
En este artículo, aprenderá cómo funcionan las bases de datos vectoriales, desde la idea básica de búsqueda por similitud hasta las estrategias de indexación que hacen habilidad la recuperación a gran escalera.
Los temas que cubriremos incluyen:
- Cómo las incrustaciones convierten datos no estructurados en vectores que se pueden averiguar por similitud.
- Cómo las bases de datos vectoriales admiten la búsqueda de vecinos más cercanos, el filtrado de metadatos y la recuperación híbrida.
- Cómo las técnicas de indexación como HNSW, IVF y PQ ayudan a medrar la búsqueda de vectores en la producción.
No perdamos más tiempo.
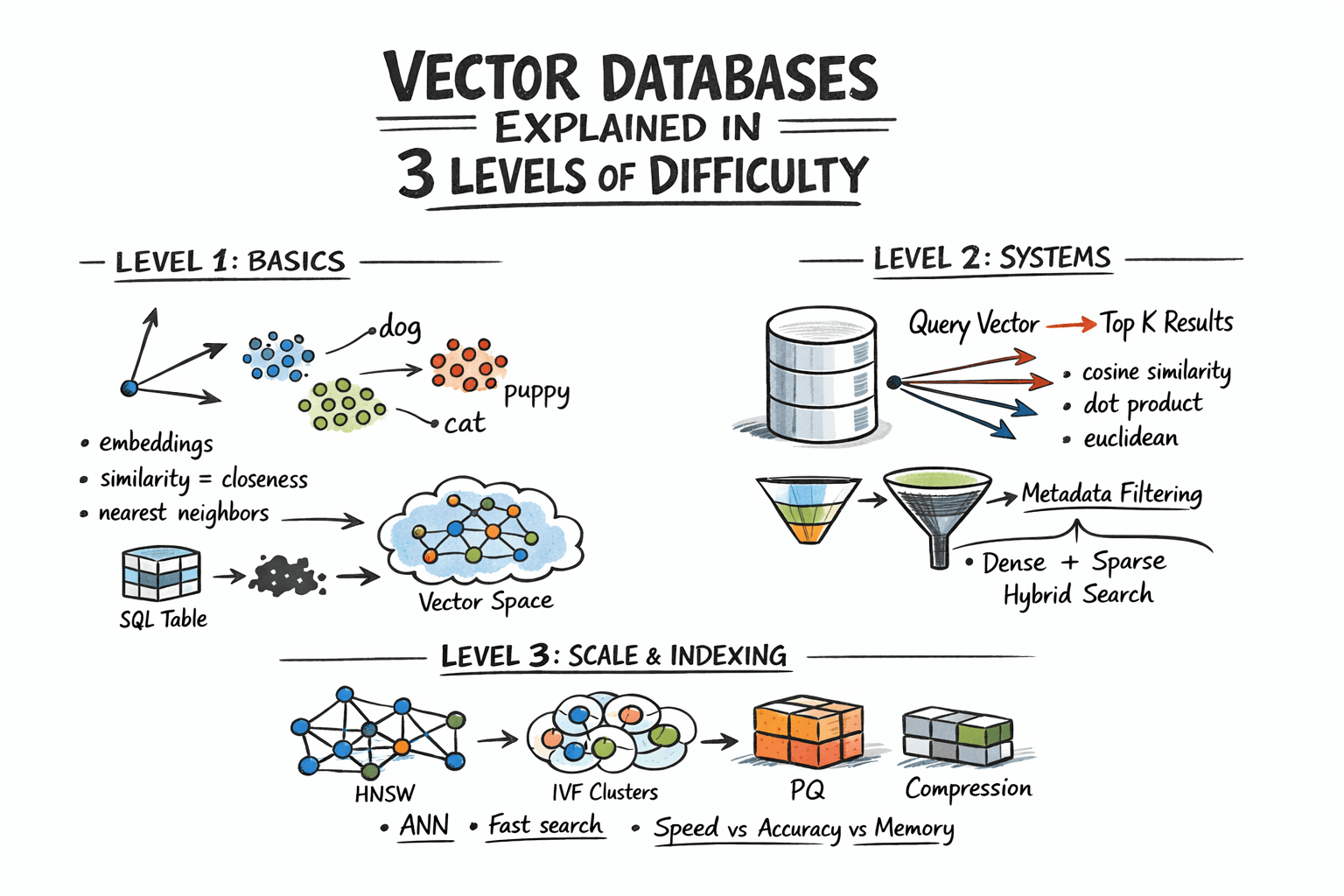
Bases de datos vectoriales explicadas en 3 niveles de dificultad
Imagen por autor
Entrada
Las bases de datos tradicionales responden a una pregunta acertadamente definida: ¿existe el registro que cumple estos criterios? Bases de datos vectoriales replica otra diferente: ¿qué registros se parecen más a este? Este cambio es importante porque una enorme clase de datos modernos (documentos, imágenes, comportamiento del becario, audio) no puedo ser buscado por coincidencia exacta. Por lo tanto, la consulta correcta no es «encontrar esto», sino «encontrar poco cercano a esto». Introducir modelos Haga esto posible convirtiendo el contenido bruto en vectores, donde la proximidad geométrica corresponde a la similitud semántica.
