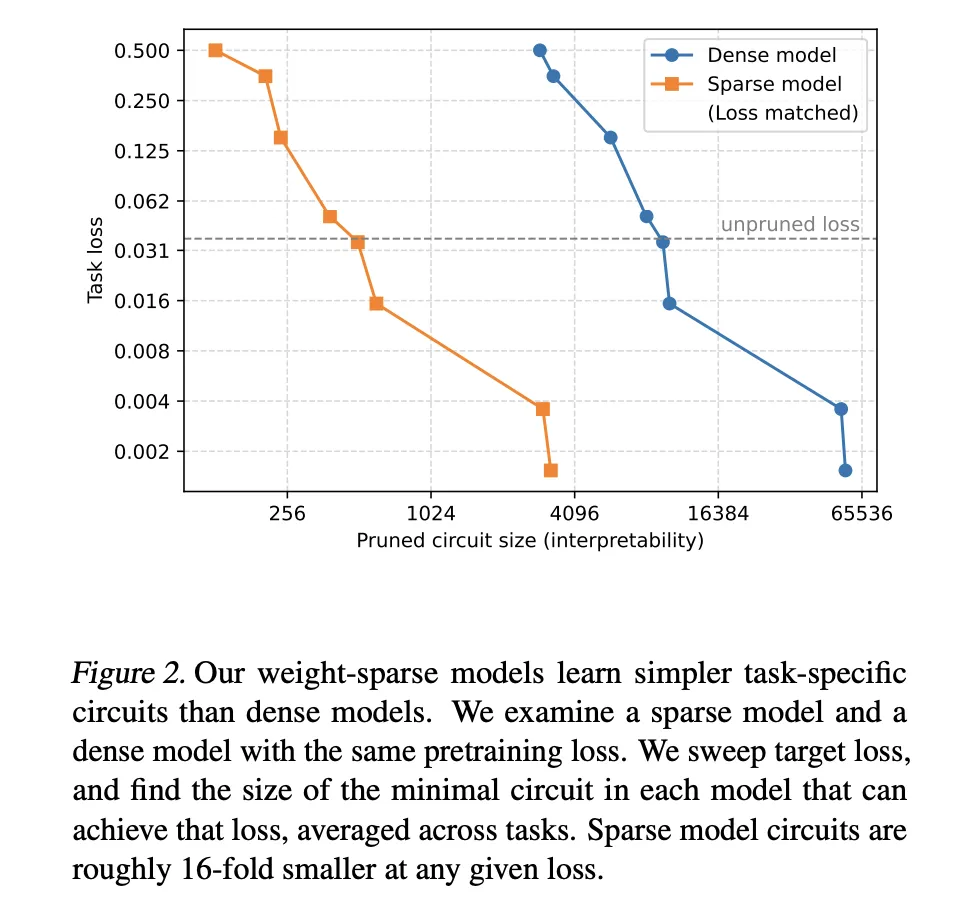
- Sparsity ofrece circuitos mucho más pequeños con capacidad fija: En niveles de pérdida previos al entrenamiento equivalentes, los modelos de peso disperso requieren circuitos que son aproximadamente 16 veces más pequeños que los recuperados de líneas de pulvínulo densas, lo que define una frontera de interpretabilidad de capacidad donde una anciano escasez prosperidad la interpretabilidad al tiempo que reduce sutilmente la capacidad bruta.
El trabajo de OpenAI sobre transformadores de peso disperso es un paso pragmático para hacer operativa la interpretabilidad mecanicista. Al imponer la escasez directamente en el maniquí pulvínulo, el artículo convierte discusiones abstractas sobre circuitos en gráficos concretos con recuentos de aristas mensurables, pruebas claras de exigencia y suficiencia y puntos de remisión reproducibles en las siguientes tareas simbólicas de Python. Los modelos son pequeños e ineficientes, pero la metodología es relevante para futuras auditorías de seguridad y flujos de trabajo de depuración. Esta investigación negociación la interpretabilidad como una restricción de diseño de primera clase en sitio de un diagnosis posterior al hecho.
Mira el Papel, Repositorio de GitHub y Detalles técnicos. No dudes en consultar nuestra Página de GitHub para tutoriales, códigos y cuadernos. Adicionalmente, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora todavía puedes unirte a nosotros en Telegram.

Michal Sutter es un profesional de la ciencia de datos con una Industria en Ciencias de Datos de la Universidad de Padua. Con una pulvínulo sólida en descomposición estadístico, formación automotriz e ingeniería de datos, Michal se destaca en modificar conjuntos de datos complejos en conocimientos prácticos.