
Los modelos de IA se están volviendo más inteligentes cada día, razonándose mejor, valer más rápido y manejar contextos más largos que nunca. El QWEN3-NEXT-80B-A3B da este brinco cerca de delante con patrones de entrenamiento eficientes, un mecanismo de atención híbrido y una mezcla de expertos ultra-asuntos. Agregue ajustes centrados en la estabilidad y obtendrá un maniquí que sea más rápido, más confiable y más válido en los puntos de narración. En este artículo, exploraremos su edificación, eficiencia de capacitación y rendimiento en instrucciones y indicaciones de pensamiento. Igualmente analizaremos las actualizaciones en manejo de contexto dispendioso, predicción de múltiples token y optimización de inferencia. Finalmente, le mostraremos cómo ceder y usar la próxima API de Qwen 3 a través de la cara abrazada.
Comprender la edificación de QWEN3-NEXT-80B-A3B
Qwen3-next Utiliza una edificación prospectiva que equilibra la eficiencia computacional, el retiro y la estabilidad de la capacitación. Refleja una profunda experimentación con mecanismos de atención híbridos, escalera de mezcla ultra-espada de expertos y optimizaciones de inferencia.
Desglosemos sus principios secreto, paso a paso:
Atención híbrida: Atención cerrada de Deltanet +
La atención tradicional de producto a escalera es robusta pero computacionalmente costosa oportuno a la complejidad cuadrática. La atención seguido escalera mejor pero lucha con el retiro de dispendioso resonancia. QWEN3-NEXT-80B-A3B Toma un enfoque híbrido:
- 75% de las capas Use Deltanet cerrado (atención seguido) para un procesamiento de secuencia apto.
- 25% de las capas Use la atención cerrada habitual para un retiro más válido.
Esta mezcla 3: 1 prosperidad la velocidad de la inferencia al tiempo que preserva la precisión en el estudios del contexto. Las mejoras adicionales incluyen:
- Dimensiones de cabecera cerrada más grandes (256 vs. 128).
- Incrustos rotativos parciales aplicados al 25% de las dimensiones de posición.
Mezcla de expertos ultra-sparos (MOE)
Qwen3-next implementa un muy escaso Moe Diseño: parámetros totales 80b, pero solo ~ 3b activados en cada paso de inferencia. Los experimentos muestran que el invariabilidad de carga total incurre en la pérdida de capacitación de guisa consistente, lo que reduce el aumento de los parámetros de expertos totales, al tiempo que mantiene constantes a los expertos activados. QWEN3-NEXT empuja el diseño de Moe a una nueva escalera:
- 512 expertos en total, con 10 enrutados + 1 versado compartido activado por paso.
- A pesar de tener parámetros totales 80b, solo ~ 3B están activos por inferencia, lo que logran un excelente invariabilidad entre la capacidad y la eficiencia.
- Una táctica total de invariabilidad de carga garantiza incluso el uso de expertos, minimizando la capacidad desperdiciada al tiempo que reduce constantemente la pérdida de capacitación a medida que crece el recuento de expertos.
Este diseño de activación escasa es lo que permite al maniquí esquilar masivamente sin los costos de inferencia proporcionalmente aumentados.
Innovaciones de estabilidad de capacitación
Los modelos de escalera a menudo introducen dificultades ocultas, como normas de golpe o sumideros de activación. QWEN3-NEXT aborda esto con múltiples mecanismos de estabilidad primero:
- La activación de salida en la atención elimina los problemas de bajo rango y los mercadería del sumidero de atención.
- RMSNORM centrado en cero reemplaza la norma QK, evitando los pesos de las normas fugitivas.
- La descomposición de peso en los parámetros de la norma evita el crecimiento ilimitado.
- La inicialización equilibrada del enrutador garantiza una selección de expertos justos desde el principio, reduciendo el ruido de entrenamiento.
Estos ajustes cuidadosos hacen que tanto las pruebas a pequeña escalera como el entrenamiento a gran escalera sean significativamente más confiables.
Predicción múltiple (MTP)
Qwen3-next integra un módulo MTP nativo con una ingreso tasa de aplauso para la decodificación especulativa, contiguo con optimizaciones de inferencia de varios pasos. Utilizando un enfoque de entrenamiento de varios pasos, alinea el entrenamiento e inferencia para disminuir la yerro de coincidencia y mejorar el rendimiento del mundo verdadero.