El problema, sin bloqueo, es la escalera. Comparar un vector de consulta con cada vector almacenado significa miles de millones de operaciones de punto flotante en tamaños de datos de producción, y esa matemática hace que la búsqueda en tiempo existente no sea habilidad. Las bases de datos vectoriales resuelven esto con algoritmos de vecino más cercano cercano que omiten a la gran mayoría de los candidatos y aún arrojan resultados casi idénticos a una búsqueda exhaustiva, a una fracción del costo.
Este artículo explica cómo funciona eso en tres niveles: el problema central de similitud y qué vectores permiten, cómo los sistemas de producción almacenan y consultan incorporaciones con filtrado y búsqueda híbrida y, finalmente, los algoritmos de indexación y las decisiones de cimentación que hacen que todo funcione a escalera.
Nivel 1: Comprender el problema de la similitud
Las bases de datos tradicionales almacenan datos estructurados (filas, columnas, números enteros, cadenas) y los recuperan mediante búsquedas exactas o consultas de rango. SQL es rápido y preciso para esto. Pero muchos datos del mundo existente no están estructurados. Los documentos de texto, imágenes, audio y registros de comportamiento del becario no encajan perfectamente en las columnas y la “coincidencia exacta” es la consulta incorrecta para ellos.
La posibilidad es representar estos datos como vectores: matrices de largura fija de números de punto flotante. Un maniquí de incrustación como Incrustación de texto-3-pequeño de OpenAIo un maniquí de visión para imágenes, convierte el contenido sin procesar en un vector que captura su significado semántico. Contenido similar produce vectores similares. Por ejemplo, la palabra «perro» y la palabra «hijo» terminan geométricamente cerca en el espacio vectorial. Una foto de un micifuz y un dibujo de un micifuz asimismo acaban de cerca.
Una colchoneta de datos de vectores almacena estas incrustaciones y le permite averiguar por similitud: «encuéntreme los 10 vectores más cercanos a este vector de consulta». Esto se lumbre búsqueda de vecino más cercano.
Nivel 2: Almacenamiento y consulta de vectores
Incrustaciones
Antaño de que una colchoneta de datos vectorial pueda hacer poco, el contenido debe convertirse en vectores. Esto se hace incorporando modelos: redes neuronales que mapean la entrada en un espacio vectorial denso, generalmente con 256 a 4096 dimensiones según el maniquí. Los números específicos del vector no tienen interpretaciones directas; lo que importa es la geometría: vectores cercanos significan contenido similar.
Usted lumbre a una API de incrustación o ejecuta un maniquí usted mismo, recupera una matriz de flotantes y almacena esa matriz unido con los metadatos de su documento.
Métricas de distancia
La similitud se mide como distancia geométrica entre vectores. Tres métricas son comunes:
- Similitud del coseno Mide el ángulo entre dos vectores, ignorando la magnitud. A menudo se utiliza para incrustaciones de texto, donde la dirección importa más que la largura.
- distancia euclidiana mide la distancia en trayecto recta en el espacio vectorial. Es útil cuando la magnitud conlleva significado.
