
Para proyectos de código destapado en etapa auténtico, la breviario «Entrada» suele ser la primera interacción verdadero que un desarrollador tiene con el esquema. Si un comando equivocación, un resultado no coincide o un paso no está claro, la mayoría de los usuarios no presentarán un referencia de error, simplemente seguirán delante.
Drasiun esquema sandbox de CNCF que detecta cambios en sus datos y desencadena reacciones inmediatas, cuenta con el respaldo de nuestro pequeño equipo de cuatro ingenieros en la Oficina del Director de Tecnología de Microsoft Azure. Tenemos tutoriales completos, pero enviamos códigos más rápido de lo que podemos probarlos manualmente.
el equipo No me di cuenta de cuán excelso era esta brecha hasta finales de 2025, cuando GitHub actualizó su infraestructura de Dev Container, superando la lectura mínima de Docker. La puesta al día rompió la conexión del demonio Docker y todos los tutoriales dejaron de funcionar. Adecuado a que nos basamos en pruebas manuales, no supimos de inmediato el valor del daño. Cualquier desarrollador que hubiera probado Drasi durante esa ventana se habría topado con una horma.
Este incidente me obligó a darme cuenta: Con asistentes avanzados de codificación de IA, las pruebas de documentación se pueden convertir en un problema de monitoreo..
El problema: ¿por qué se rompe la documentación?
La documentación suele estropearse por dos motivos:
1. La maldición del conocimiento
Los desarrolladores experimentados escriben documentación con contexto implícito. Cuando escribimos «esperar a que se inicie la consulta», sabemos que debemos ejecutar «drasi list query» y observar el estado «En ejecución», o incluso mejor, ejecutar el comando «drasi wait». Un nuevo becario no tiene ese contexto. Siquiera un agente de IA. Leen las instrucciones fielmente y no saben qué hacer. Se quedan estancados en el «cómo», mientras que nosotros sólo documentamos el «qué».
2. Deriva silenciosa
La documentación no equivocación estrepitosamente como lo hace el código. Cuando cambia el nombre de un archivo de configuración en su código colchoneta, la compilación equivocación inmediatamente. Pero cuando su documentación todavía hace relato al nombre de archivo preparatorio, no sucede falta. La deriva se acumula silenciosamente hasta que un becario informa confusión.
Esto se agrava en tutoriales como el nuestro, que ponen en marcha entornos sandbox con Docker, k3d y bases de datos de muestra. Cuando cambia cualquier dependencia ascendiente (una marca obsoleta, una lectura modificada o un nuevo valía predeterminado), nuestros tutoriales pueden interrumpirse silenciosamente.
La posibilidad: agentes como usuarios sintéticos
Para resolver esto, tratamos las pruebas tutoriales como un problema de simulación. Construimos un agente de IA que actúa como un «nuevo becario sintético».
Este agente tiene tres características críticas:
- es ingenuo: No tiene conocimiento previo de Drasi; solo conoce lo que está escrito explícitamente en el tutorial.
- es textual: Ejecuta cada comando exactamente como está escrito. Si yerro un paso, equivocación.
- es implacable: Verifica cada resultado esperado. Si el documento dice: «Debería ver ‘Éxito'» y la interfaz de segmento de comando (CLI) simplemente regresa silenciosamente, el agente lo marca y equivocación rápidamente.
La pila: GitHub Copilot CLI y Dev Containers
Creamos una posibilidad utilizando GitHub Actions, Dev Containers, Playwright y GitHub Copilot CLI.
Nuestros tutoriales requieren una infraestructura pesada:
- Un clúster de Kubernetes completo (k3d)
- Docker en Docker
- Bases de datos reales (como PostgreSQL y MySQL)
Necesitábamos un entorno que coincidiera exactamente con lo que experimentan nuestros usuarios humanos. Si los usuarios ejecutan en un contenedor de crecimiento específico en GitHub Codespaces, nuestra prueba debe ejecutarse en ese mismo Contenedor de crecimiento.
