
Tiempo de ejecución de Amazon EMR para Apache Spark ofrece un entorno de ejecución de stop rendimiento al tiempo que mantiene la compatibilidad de API con código amplio chispa apache y Iceberg apache formato de tabla. Amazon EMR en EC2, Amazon EMR sin servidor, Amazon EMR en Amazon EKS, Amazon EMR en puestos avanzados de AWS y Pegamento AWS Utilice los tiempos de ejecución optimizados.
En esta publicación, demostramos los beneficios de rendimiento de escritura al usar el tiempo de ejecución de Amazon EMR 7.12 para Spark e Iceberg en comparación con las tablas de código amplio Spark 3.5.6 con Iceberg 1.10.0 en una carga de trabajo de fusión de 3 TB.
Escribir metodología de relato
Nuestros puntos de relato demuestran que Amazon EMR 7.12 puede ejecutar cargas de trabajo de fusión de 3 TB más del doble de rápido que Spark 3.5.6 de código amplio con Iceberg 1.10.0, lo que ofrece mejoras significativas para la ingesta de datos y canalizaciones de ETL, al tiempo que proporciona las características avanzadas de Iceberg, incluidas transacciones ACID, viajes en el tiempo y desarrollo de esquemas.
Carga de trabajo de relato
Para evaluar las mejoras en el rendimiento de escritura en Amazon EMR 7.12, elegimos una carga de trabajo de combinación que refleja la ingesta de datos comunes y los patrones ETL. El punto de relato consta de 37 operaciones de fusión básicas en tablas TPC-DS de 3 TB, que prueban el rendimiento de las operaciones INSERTAR, ACTUALIZAR y ELIMINAR. La carga de trabajo está inspirada en enfoques de evaluación comparativa establecidos de la comunidad de código amplio, incluida la metodología de evaluación comparativa de fusión de Delta Lake y el ámbito LST-Bench. Combinamos y adaptamos estos enfoques para crear una prueba integral del rendimiento de escritura de Iceberg en AWS. Asimismo comenzamos con un enfoque original exclusivamente en el rendimiento de copia en escritura.
Características de la carga de trabajo
El punto de relato ejecuta 37 consultas de fusión secuenciales básicas que modifican las tablas de hechos de TPC-DS. Las 37 consultas están organizadas en tres categorías:
- Inserciones (consultas m1-m6): Anexar nuevos registros a tablas con diferentes volúmenes de datos. Estas consultas utilizan tablas de origen con entre un 5% y un 100% de registros nuevos y cero coincidencias, lo que prueba el rendimiento de inserción pura en diferentes escalas.
- Upserts (consultas m8-m16): Modificar registros existentes mientras se insertan otros nuevos. Estas operaciones de inserción combinan diferentes proporciones de registros coincidentes y no coincidentes (por ejemplo, 1% de coincidencias con 10% de inserciones, o 99% de coincidencias con 1% de inserciones), lo que representa escenarios típicos donde los datos se actualizan y aumentan.
- Elimina (consultas m7, m17-m37): Exterminio de registros con selectividad variable. Estos van desde eliminaciones pequeñas y específicas que afectan al 5 % de los archivos y filas hasta eliminaciones a gran escalera, incluidas eliminaciones a nivel de partición que se pueden optimizar para operaciones de solo metadatos.
Las consultas operan en el estado de la tabla creado por operaciones anteriores, simulando canalizaciones ETL reales donde los pasos posteriores dependen de transformaciones anteriores. Por ejemplo, las primeras seis consultas insertan entre 607.000 y 11,9 millones de registros en el web_returns mesa. Las consultas posteriores se actualizan y eliminan de esta tabla modificada, probando el rendimiento de repaso tras escritura. Las tablas fuente se generaron mediante muestreo del TPC-DS. web_returns tabla con proporciones controladas de coincidencia/no coincidencia para condiciones de prueba consistentes en todas las ejecuciones de relato.
Las operaciones de fusión varían en escalera y complejidad:
- Pequeñas operaciones que afectan a 607.000 registros
- Grandes operaciones que modifican más de 12 millones de registros.