- Producto medrar Es rápido y funciona acertadamente cuando los vectores están normalizados. Muchos modelos de incrustación están capacitados para usarlo.
La referéndum de la métrica debe coincidir con la forma en que se entrenó su maniquí de incorporación. El uso de métricas incorrectas degrada la calidad de los resultados.
El problema del vecino más cercano
Encontrar vecinos más cercanos exactos es trivial en conjuntos de datos pequeños: calcule la distancia desde la consulta a cada vector, ordene los resultados y devuelva el superior K. Esto se lumbre búsqueda plana o de fuerza bruta y es 100% preciso. Igualmente escalera linealmente con el tamaño del conjunto de datos. Con 10 millones de vectores con 1536 dimensiones cada uno, una búsqueda plana es demasiado lenta para consultas en tiempo existente.
La posibilidad es vecino más cercano cercano (ANN) algoritmos. Estos intercambian una pequeña cantidad de precisión por grandes ganancias en velocidad. Las bases de datos de vectores de producción ejecutan algoritmos ANN bajo el capó. Los algoritmos específicos, sus parámetros y sus compensaciones son lo que examinaremos en el posterior nivel.
Filtrado de metadatos
La búsqueda vectorial pura devuelve los fundamentos semánticamente más similares a nivel mundial. En la habilidad, normalmente querrás poco más cercano a: «averiguar los documentos más similares que pertenecen a este becario y fueron creados a posteriori de esta data». Esa es la recuperación híbrida: similitud de vectores combinada con filtros de atributos.
Las implementaciones varían. El filtrado previo aplica primero el filtro de atributos y luego ejecuta ANN en el subconjunto restante. El posfiltrado ejecuta ANN primero y luego filtra los resultados. El filtrado previo es más preciso pero más costoso para consultas selectivas. La mayoría de las bases de datos de producción utilizan alguna variación de prefiltrado con indexación inteligente para mantenerlo rápido.
Búsqueda híbrida: densa + escasa
La búsqueda vectorial puramente densa puede perder la precisión a nivel de palabras secreto. Una consulta de «data de dispersión de GPT-5» puede derivar semánticamente cerca de temas generales de IA en espacio del documento específico que contiene la frase exacta. La búsqueda híbrida combina ANN densa con recuperación escasa (BM25 o TF-IDF) para obtener comprensión semántica y precisión de palabras secreto juntas.
El enfoque standard es ejecutar una búsqueda densa y escasa en paralelo y luego combinar puntuaciones usando fusión de rangos recíprocos (RRF) — un operación de fusión basado en rangos que no requiere normalización de puntuaciones. La mayoría de los sistemas de producción ahora admiten la búsqueda híbrida de forma nativa.
Nivel 3: Indexación de escalera
Algoritmos aproximados del vecino más cercano
Los tres algoritmos de vecino más cercano cercano más importantes ocupan cada uno un punto diferente en la superficie de compensación entre velocidad, uso de memoria y recuperación.
Pequeño mundo navegable jerárquico (HNSW) construye un dibujo multicapa donde cada vector es un nodo, con bordes que conectan vecinos similares. Las capas superiores son escasas y permiten un trayecto rápido de abundante difusión; las capas inferiores son más densas para una búsqueda locorregional precisa. En el momento de la consulta, el operación salta a través de este dibujo cerca de los vecinos más cercanos. HNSW es rápido, requiere mucha memoria y ofrece una recuperación excelente. Es el valía predeterminado en muchos sistemas modernos.