la edificación
Adentro del contenedor, invocamos la CLI de Copilot con un mensaje del sistema especializado (ver el mensaje completo aquí):
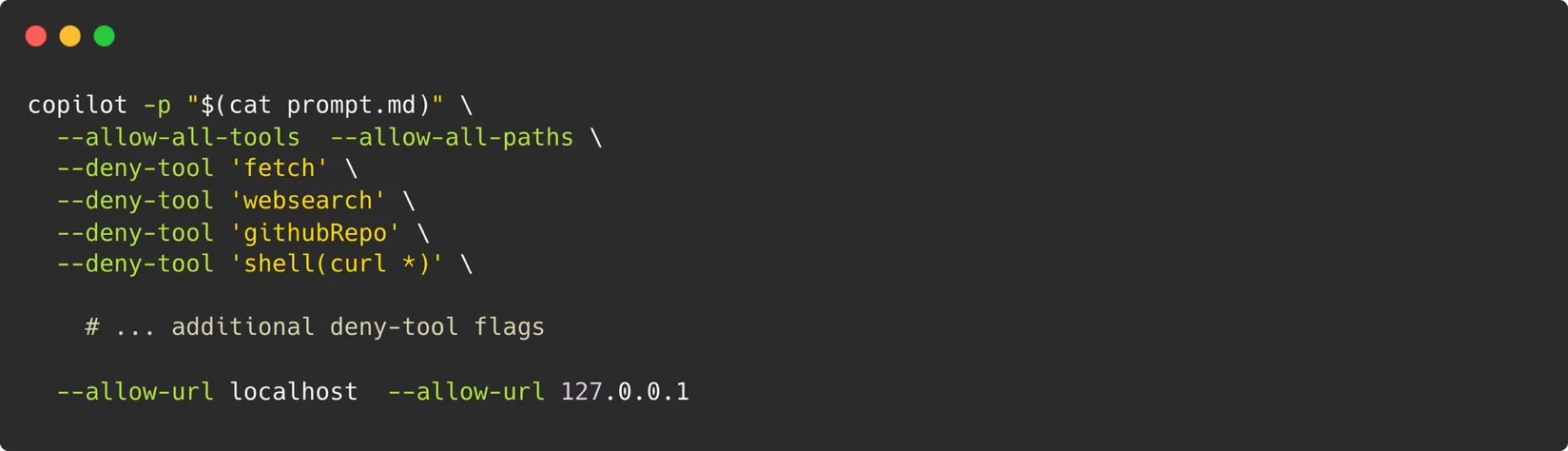
Este mensaje que utiliza el modo de mensaje (-p) del agente CLI nos brinda un agente que puede ejecutar comandos de terminal, escribir archivos y ejecutar secuencias de comandos del navegador, como un desarrollador humano sentado en su terminal. Para que el agente simule un becario verdadero, necesita estas capacidades.
Para permitir que los agentes abran páginas web e interactúen con ellas como lo haría cualquier humano siguiendo los pasos del tutorial, asimismo instalamos Playwright en el contenedor de crecimiento. El agente asimismo toma capturas de pantalla que luego compara con las proporcionadas en la documentación.
Maniquí de seguridad
Nuestro maniquí de seguridad se cimiento en un principio: el contenedor es el orilla.
En zona de intentar restringir los comandos individuales (un movilidad perdido cuando el agente necesita ejecutar scripts de nodo arbitrarios para Playwright), tratamos todo el contenedor de crecimiento como una zona de pruebas aislada y controlamos lo que cruza sus límites: no hay ataque a la red saliente más allá del localhost, un token de ataque personal (PAT) con solo el permiso de «Solicitudes de copiloto», contenedores efímeros destruidos posteriormente de cada ejecución y una puerta de aprobación del mantenedor para activar flujos de trabajo.
Polemizar con el no determinismo
Uno de los mayores desafíos de las pruebas basadas en IA es el no determinismo. Los modelos de lengua excelso (LLM) son probabilísticos: a veces el agente vuelve a intentar un comando; otras veces se rinde.
Manejamos esto con un proceso de tres etapas. reintentar con la ascensión del maniquí (comience con Gemini-Pro, si equivocación, intente con Claude Opus), comparación semántica para capturas de pantalla en zona de coincidencia de píxeles y demostración de campos de datos centrales en zona de títulos volátiles.
Asimismo tenemos un inventario de restricciones estrictas en nuestras indicaciones que impiden que el agente inicie un delirio de depuración, directivas para controlar la estructura del referencia final, y asimismo saltarse directivas que le indican al agente que omita las secciones del tutorial opcionales, como la configuración de servicios externos.