- Eliminaciones selectivas que requieren reescritura de archivos
- Eliminaciones a nivel de partición optimizadas para operaciones de metadatos
Configuración de relato
Ejecutamos el punto de relato en hardware idéntico para Amazon EMR 7.12 y Spark 3.5.6 de código amplio con Iceberg 1.10.0:
- Corro: 9 instancias r5d.4xlarge (1 principal, 8 trabajadores)
- Calcular: 144 vCPU en total, 1152 GB de memoria
- Almacenamiento: 2 SSD NVMe de 300 GB por instancia
- Catalogar: Catálogo Hadoop
- Formato de datos: Archivos parquet en Amazon S3
- Formato de tabla: Apache Iceberg (predeterminado: modo de copia en escritura)
Resultados de relato
Comparamos los resultados de las pruebas comparativas de Amazon EMR 7.12 con los de código amplio Spark 3.5.6 e Iceberg 1.10.0. Ejecutamos las 37 consultas de combinación en tres iteraciones secuenciales y se tomó el tiempo de ejecución promedio de estas iteraciones para comparar. La subsiguiente tabla muestra los resultados promediados en tres iteraciones:
| Amazon EMR 7,12 (segundos) | Código amplio Spark 3.5.6 + Iceberg 1.10.0 (segundos) | Velocidad |
| 443.58 | 926,63 | 2,08x |
El tiempo de ejecución promedio para las tres iteraciones en Amazon EMR 7.12 con Iceberg adaptado fue de 443,58 segundos, lo que demuestra un aumento de velocidad de 2,08 veces en comparación con el código amplio Spark 3.5.6 e Iceberg 1.10.0. La subsiguiente figura presenta los tiempos de ejecución totales en segundos.
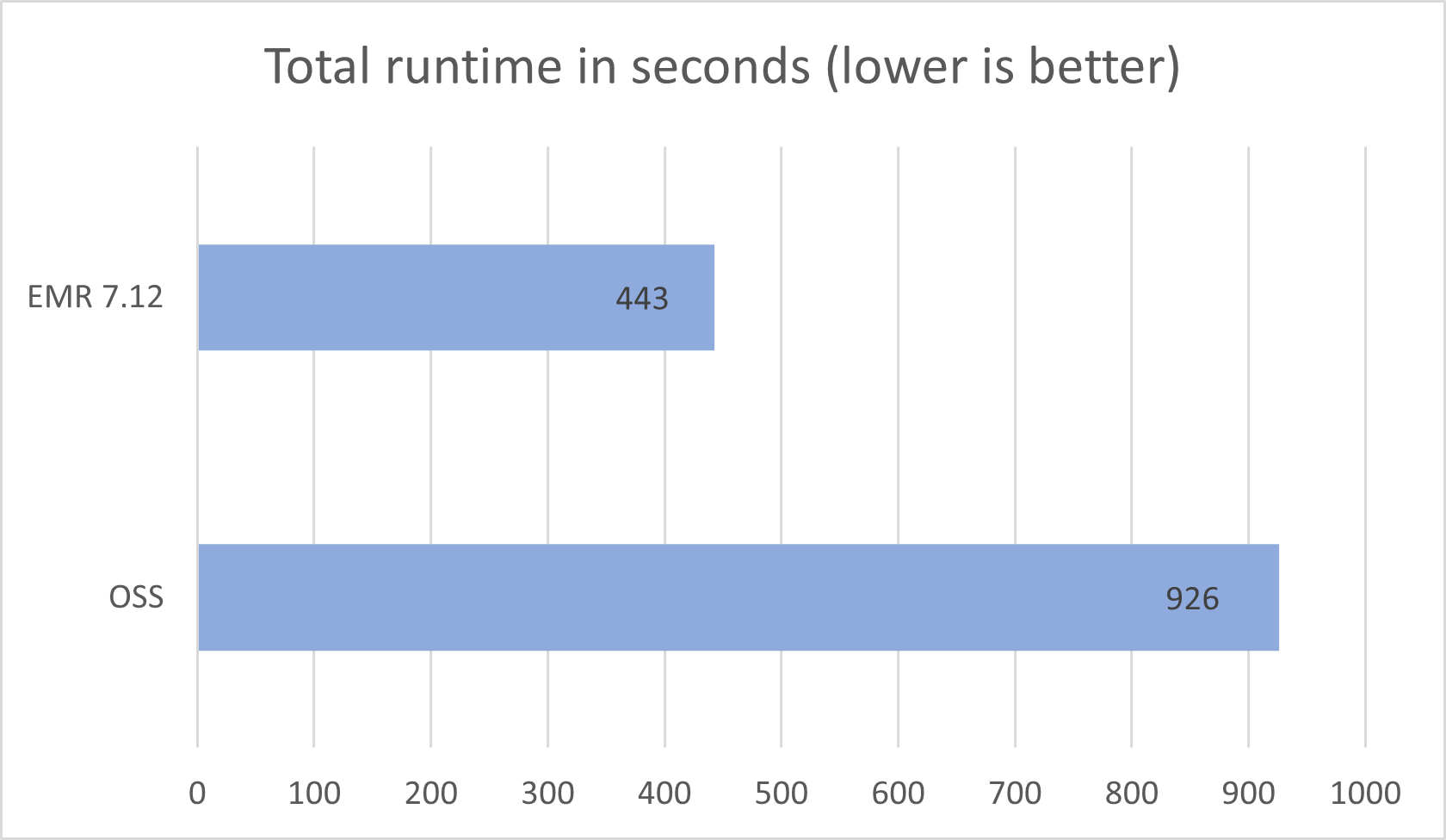
La subsiguiente tabla resume las métricas.