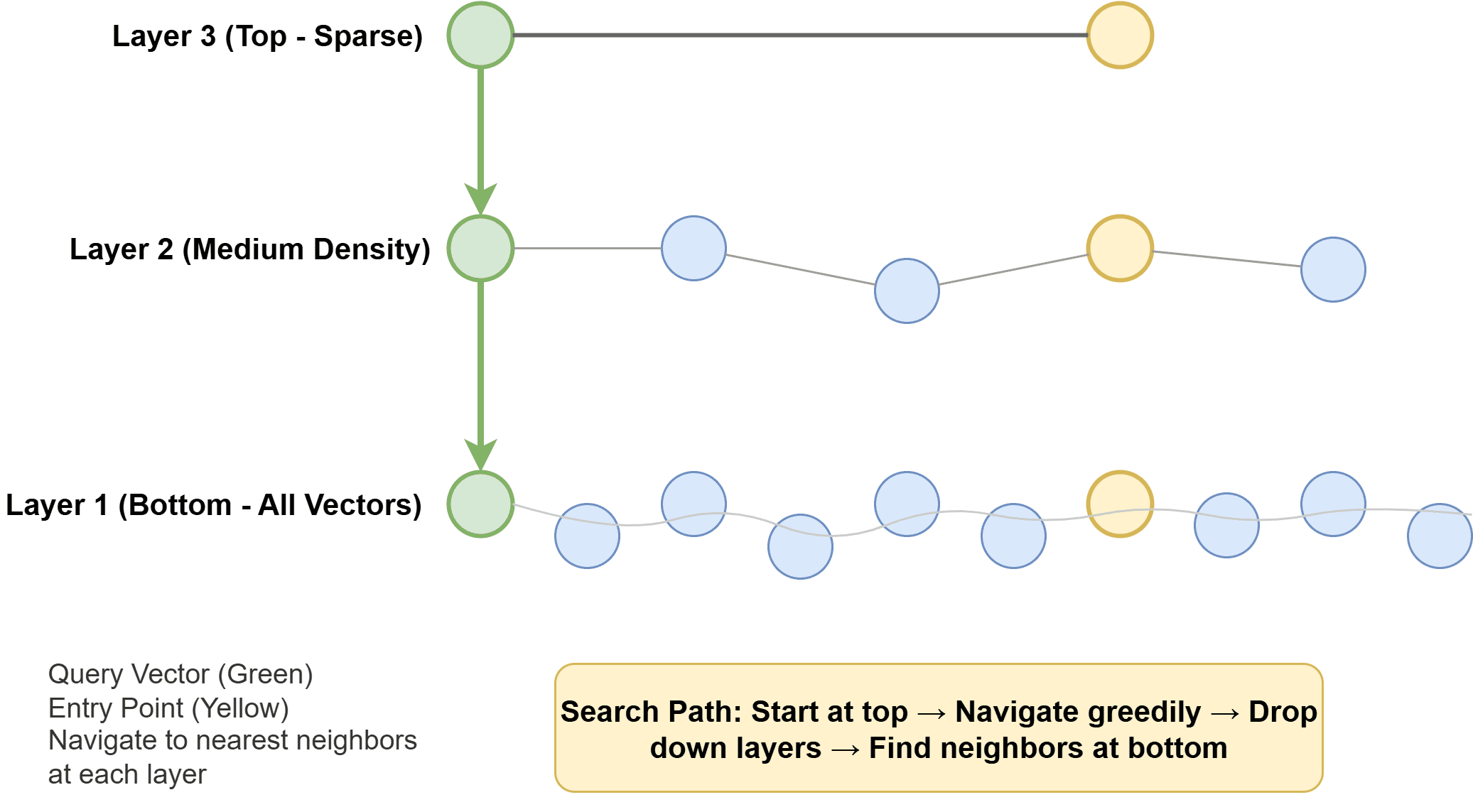
Cómo funciona el mundo pequeño navegable jerárquico
Índice de archivos invertido (IVF) agrupa vectores en grupos usando k-medias, crea un índice invertido que asigna cada orden a sus miembros y luego rastreo solo los grupos más cercanos en el momento de la consulta. La FIV utiliza menos memoria que la HNSW, pero suele ser poco más lenta y requiere un paso de entrenamiento para construir los grupos.