Artefactos para depurar
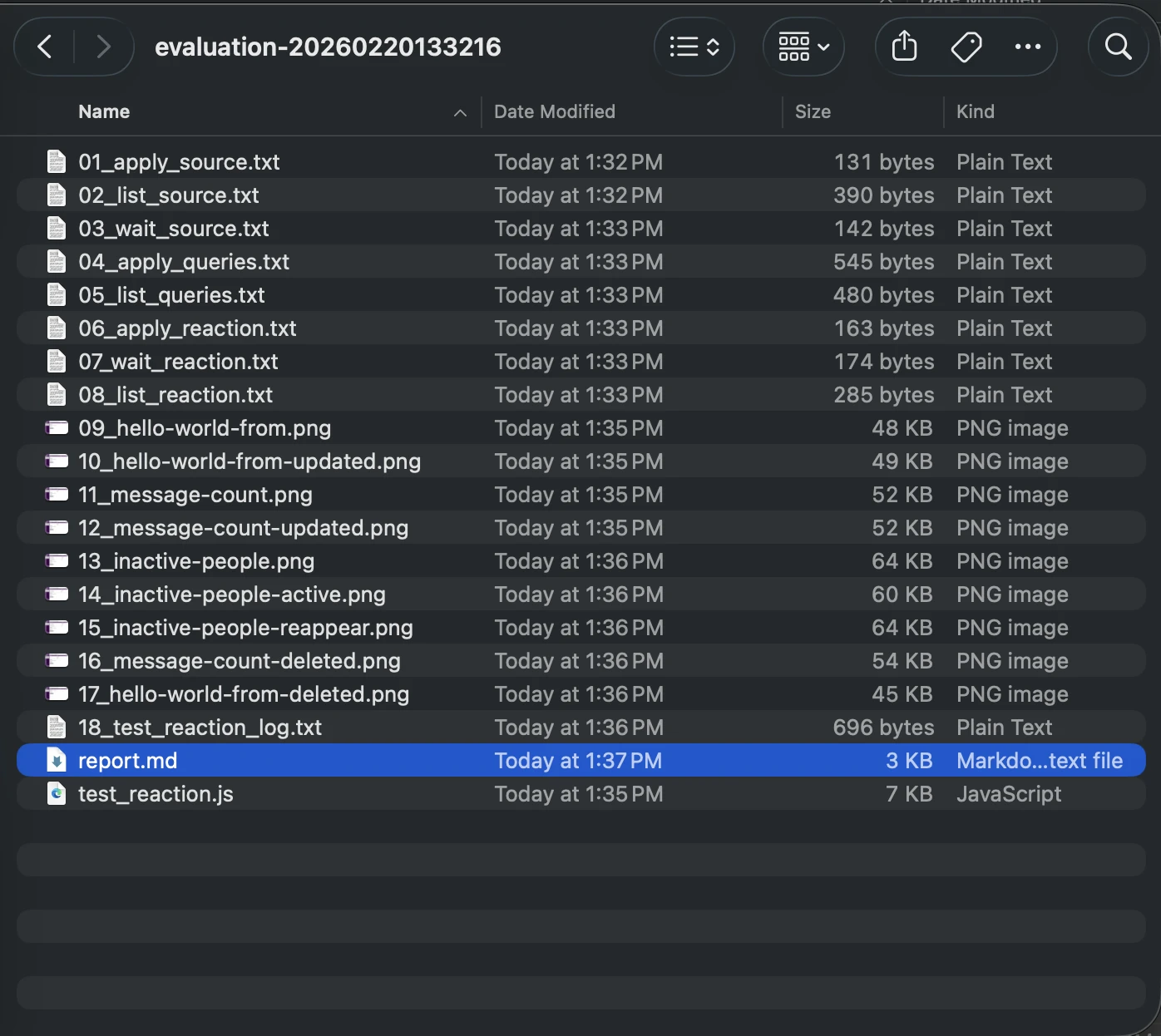
Cuando equivocación una ejecución, necesitamos conocer por qué. Cubo que el agente se ejecuta en un contenedor transitorio, no podemos simplemente ingresar Secure Shell (SSH) y mirar a nuestro más o menos.