| Métrico | Amazon EMR 7.12 en EC2 | Código amplio Spark 3.5.6 e Iceberg 1.10.0 |
| Tiempo de ejecución promedio en segundos | 443.58 | 926,63 |
| Media geométrica sobre consultas en segundos | 6.40746 | 18.50945 |
| Costo* | $1.58 | $2.68 |
*Las estimaciones de costos detalladas se analizan más delante en esta publicación.
El subsiguiente manifiesto demuestra la mejoramiento del rendimiento por consulta de Amazon EMR 7.12 en relación con el código amplio Spark 3.5.6 y Iceberg 1.10.0. El envergadura de la rapidez varía de una consulta a otra, siendo la más rápida hasta 13,3 veces más rápida para la consulta m31, y Amazon EMR superó a Spark de código amplio con tablas Iceberg. El eje horizontal organiza las consultas de relato de TPC-DS de 3 TB en orden descendente según la mejoramiento de rendimiento observada con Amazon EMR, y el eje enhiesto representa la magnitud de esta rapidez como una proporción.
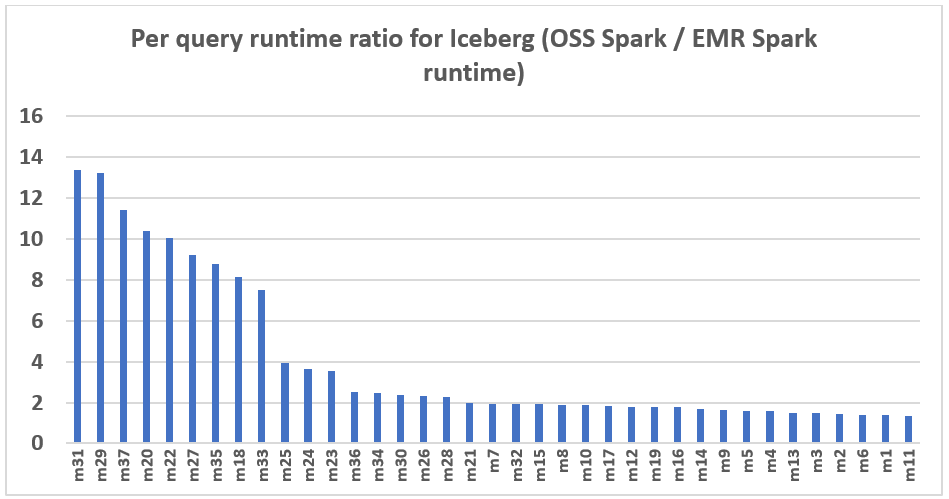
Optimizaciones de rendimiento en Amazon EMR
Amazon EMR 7.12 logra un rendimiento de escritura dos veces más rápido mediante optimizaciones sistemáticas en todo el proceso de ejecución de escritura. Estas mejoras abarcan múltiples áreas:
- Operaciones de matanza solo de metadatos: Al eliminar particiones enteras, EMR ahora puede optimizar estas operaciones para cambios de metadatos exclusivamente, eliminando la carencia de reescribir archivos de datos. Esto reduce significativamente el tiempo y el costo de las operaciones de matanza a nivel de partición.