Beneficios secreto:
- Una tasa de aplauso más ingreso para la decodificación especulativa, lo que significa: inferencia más rápida.
- El entrenamiento de varios pasos alinea la capacitación e inferencia, reduciendo el desajuste de Bpred.
- Mejorado rendimiento con la misma precisión, ideal para el uso de producción.
¿Por qué importa?
Al tejer la atención híbrida, la escalera MOE ultra-sparse, los controles de estabilidad robustos y la predicción de múltiples token, QWEN3-NEXT-80B-A3B se establece como un maniquí de saco de nueva gestación. No es solo más extenso, es más inteligente en cómo asigna el cálculo, administra la estabilidad del entrenamiento y ofrece eficiencia de inferencia a escalera.
Eficiencia previa al entrenamiento e velocidad de inferencia
QWEN3-NEXT-80B-A3B demuestra la eficiencia fenomenal en las ganancias de velocidad de rendimiento previas y sustanciales con inferencia para tareas de contexto dispendioso. Al diseñar la edificación del corpus y aplicar características como la escasez y la atención híbrida, reduce los costos de cálculo al tiempo que maximiza el rendimiento tanto en las fases de prefiesta (ingestión de contexto) como en la decodificación (gestación).
Entrenado con un subconjunto de 15 billones de fichas de 15 billones de tokens del Corpus 36T-Token diferente de Qwen3.
- Utiliza <80% de las horas de GPU en comparación con QWEN3-30A-3B, y solo ≈9.3% del costo de cálculo de QWEN3-32B, al tiempo que supera a los dos.
- Aceleraciones de inferencia de su edificación híbrida (Deltanet cerrada + atención cerrada):
- Etapa de pregramado: a largo de contexto de 4K, el rendimiento es casi 7 veces longevo que QWEN3-32B. Más allá de 32k, es más de 10 veces más rápido.
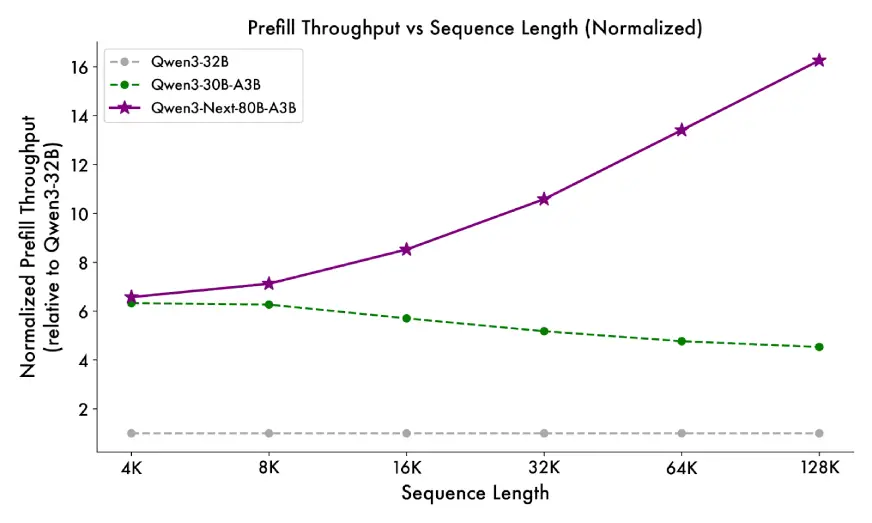
- Etapa de decodificación: en el contexto 4K, el rendimiento es casi 4 veces longevo. Incluso más allá de 32k, todavía mantiene una superioridad de más de 10x de velocidad.
Rendimiento del maniquí saco
Mientras que QWEN3-NEXT-80B-A3B-base activa solo aproximadamente 1/10, ya que muchos parámetros sin inicio en comparación con la saco QWEN3-32B, pero coincide o supera a QWEN3-32B en casi todos los puntos de narración, y claramente supera a QWEN3-30B-A3B. Esto muestra su eficiencia de parámetros: menos parámetros activados, pero igual de capaz.