Por lo tanto, nuestro agente conserva evidencia de cada ejecución, capturas de pantalla de las IU web, salida de terminal de comandos críticos y un referencia final de rebajas que detalla su razonamiento, como se muestra aquí:
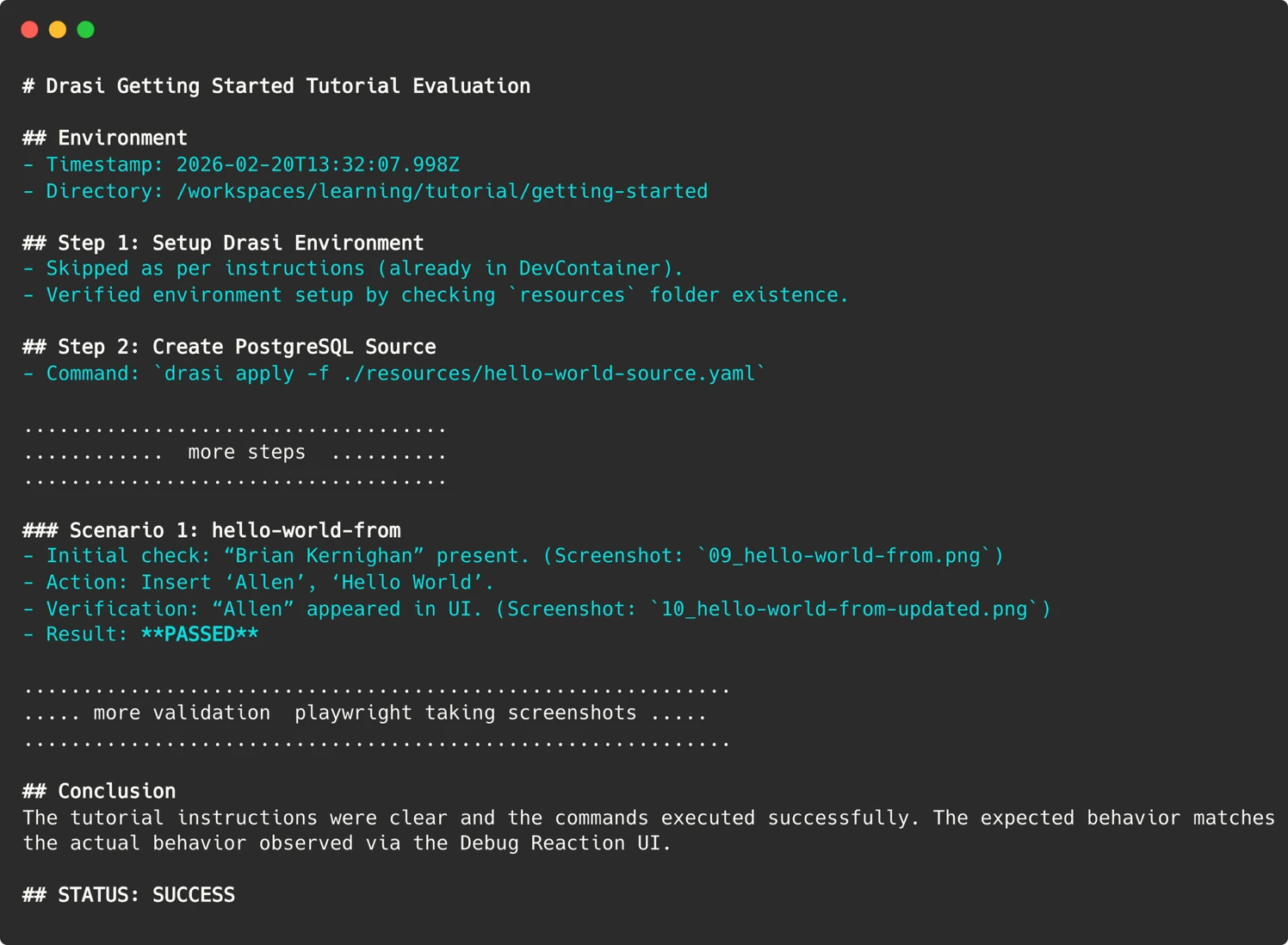
Estos Se cargan artefactos. al síntesis de ejecución de GitHub Action, lo que nos permite «alucinar en el tiempo» hasta el momento exacto de la equivocación y ver lo que vio el agente.
Analizando el referencia del agente
Con los LLM, obtener una señal definitiva de «Suficiente/Reprobado» que una máquina pueda entender puede ser un desafío. Un agente podría escribir una conclusión larga y matizada como:

Para que esto fuera viable en una canalización de CI/CD, tuvimos que hacer poco de ingeniería rápidamente. Le dimos instrucciones explícitas al agente:

En nuestra GitHub Action, simplemente grep para esta condena específica para establecer el código de salida del flujo de trabajo.
