
Las instituciones de IA desarrollan modelos heterogéneos para tareas específicas, pero enfrentan desafíos de escasez de datos durante la capacitación. El educación federado tradicional (FL) respalda solo la colaboración del maniquí homogéneo, que necesita arquitecturas idénticas en todos los clientes. Sin bloqueo, los clientes desarrollan arquitecturas maniquí para sus requisitos únicos. Por otra parte, compartir modelos con capacitación lugar intensiva en esfuerzo contiene propiedad intelectual y reduce el interés de los participantes en participar en colaboraciones. El educación federado heterogéneo (HTFL) aborda estas limitaciones, pero la humanidades carece de un punto de remisión unificado para evaluar HTFL en varios dominios y aspectos.
Referencias y categorías de métodos HTFL
Los puntos de remisión de FL existentes se centran en la heterogeneidad de los datos utilizando modelos de clientes homogéneos pero descuidan escenarios reales que involucran la heterogeneidad del maniquí. Los métodos representativos de HTFL se dividen en tres categorías principales que abordan estas limitaciones. Métodos de intercambio de parámetros parciales como LG-FEDAVG, FEDGEN y FEDGH mantienen extractores de características heterogéneas, al tiempo que asume cabezas de clasificación homogéneas para la transferencia de conocimiento. La destilación mutua, como FML, FedKD y FedMrl, entrena y comparte pequeños modelos auxiliares a través de técnicas de destilación. Los métodos de intercambio de prototipos transfieren prototipos livianos en clase como conocimiento total, recopilando prototipos locales de clientes y recolectándolos en servidores para orientar la capacitación lugar. Sin bloqueo, no está claro si los métodos HTFL existentes funcionan de modo consistente en diversos escenarios.
Inmersión de htfllib: un punto de remisión unificado
Investigadores de la Universidad de Shanghai Jiao Tong, la Universidad de Beihang, la Universidad de Chongqing, la Universidad de Tongji, la Universidad Politécnica de Hong Kong y la Universidad Queen’s University of Belfast han propuesto la primera biblioteca heterogénea de educación federado (HTFllib), un método casquivana y desplegable para integrar múltiples fechas y modelos de escenarios de heterogeneidad. Este método se integra:
- 12 conjuntos de datos en diversos dominios, modalidades y escenarios de heterogeneidad de datos
- 40 Arquitecturas de modelos que van desde pequeñas hasta grandes, en tres modalidades.
- Una colchoneta de código HTFL modularizada y casquivana de extender con implementaciones de 10 métodos HTFL representativos.
- Evaluaciones sistemáticas que cubren precisión, convergencia, costos de cálculo y costos de comunicación.
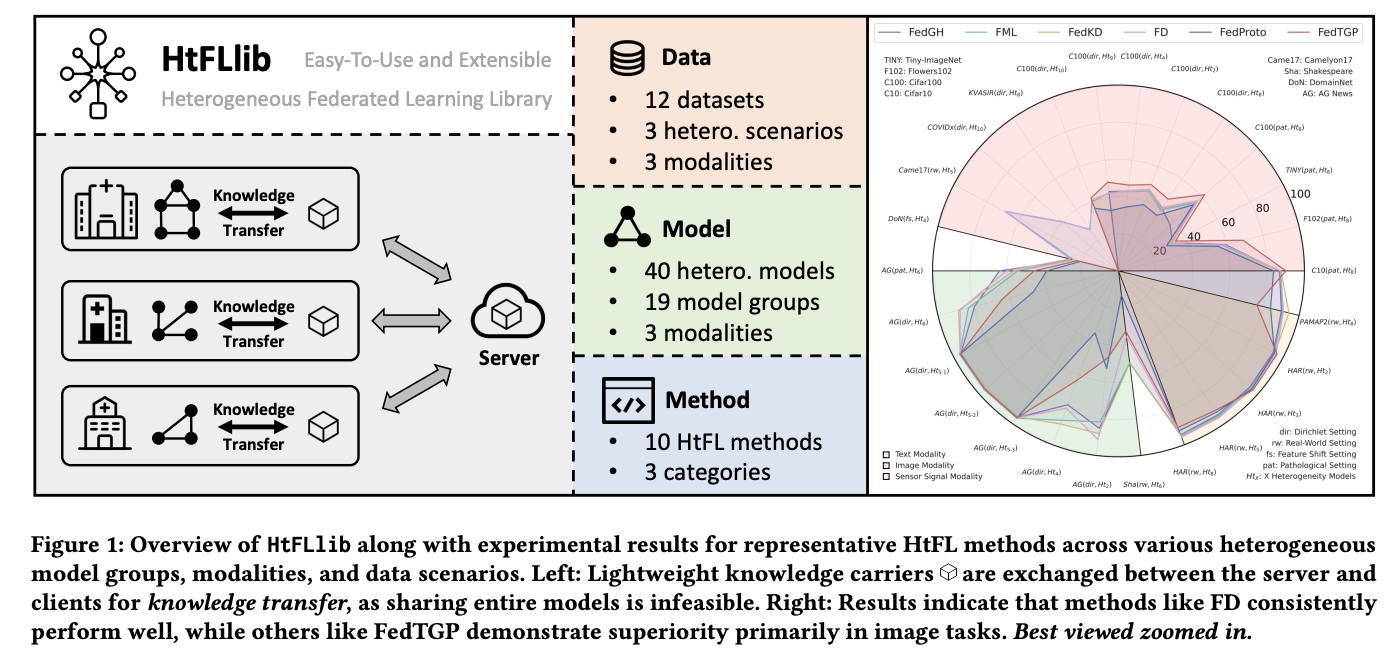
Conjuntos de datos y modalidades en htfllib