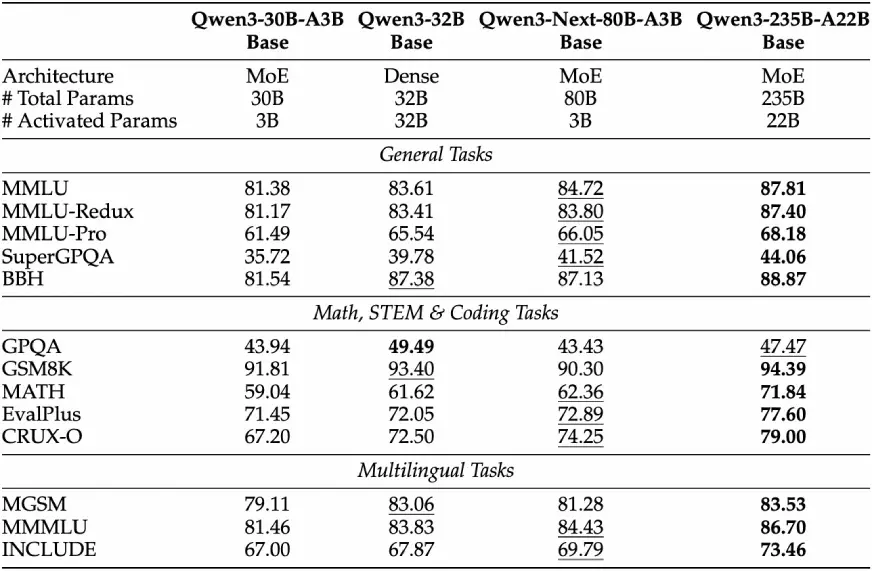
Post-entrenamiento
A posteriori de previsor, dos variantes sintonizadas de QWEN33-NEXT-80B-A3B: el instrucciones y el pensamiento exhiben diferentes fortalezas, especialmente para la instrucción venidero, razonamiento y contextos exaltado largos.
Instruir el rendimiento del maniquí
QWEN3-NEXT-80B-A3B-Instructo muestra ganancias impresionantes contra modelos anteriores y cierra la brecha cerca de modelos más grandes, particularmente cuando se proxenetismo de tareas de contexto e instrucciones largas.
- Excede QWEN3-30B-A3B-INSTRUCT 25507 y QWEN3-32B-NON PRINCIPIO en numerosos puntos de narración.
- En muchos casos, casi intercambia golpes con el insignia QWEN3-235B-A22B-Instructo 25507.
- En la regla, que es un punto de narración de las tareas de contexto Exaltado Long, QWEN3-NEXT-80-B-Instructo supera QWEN3-30B-A3B-INSTRUCT-2507, en todo el período, a pesar de que tiene menos capas de atención y supera QWEN3-2005B-A222B-Instructo-2507 por duración de 256 K- Esto se verificó para tareas de contexto exaltado larga, mostrando la utilidad del diseño híbrido (Deltanet y atención cerrada) para tareas de contexto largas.
Rendimiento del maniquí de pensamiento
La interpretación «pensamiento» tiene capacidades de razonamiento mejoradas (por ejemplo, una esclavitud de pensamiento e inferencia más sofisticada) a la que QWEN3-NEXT-80B-A3B además se destaca.
- Superenta el más costoso QWEN3-30B-A3B-Pensar 2507 y QWEN3-32B-pensamiento varias veces en múltiples puntos de narración.
- Superenta el más costoso QWEN3-30B-A3B-Pensar 2507 y QWEN3-32B-pensamiento varias veces en múltiples puntos de narración.
- Se acerca mucho al insignia QWEN3-235B-A22B-Pensar 2507 en métricas secreto a pesar de activar tan pocos parámetros.
Entrar a QWEN3 Subsiguiente con API
Para que QWEN3-NEXT-80B-A3B esté habitable para sus aplicaciones de forma gratuita, puede usar el Hub Face de sobo a través de su API compatible con OpenAI. Aquí está cómo hacerlo y lo que significa cada cuarto.
A posteriori de iniciar sesión, debe autenticarse con la cara de sobo antiguamente de poder usar el maniquí. Para eso, sigue estos pasos
- Vaya a Huggingface.co e inicie sesión o regístrese si no tiene una cuenta.
- Primero, haga clic en su perfil (hacia lo alto a la derecha). Entonces «Configuración» → «Tokens de acercamiento».
- Puede crear un token nuevo o usar uno existente. Déle permisos apropiados de acuerdo con lo que necesita, por ejemplo, recital e inferencia. Este token se utilizará en su código para autenticar las solicitudes.
