
El expansión de grandes modelos lingüísticos (LLM) se ha definido por la búsqueda de una escalera bruta. Si aceptablemente el aumento del número de parámetros en billones inicialmente impulsó ganancias de rendimiento, incluso introdujo importantes gastos generales de infraestructura y una utilidad insignificante decreciente. La exención del Serie de modelos medianos Qwen 3.5 señala un cambio en el enfoque Qwen de Alibaba, priorizando la eficiencia arquitectónica y los datos de inscripción calidad sobre el escalado tradicional.
La serie presenta una formación que incluye Qwen3.5-Flash, Qwen3.5-35B-A3B, Qwen3.5-122B-A10By Qwen3.5-27B. Estos modelos demuestran que las opciones arquitectónicas estratégicas y el estudios por refuerzo (RL) pueden alcanzar inteligencia de nivel fronterizo con requisitos informáticos significativamente menores.
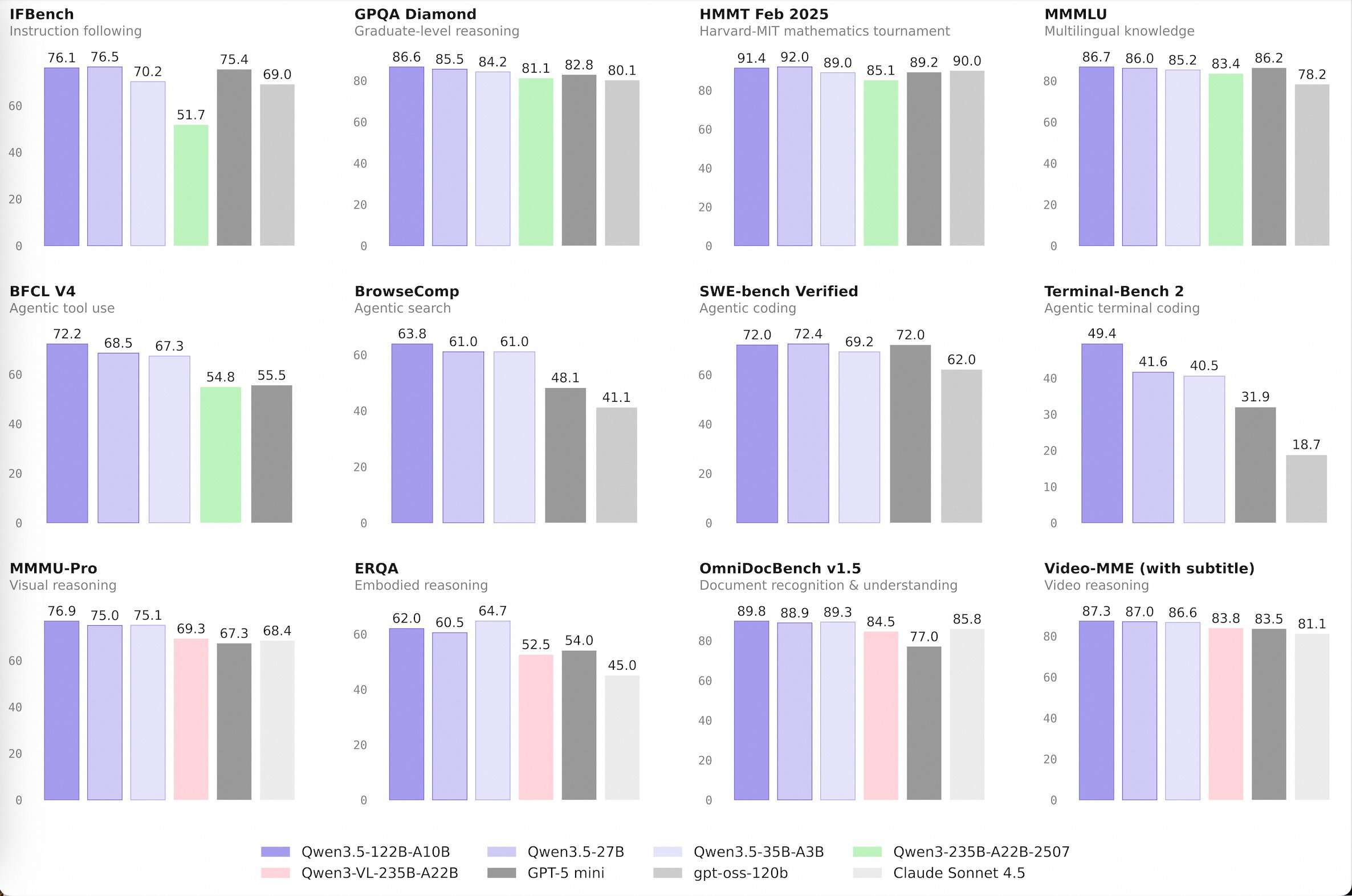
El avance en eficiencia: 35 mil millones superan a 235 mil millones
El hito técnico más destacable es la realización de Qwen3.5-35B-A3Bque ahora supera al inicial Qwen3-235B-A22B-2507 y la capacidad de visión Qwen3-VL-235B-A22B.