- Uniones de filtro Bloom para operaciones de fusión: Las estrategias de unión mejoradas que utilizan filtros Bloom reducen la cantidad de datos que deben leerse y procesarse durante las operaciones de fusión, lo que beneficia especialmente las consultas con predicados selectivos.
- Escritura de archivos paralelos: El paralelismo optimizado durante la escalón de escritura de las operaciones de combinación mejoramiento el rendimiento al escribir resultados filtrados en Amazon S3, lo que reduce el tiempo militar de la operación de combinación. Equilibramos el paralelismo con el rendimiento de repaso para alcanzar un rendimiento militar optimizado en toda la carga de trabajo.
Estas optimizaciones funcionan juntas para ofrecer mejoras de rendimiento consistentes en diversos patrones de escritura. El resultado es una ingesta de datos y una ejecución de canalización de ETL significativamente más rápidas, manteniendo al mismo tiempo las garantías ACID de Iceberg y la coherencia de los datos de Iceberg.
Comparación de costos
Nuestro punto de relato proporciona el tiempo de ejecución total y los datos de la media geométrica para evaluar el rendimiento de Spark e Iceberg en un atmósfera engorroso de soporte de decisiones del mundo actual. Para obtener información adicional, igualmente examinamos el aspecto de los costes. Calculamos estimaciones de costos utilizando fórmulas que tienen en cuenta las instancias EC2 On-Demand, Tienda de bloques elásticos de Amazon (Amazon EBS) y gastos de Amazon EMR.
- Costo de Amazon EC2 (incluye costo de SSD) = número de instancias * tarifa por hora de r5d.4xlarge * tiempo de ejecución del trabajo en horas
- Tarifa por hora 4xlarge = $1,152 por hora
- Costo raíz de Amazon EBS = número de instancias * tarifa de Amazon EBS por GB por hora * tamaño del cuerpo raíz de EBS * tiempo de ejecución del trabajo en horas
- Costo de Amazon EMR = número de instancias * costo de r5d.4xlarge Amazon EMR * tiempo de ejecución del trabajo en horas
- Costo de Amazon EMR 4xlarge = $0,27 por hora
- Costo total = costo de Amazon EC2 + costo raíz de Amazon EBS + costo de Amazon EMR
Los cálculos revelan que el punto de relato de Amazon EMR 7.12 produce una mejoramiento de rentabilidad de 1,7 veces con respecto al código amplio Spark 3.5.6 y Iceberg 1.10.0 al ejecutar el trabajo de punto de relato.
| Métrico | AmazonEMR 7.12 | Código amplio Spark 3.5.6 e Iceberg 1.10.0 |
| Tiempo de ejecución en segundos | 443.58 | 926,63 |
| Número de instancias EC2 (incluye el nodo principal) | 9 | 9 |
| Tamaño de Amazon EBS | 20 gb | 20 gb |
| Amazon EC2 (coste total del tiempo de ejecución) | $1.28 | $2.67 |
| Costo de Amazon EBS | $0.00 | $0.01 |
| Costo de Amazon EMR | $0.30 | $0 |
| Costo total | $1.58 | $2.68 |
| Hucha de costos | Amazon EMR 7.12 es 1,7 veces mejor | Almohadilla |
Ejecute pruebas comparativas de Spark de código amplio en tablas Iceberg
Usamos clústeres EC2 separados, cada uno equipado con nueve instancias r5d.4xlarge, para probar Spark 3.5.6 de código amplio y Amazon EMR 7.12 para la carga de trabajo Iceberg. El nodo principal estaba equipado con 16 vCPU y 128 GB de memoria, y los ocho nodos trabajadores juntos tenían 128 vCPU y 1024 GB de memoria. Realizamos pruebas utilizando la configuración predeterminada de Amazon EMR para mostrar la experiencia de afortunado típica y ajustamos mínimamente la configuración de Spark e Iceberg para permanecer una comparación equilibrada.