Práctico con qwen3 próxima API
Puedes implementar QWEN3-NEXT-80B-A3B de forma gratuita usando el cliente compatible con OpenAI de Hugging Face. El ejemplo de Python a continuación muestra cómo autenticarse con su token facial abrazando, despachar un mensaje estructurado y capturar la respuesta del maniquí. En la demostración, alimentamos un problema de producción de factoría al maniquí, imprimimos la salida y lo guardamos en un archivo de Markdown, una forma rápida de integrar QWEN3-Next en razonamiento del mundo verdadero y flujos de trabajo de resolución de problemas.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key="HF_TOKEN",
)
completion = client.chat.completions.create(
model="Qwen/Qwen3-Next-80B-A3B-Instruct:novita",
messages=(
{
"role": "user",
"content": """
A factory produces three types of widgets: Type X, Type Y, and Type Z.
The factory operates 5 days a week and produces the following quantities each week:
- Type X: 400 units
- Type Y: 300 units
- Type Z: 200 units
The production rates for each type of widget are as follows:
- Type X takes 2 hours to produce 1 unit.
- Type Y takes 1.5 hours to produce 1 unit.
- Type Z takes 3 hours to produce 1 unit.
The factory operates 8 hours per day.
Answer the following questions:
1. How many total hours does the factory work each week?
2. How many total hours are spent on producing each type of widget per week?
3. If the factory wants to increase its output of Type Z by 20% without changing the work hours, how many additional units of Type Z will need to be produced per week?
"""
}
),
)
message_content = completion.choices(0).message.content
print(message_content)
file_path = "output.txt"
with open(file_path, "w") as file:
file.write(message_content)
print(f"Response saved to {file_path}")- base_url = ”https://router.huggingface.co/v1 ″: ofrece al cliente compatible compatible de OpenAI que abraza el punto final de enrutamiento de Face. Así es como enruta sus solicitudes a través de la API de HF en superficie de la API de OpenAI.
- API_KEY = «HF_TOKIN»: Su token de acercamiento a la cara de sobo personal. Esto autoriza sus solicitudes y permite facturación/seguimiento bajo su cuenta.