HTFLLIB contiene escenarios detallados de heterogeneidad de datos divididos en tres configuraciones: la formalidad sesgó con patológico y dirichlet como subsetts, cambio de características y mundo actual. Integra 12 conjuntos de datos, incluidos CIFAR10, CIFAR100, Flowers102, Tiny-Imagenet, Kvasir, Covidx, Domainnet, Camelyon17, AG News, Shakespeare, Har y Pamap2. Estos conjuntos de datos varían significativamente en el dominio, el cuerpo de datos y los números de clase, lo que demuestra la naturaleza integral y versátil de Htfllib. Por otra parte, el enfoque principal de los investigadores está en los datos de la imagen, especialmente en la configuración de sesgo de formalidad, ya que las tareas de imagen son las tareas más utilizadas en varios campos. Los métodos HTFL se evalúan en las tareas de imagen, texto y señal de sensor para evaluar sus respectivas fortalezas y debilidades.
Prospección de rendimiento: modalidad de imagen
Para los datos de la imagen, la mayoría de los métodos HTFL muestran una precisión disminuida a medida que aumenta la heterogeneidad del maniquí. El FEDMRL muestra una fuerza superior a través de su combinación de modelos globales y locales auxiliares. Al introducir clasificadores heterogéneos que hacen que los métodos parciales de intercambio de parámetros no sean aplicables, FEDTGP mantiene la superioridad en diversos entornos adecuado a su capacidad de refinamiento de prototipo adaptativo. Los experimentos de conjuntos de datos médicos con modelos heterogéneos previamente capacitados con caja negra demuestran que HTFL restablecimiento la calidad del maniquí en comparación con los modelos previamente capacitados y logra mayores mejoras que los modelos auxiliares, como FML. Para los datos de texto, las ventajas de FEDMRL en la configuración de sesgo de formalidad disminuyen en la configuración del mundo actual, mientras que FedProto y FedTGP funcionan relativamente mal en comparación con las tareas de imagen.
Conclusión
En conclusión, los investigadores introdujeron HTFllib, un entorno que aborda la brecha crítica en la evaluación comparativa de HTFL al proporcionar estándares de evaluación unificados en diversos dominios y escenarios. El diseño modular y la obra desplegable de HTFLLIB proporcionan un punto de remisión detallado tanto para la investigación como para las aplicaciones prácticas en HTFL. Por otra parte, su capacidad para apoyar modelos heterogéneos en el educación colaborativo abre el camino para futuras investigaciones sobre la utilización de modelos grandes pre-entrenados complejos, sistemas de caja negra y arquitecturas variadas en diferentes tareas y modalidades.
Mira el Papel y Página de Github. Todo el crédito por esta investigación va a los investigadores de este plan. Por otra parte, siéntete vacante de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.

Sajjad Ansari es un pregrado de postrer año de IIT Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA con un enfoque en comprender el impacto de las tecnologías de IA y sus implicaciones del mundo actual. Su objetivo es articular conceptos complejos de IA de modo clara y accesible.