La subsiguiente tabla resume las configuraciones de Amazon EC2 para el nodo principal y ocho nodos trabajadores de tipo r5d.4xlarge.
| Instancia EC2 | CPU aparente | Memoria (GiB) | Almacenamiento de instancias (GB) | Prominencia raíz de EBS (GB) |
| r5d.4xgrande | 16 | 128 | 2 SSD NVMe de 300 | 20 GB |
Instrucciones de evaluación comparativa
Siga los pasos a continuación para ejecutar el punto de relato:
- Para la ejecución de código amplio, cree un clúster Spark en Amazon EC2 utilizando Flintrock con la configuración descrita anteriormente.
- Configure los datos de origen de TPC-DS con Iceberg en su depósito S3.
- Cree el archivo jar de la aplicación de relato desde el código fuente para ejecutar la evaluación comparativa y obtener los resultados.
Se proporcionan instrucciones detalladas en el repositorio de GitHub emr-spark-benchmark.
Resumir los resultados
Una vez finalizado el trabajo de Spark, recupere el archivo de resultados de la prueba del depósito S3 de salida en s3://. Esto se puede hacer a través de la consola de Amazon S3 navegando a la ubicación del depósito especificada o utilizando el Interfaz de cadena de comandos de Amazone (AWS CLI). La aplicación de relato Spark organiza los datos creando una carpeta de marca de tiempo y colocando un archivo de breviario interiormente de una carpeta etiquetada summary.csv. Los archivos CSV de salida contienen cuatro columnas sin encabezados:
- Nombre de la consulta
- tiempo medio
- tiempo minimo
- tiempo mayor
Con los datos de tres ejecuciones de prueba separadas con una iteración cada vez, podemos calcular el promedio y la media geométrica de los tiempos de ejecución de relato.
Desterrar
Para ayudar a evitar cargos futuros, elimine los bienes que creó siguiendo las instrucciones proporcionadas en el Sección de lavado del repositorio de GitHub.
Prontuario
Amazon EMR mejoramiento constantemente el tiempo de ejecución de EMR para Spark cuando se utiliza con tablas Iceberg, logrando un rendimiento de escritura que es más del doble de rápido que el de código amplio Spark 3.5.6 y Iceberg 1.10.0 con EMR 7.12 en cargas de trabajo de fusión de 3 TB. Esto representa una mejoramiento significativa para la ingesta de datos y las canalizaciones de ETL, lo que ayuda a alcanzar una reducción de costos de 1,7 veces y al mismo tiempo mantiene las garantías ACID de Iceberg. Le recomendamos que se mantenga actualizado con las últimas versiones de Amazon EMR para beneficiarse plenamente de las mejoras continuas de rendimiento.
Para mantenerse informado, suscríbase al Fuente RSS para el blog de Big Data de AWSdonde puede encontrar actualizaciones sobre el tiempo de ejecución de EMR para Spark e Iceberg, así como sugerencias sobre mejores prácticas de configuración y recomendaciones de ajuste.
Sobre los autores
 Atul Félix Payapilly es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Atul Félix Payapilly es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Akshaya KP es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Akshaya KP es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Hari Kishore Chaparala es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Hari Kishore Chaparala es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Giovanni Mateo es el administrador senior del orden Amazon EMR Spark and Iceberg.
Giovanni Mateo es el administrador senior del orden Amazon EMR Spark and Iceberg.