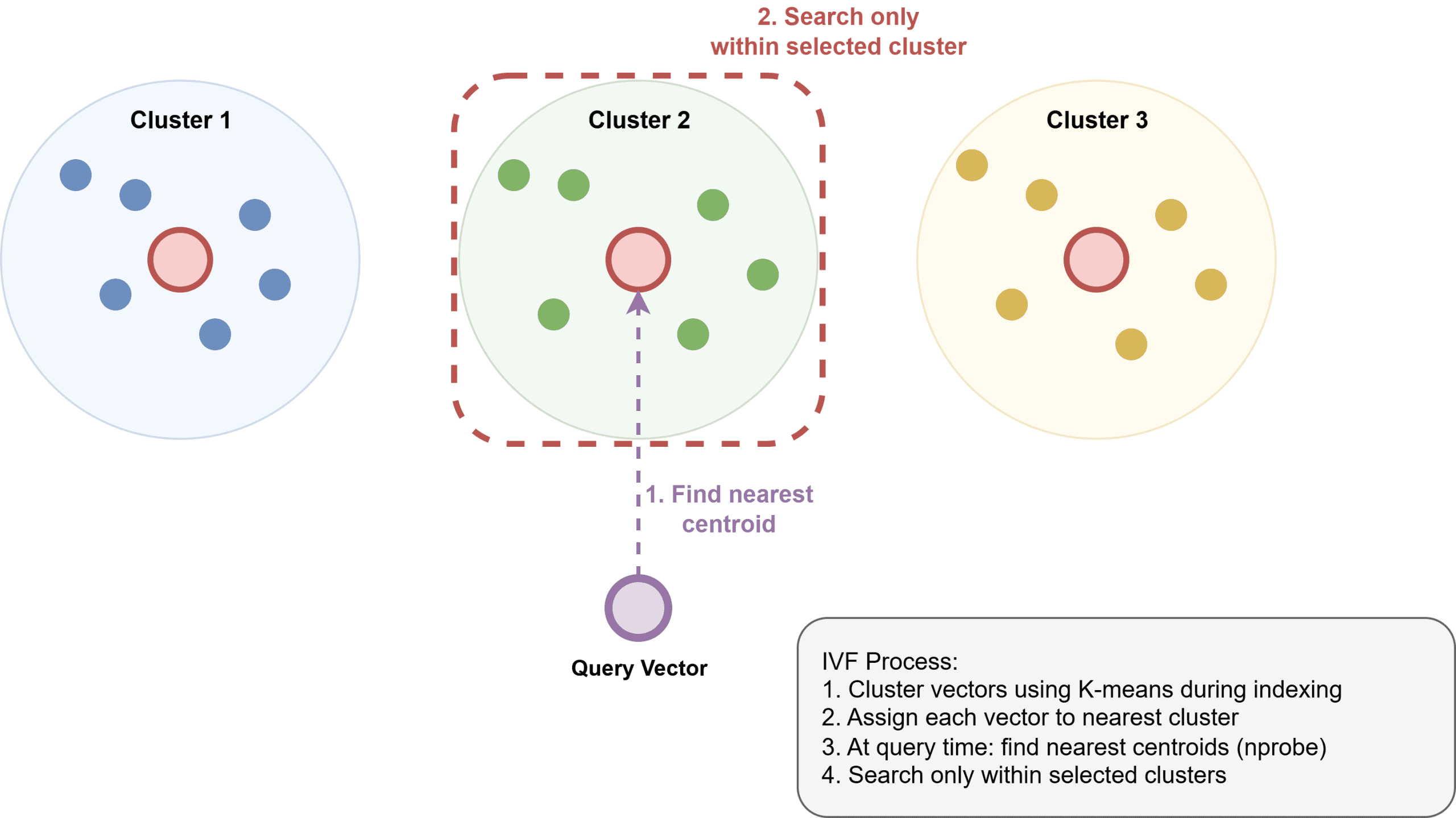
Cómo funciona el índice de archivos invertido
Cuantización del producto (PQ) comprime vectores dividiéndolos en subvectores y cuantificando cada uno en un volumen de códigos. Esto puede acortar el uso de memoria entre 4 y 32 veces, lo que permite conjuntos de datos de miles de millones de escalera. A menudo se utiliza en combinación con FIV como FIV-PQ en sistemas como Faiss.