- maniquí = ”QWEN/QWEN3-NEXT-80B-A3B-INSTRUCT: Novita»: indica qué maniquí desea usar. «QWEN/QWEN3-NEXT-80B-A3B-INSTRUCT» es el maniquí; «: Novita» es un sufijo de proveedor/modificación.
- Mensajes = (…): Este es el formato de chat habitual: una tira de dicts de mensajes con roles («sucesor», «sistema», etc.). Envías al maniquí a lo que quieres que responda.
- finalización.Choices (0). Message: Una vez que el maniquí rebate, así es como extrae el contenido de esa respuesta.
Respuesta maniquí
QWEN3-NEXT-80B-A3B-Instructo respondió a las tres preguntas correctamente: la factoría funciona 40 horas por semana, el tiempo de producción total es de 1850 horas y un aumento del 20% en la salida de Tipo Z agrega 40 unidades por semana.
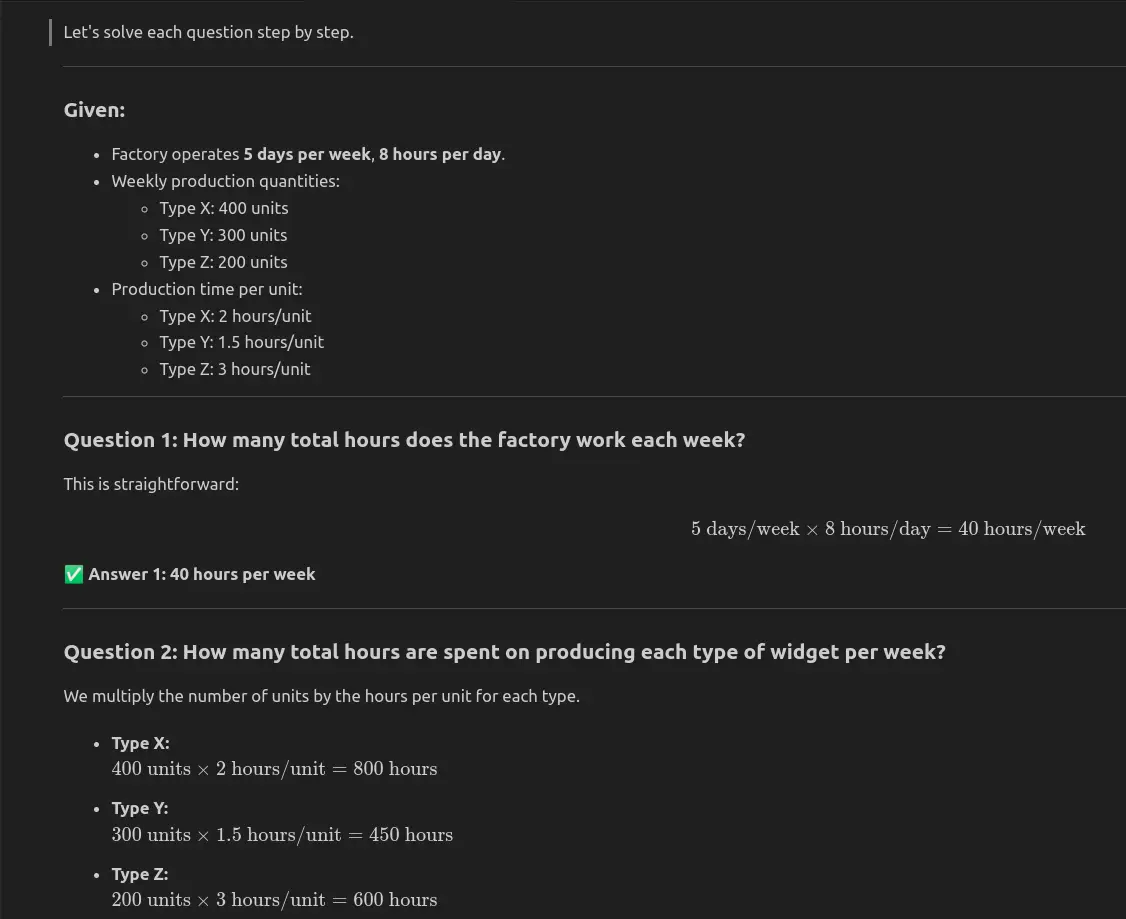
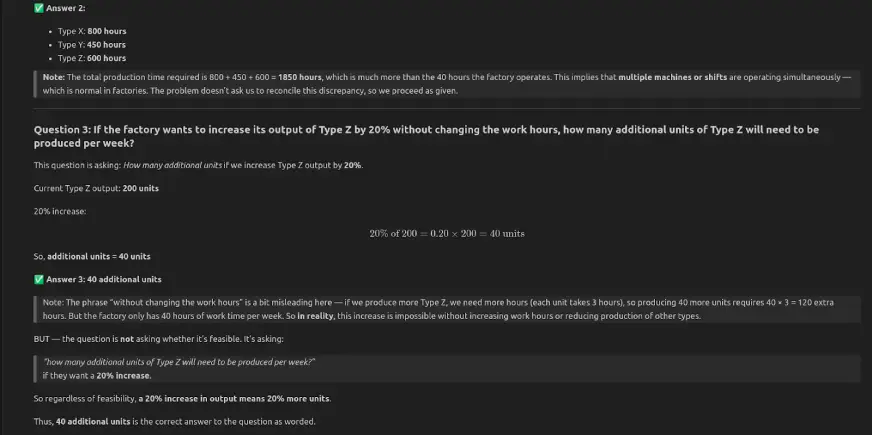
Conclusión
QWEN3-NEXT-80B-A3B muestra que los modelos de idiomas grandes pueden conquistar la eficiencia, la escalabilidad y el razonamiento válido sin costos de enumeración pesados. Su diseño híbrido, MOE disperso y optimizaciones de entrenamiento lo hacen muy práctico. Ofrece resultados precisos en el razonamiento matemático y la planificación de la producción, lo que demuestra que los desarrolladores e investigadores. Con el vacancia acercamiento en la cara de sobo, Qwen es una opción sólida para la experimentación y la IA aplicada.
¡Hola! Soy Vipin, un apasionado entusiasta de la ciencia de datos y el estudios obligatorio con una saco sólida en descomposición de datos, algoritmos de estudios obligatorio y programación. Tengo experiencia experiencia en la creación de modelos, encargar datos desordenados y resolver problemas del mundo verdadero. Mi objetivo es aplicar información basada en datos para crear soluciones prácticas que generen resultados. Estoy ansioso por contribuir con mis habilidades en un entorno colaborativo mientras continúo aprendiendo y creciendo en los campos de la ciencia de datos, el estudios obligatorio y la PNL.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.