El sufijo ‘A3B’ es la métrica esencia. Esto indica el Parámetros activos en una construcción de mezcla de expertos (MoE). Aunque el maniquí tiene 35 mil millones de parámetros totales, solo activa 3 mil millones durante cualquier paso de inferencia. El hecho de que un maniquí con 3B de parámetros activos pueda pasar a un predecesor con 22B de parámetros activos pone de relieve un brinco importante en la densidad de razonamiento.
Esta eficiencia está impulsada por una construcción híbrida que integra Redes Delta cerradas (atención seguido) con bloques estereotipado de Atención Cerrada. Este diseño permite una decodificación de detención rendimiento y una huella de memoria escasa, lo que hace que la IA de detención rendimiento sea más accesible en hardware estereotipado.
Qwen3.5-Flash: Optimizado para producción
Qwen3.5-Flash sirve como la lectura de producción alojada del maniquí 35B-A3B. Está desarrollado específicamente para desarrolladores de software que requieren un rendimiento de desestimación latencia en flujos de trabajo agentes.
- Largo del contexto de 1M: Al proporcionar una ventana de contexto de 1 millón de tokens de forma predeterminada, Flash reduce la escazes de canales RAG (vivientes aumentada de recuperación) complejos cuando se manejan grandes conjuntos de documentos o bases de código.
- Herramientas oficiales integradas: El maniquí presenta soporte nativo para el uso de herramientas y llamadas de funciones, lo que le permite interactuar directamente con API y bases de datos con inscripción precisión.
Escenarios agentes de detención razonamiento
El Qwen3.5-122B-A10B y Qwen3.5-27B Los modelos están diseñados para tareas «agentes»: escenarios en los que un maniquí debe planificar, razonar y ejecutar flujos de trabajo de varios pasos. Estos modelos reducen la brecha entre las alternativas de peso amplio y los modelos de frontera patentados.
El equipo de Alibaba Qwen utilizó un proceso de posentrenamiento de cuatro etapas para estos modelos, que involucra arranques en frío de larga prisión de pensamiento (CoT) y RL basado en el razonamiento. Esto permite que el maniquí 122B-A10B, que utiliza solo 10 mil millones de parámetros activos, mantenga una coherencia método en tareas de grande plazo, rivalizando con el rendimiento de modelos densos mucho más grandes.
Conclusiones esencia
- Eficiencia arquitectónica (MoE): El Qwen3.5-35B-A3B El maniquí, con sólo 3 mil millones de parámetros activos (A3B), supera al maniquí 235B de la vivientes inicial. Esto demuestra que la construcción de mezcla de expertos (MoE), cuando se combina con una calidad de datos superior y estudios por refuerzo (RL), puede ofrecer inteligencia de «nivel de frontera» a una fracción del costo de computación.
- Rendimiento ligero para producción (Flash): Qwen3.5-Flash es la lectura de producción alojada alineada con el maniquí 35B. Está específicamente optimizado para aplicaciones de detención rendimiento y desestimación latencia, lo que lo convierte en el «heroína de batalla» para los desarrolladores que pasan del prototipo a la implementación a escalera empresarial.
- Ventana de contexto masiva: La serie presenta una Largo de contexto de 1M por defecto. Esto permite tareas de contexto prolongado, como el exploración de código de repositorio completo o la recuperación masiva de documentos sin la escazes de estrategias complejas de fragmentación de RAG (vivientes aumentada de recuperación), lo que simplifica significativamente el flujo de trabajo del desarrollador.
- Uso de herramientas nativas y capacidades agentes: A diferencia de los modelos que requieren ingeniería rápida y extensa para interacciones externas, Qwen 3.5 incluye herramientas oficiales integradas. Este soporte nativo para llamadas de funciones e interacción API lo hace en gran medida efectivo para escenarios «agentes» donde el maniquí debe planificar y ejecutar flujos de trabajo de varios pasos.
- El punto ideal ‘medio’: Centrándose en modelos que van desde 27B a 122B (A10B activo)Alibaba apunta a la zona de «Ricitos de Oro» de la industria. Estos modelos son lo suficientemente pequeños como para ejecutarse en una infraestructura de nimbo privada o localizada y, al mismo tiempo, mantienen el razonamiento confuso y la coherencia método que normalmente se reservan para los modelos propietarios masivos de código cerrado.
Mira el Pesos del maniquí y API Flash. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 120.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora incluso puedes unirte a nosotros en Telegram.