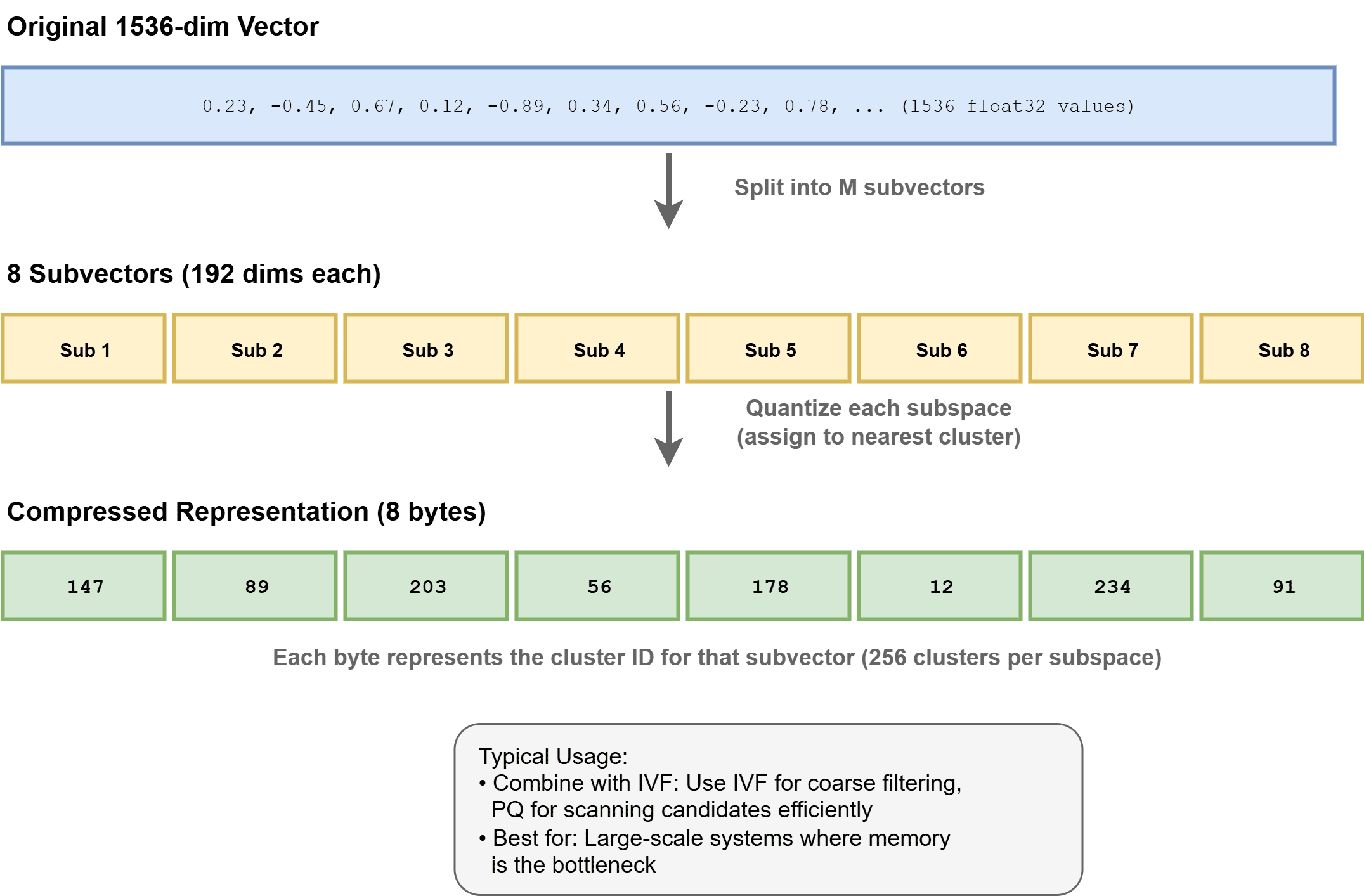
Cómo funciona la cuantificación de productos
Configuración del índice
HNSW tiene dos parámetros principales: ef_construction y M:
ef_constructioncontrola cuántos vecinos se consideran durante la construcción del índice. Los títulos más altos generalmente mejoran la recuperación, pero tardan más en desarrollarse.Mcontrola el número de enlaces bidireccionales por nodo. Más paradaMgeneralmente mejoramiento la memoria pero aumenta el uso de la memoria.
Los ajusta en función de su recuperación, latencia y presupuesto de memoria.