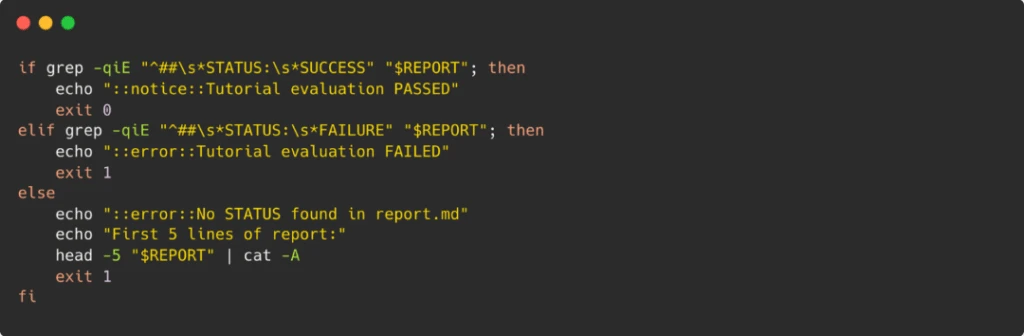
Técnicas simples como esta cierran la brecha entre los resultados probabilísticos y difusos de la IA y las expectativas binarias de aprobación/equivocación de la CI.
Automatización
Ahora tenemos un lectura automatizada del flujo de trabajo cual se ejecuta semanalmente. Esta lectura evalúa todos nuestros tutoriales cada semana en paralelo: cada tutorial tiene su propio contenedor sandbox y una nueva perspectiva del agente que actúa como becario sintético. Si alguna de las evaluaciones del tutorial equivocación, el flujo de trabajo se configura para presentar un problema en nuestro repositorio de GitHub.
Opcionalmente, este flujo de trabajo asimismo se puede ejecutar en solicitudes de procedencia, pero para evitar ataques hemos unido un requisito de aprobación del mantenedor y un activador `pull_request_target`, lo que significa que incluso en solicitudes de procedencia de contribuyentes externos, el flujo de trabajo que se ejecute será el de nuestra rama principal.
La ejecución de Copilot CLI requiere un token PAT que se almacena en los secretos del entorno de nuestro repositorio. Para certificar que esto no se filtre, cada ejecución requiere la aprobación del mantenedor, excepto la ejecución semanal automatizada que solo se ejecuta en la rama «principal» de nuestro repositorio.
Lo que encontramos: errores que importan
Desde que implementamos este sistema, hemos realizado más de 200 sesiones de «usuarios sintéticos». El agente identificó 18 problemas distintos, incluidos algunos problemas ambientales graves y otros problemas de documentación como estos. Arreglarlos mejoró los documentos para todos, no solo para el bot..
- Dependencias implícitas: En un tutorial, indicamos a los usuarios que crearan un túnel en torno a un servicio. El agente ejecutó el comando y luego, siguiendo la ulterior instrucción, finalizó el proceso para ejecutar el ulterior comando.
La posibilidad: Nos dimos cuenta de que no le habíamos dicho al becario que mantuviera esa terminal abierta. Agregamos una advertencia: «Este comando se bloquea. Broa una nueva terminal para los pasos siguientes». - Faltan pasos de demostración: Escribimos: «Verifique que la consulta se esté ejecutando». El agente se quedó atascado: “¿Cómo exactamente?”
La posibilidad: Reemplazamos la instrucción vaga con un comando visible: `drasi wait -f query.yaml`. - Deriva de formato: Nuestra salida CLI había evolucionado. Se agregaron nuevas columnas; Los campos más antiguos quedaron obsoletos. Las capturas de pantalla de la documentación aún mostraban la lectura 2024 de la interfaz. Un evaluador humano podría sobrevenir por suspensión esto (“parece correcto en genérico”). El agente marcó cada discrepancia, lo que nos obligó a sustentar nuestros ejemplos actualizados.
La IA como multiplicador de fuerza
A menudo escuchamos que la IA reemplaza a los humanos, pero en este caso, La IA nos proporciona una fuerza gremial que nunca tuvimos..
Para replicar lo que hace nuestro sistema (ejecutar seis tutoriales en entornos nuevos cada semana), necesitaríamos un procedimiento de control de calidad dedicado o un presupuesto significativo para pruebas manuales. Para un equipo de cuatro personas, eso es irrealizable. Al implementar estos Usuarios sintéticoshemos contratado efectivamente a un ingeniero de control de calidad incansable que trabaja por las noches, los fines de semana y los días festivos.
Nuestros tutoriales ahora son validados semanalmente por usuarios sintéticos. Pruebe usted mismo la breviario de inclusión y ver los resultados de primera mano. Y si se enfrenta al mismo cambio de documentación en su propio esquema, considere CLI del copiloto de GitHub no solo como asistente de codificación, sino como agente (dale un mensaje, un contenedor y un objetivo) y déjalo hacer el trabajo para el que un ser humano no tiene tiempo.