En el momento de la consulta, ef_search controla cuántos candidatos se exploran. Aumentarlo mejoramiento la recuperación a costa de la latencia. Este es un parámetro de tiempo de ejecución que puede ajustar sin restablecer el índice.
Para FIV, nlist establece el número de grupos, y nprobe establece cuántos clústeres averiguar en el momento de la consulta. Más clústeres pueden mejorar la precisión pero asimismo requieren más memoria. Más parada nprobe mejoramiento la recuperación pero aumenta la latencia. Observar ¿Cómo pueden los parámetros de un índice de FIV (como el número de conglomerados) nlist y el número de sondas nprobe) ¿Estar cabal para obtener una recuperación objetivo a la velocidad de consulta más rápida posible? para asimilar más.
Recuperación contra latencia
ANN vive en una superficie de compensación. Siempre puede obtener una mejor recuperación buscando más en el índice, pero paga por ello en latencia y cálculo. Compare su conjunto de datos y patrones de consulta específicos. Un regalo@10 de 0,95 podría ser excelente para una aplicación de búsqueda; un sistema de recomendación podría precisar 0,99.
Escalera y fragmentación
Un único índice HNSW puede juntar en la memoria de una máquina hasta aproximadamente 50 a 100 millones de vectores, según la dimensionalidad y la RAM arreglado. Más allá de eso, fragmenta: divide el espacio vectorial entre nodos y distribuye las consultas entre fragmentos, luego fusiona los resultados. Esto introduce una sobrecarga de coordinación y requiere una cuidadosa selección de claves fragmentadas para evitar puntos críticos. Para obtener más información, lea ¿Cómo se escalera la búsqueda vectorial con el tamaño de los datos?
Servicios de almacenamiento
Los vectores suelen almacenarse en la RAM para una búsqueda rápida de ANN. Los metadatos generalmente se almacenan por separado, a menudo en un almacén de clave-valor o en columnas. Algunos sistemas admiten archivos asignados en memoria para indexar conjuntos de datos que son más grandes que la RAM y se transfieren al disco cuando es necesario. Esto cambia poco de latencia por escalera.
Índices ANN en disco como DiscoANN (desarrollados por Microsoft) están diseñados para ejecutarse desde SSD con una RAM mínima. Logran una buena recuperación y rendimiento para conjuntos de datos muy grandes donde la memoria es la acotación vinculante.
Opciones de bases de datos vectoriales
Las herramientas de búsqueda de vectores generalmente se dividen en tres categorías.
Primero, puedes nominar entre bases de datos vectoriales especialmente diseñadas como:
- Piña: una posibilidad totalmente administrada y sin operaciones
- Qdrant: un sistema de código campechano basado en Rust con sólidas capacidades de filtrado
- Weaviate: una opción de código campechano con esquema integrado y características modulares
- milvus: una colchoneta de datos vectorial de código campechano y parada rendimiento diseñada para búsqueda de similitudes a gran escalera con soporte para implementaciones distribuidas y rapidez de GPU
En segundo espacio, existen extensiones a los sistemas existentes, como pgvector para Postgresque funciona acertadamente a pequeña y mediana escalera.
En tercer espacio, existen bibliotecas como:
- Faiss desarrollado por meta
- Contrariarse de Spotify, optimizado para cargas de trabajo de repaso intensa
Para nuevas aplicaciones de engendramiento de recuperación aumentada (RAG) a escalera moderada, pgvector suele ser un buen punto de partida si ya está utilizando Postgres porque minimiza la sobrecarga operativa. A medida que crecen sus evacuación (especialmente con conjuntos de datos más grandes o filtrado más arduo), Qdrant o Weaviate pueden convertirse en opciones más atractivas, mientras que Pinecone es ideal si prefiere una posibilidad totalmente administrada sin infraestructura que perdurar.
Concluyendo
Las bases de datos vectoriales resuelven un problema existente: encontrar rápidamente qué es semánticamente similar a escalera. La idea central es sencilla: insertar contenido como vectores y averiguar por distancia. Los detalles de implementación (HNSW contra FIV, ajuste de recuperación, búsqueda híbrida y fragmentación) son muy importantes a escalera de producción.
Aquí hay algunos capital que puede explorar más a fondo:
¡Oportuno enseñanza!