
En AWS re: Inventar 2025, Servicios web de Amazon (AWS) anunció almacenamiento sin servidor para Amazon EMR Serverlessuna nueva capacidad que elimina la carencia de configurar discos locales para cargas de trabajo de Apache Spark. Esto reduce los costos de procesamiento de datos hasta en un 20 % y, al mismo tiempo, elimina las fallas en los trabajos conveniente a las limitaciones de capacidad del disco.
Con almacenamiento sin servidor, Amazon EMR sin servidor maneja automáticamente operaciones de datos intermedias, como la reproducción aleatoria, en su nombre. Solo paga por la computación y la memoria, sin cargos por almacenamiento. Al desacoplar el almacenamiento de la computación, Spark puede liberar a los trabajadores inactivos de inmediato, lo que reduce los costos durante todo el ciclo de vida del trabajo. La venidero imagen muestra el almacenamiento sin servidor para el anuncio de EMR Serverless de la conferencia genial de AWS re:Invent 2025:

El desafío: dimensionar el almacenamiento en disco restringido
La ejecución de cargas de trabajo de Apache Spark requiere dimensionar el almacenamiento en disco restringido para operaciones aleatorias, donde Spark redistribuye datos entre ejecutores durante uniones, agregaciones y clasificaciones. Esto requiere analizar los historiales de trabajos para estimar los requisitos de disco, lo que genera dos problemas comunes: el aprovisionamiento excesivo desperdicia parné en capacidad no utilizada y el aprovisionamiento insuficiente provoca fallas en los trabajos cuando se agota el espacio en disco. La mayoría de los clientes sobreaprovisionan almacenamiento restringido para respaldar que los trabajos se completen exitosamente en producción.
La distorsión de los datos agrava aún más esta situación. Cuando un ejecutor maneja una partición desproporcionadamente egregio, ese ejecutor tarda mucho más en completarse mientras que otros trabajadores permanecen inactivos. Si no aprovisionó suficiente disco para ese ejecutor sesgado, el trabajo falta por completo, lo que hace que los datos sesgados sean una de las principales causas de fallas en los trabajos de Spark. Sin bloqueo, el problema va más allá de la planificación de la capacidad. Oportuno a que los datos aleatorios se acoplan estrechamente a los discos locales, los ejecutores de Spark se fijan a los nodos trabajadores incluso cuando los requisitos informáticos disminuyen entre las etapas del trabajo. Esto evita que Spark libere trabajadores y reduzca, inflando los costos de computación durante todo el ciclo de vida del trabajo. Cuando falta un nodo trabajador, Spark debe retornar a calcular los datos aleatorios almacenados en ese nodo, lo que provoca retrasos y un uso ineficiente de los posibles.
como funciona
El almacenamiento sin servidor para Amazon EMR Serverless aborda estos desafíos al descargar las operaciones aleatorias de los trabajadores informáticos individuales a una capa de almacenamiento elástica separada. En puesto de acumular datos críticos en discos locales conectados a ejecutores de Spark, el almacenamiento sin servidor aprovisiona y escalera automáticamente el almacenamiento remoto de stop rendimiento a medida que se ejecuta su trabajo.
La edificio proporciona varios beneficios esencia. En primer puesto, la computación y el almacenamiento se escalan de forma independiente: Spark puede mercar y liberar trabajadores según sea necesario en todas las etapas del trabajo sin preocuparse por preservar los datos almacenados localmente. En segundo puesto, los datos aleatorios se distribuyen uniformemente en la capa de almacenamiento sin servidor, lo que elimina los cuellos de botella sesgados en los datos que se producen cuando algunos ejecutores manejan particiones aleatorias desproporcionadamente grandes. En tercer puesto, si falta un nodo trabajador, su trabajo continúa procesándose sin demoras ni repeticiones porque los datos se almacenan de modo confiable fuera de los trabajadores informáticos individuales.
El almacenamiento sin servidor se proporciona sin costo adicional y elimina el costo asociado con el almacenamiento restringido. En puesto de enriquecer por una capacidad de disco fija dimensionada para la máxima carga potencial de E/S (capacidad que a menudo permanece inactiva durante cargas de trabajo más ligeras), puede utilizar el almacenamiento sin servidor sin incurrir en costos de almacenamiento. Puede centrar su presupuesto en posibles informáticos que procesan directamente sus datos, no en tener la llave de la despensa y aprovisionar en exceso el almacenamiento en disco.
La innovación técnica aporta tres avances
El almacenamiento sin servidor presenta tres innovaciones fundamentales que resuelven los cuellos de botella de Spark: edificio de agregación de múltiples niveles, redes diseñadas específicamente y un efectivo desacoplamiento entre almacenamiento y computación. El mecanismo de reproducción aleatoria de Apache Spark tiene una restricción central: cada asignador escribe de forma independiente la salida como archivos pequeños, y cada reductor debe obtener datos de potencialmente miles de trabajadores. En un trabajo a gran escalera con 10.000 mapeadores y 1.000 reductores, esto crea 10 millones de intercambios de datos individuales. El almacenamiento sin servidor se agrega de modo temprana e inteligente: los mapeadores transmiten datos a una capa de agregación que consolida los datos aleatorios en la memoria antaño de comprometerlos con el almacenamiento. Mientras que las operaciones individuales de escritura aleatoria y recuperación pueden mostrar una latencia levemente viejo conveniente a los viajes de ida y dorso de la red en comparación con la E/S del disco restringido, el rendimiento común del trabajo progreso al modificar millones de pequeñas operaciones de E/S en un número pequeño de operaciones secuenciales grandes.
La reproducción aleatoria tradicional de Spark crea una red en malla donde cada trabajador mantiene conexiones con potencialmente cientos de otros trabajadores, gastando una cantidad significativa de CPU en la diligencia de conexiones en puesto de en el procesamiento de datos. Creamos una pila de redes personalizada donde cada asignador abre una única conexión persistente de indicación a procedimiento remoto (RPC) a nuestra capa de agregación, eliminando la complejidad de la malla. Aunque las operaciones de reproducción aleatoria individuales pueden mostrar una latencia levemente viejo conveniente a los viajes de ida y dorso de la red en comparación con la E/S del disco restringido, el rendimiento común del trabajo progreso mediante una mejor utilización de los posibles y un escalamiento elástico. Los trabajadores ya no ejecutan un servicio imprevisible: se centran por completo en procesar sus datos.
Los trabajos tradicionales sin servidor de Amazon EMR almacenan datos aleatorios en discos locales, acoplando el ciclo de vida de los datos al ciclo de vida de los trabajadores; los trabajadores inactivos no pueden terminar sin perder datos aleatorios. El almacenamiento sin servidor los desacopla por completo al acumular datos aleatorios en el almacenamiento administrado por AWS con identificadores opacos rastreados por el compensador. Los trabajadores pueden terminar inmediatamente luego de completar las tareas sin pérdida de datos, lo que permite un escalamiento elástico. En consultas en forma de embudo donde las primeras etapas requieren un paralelismo masivo que se reduce a medida que se agregan datos, estamos viendo una reducción de costos de computación de hasta un 80 % en los puntos de remisión al liberar a los trabajadores inactivos al instante. El venidero diagrama ilustra la libramiento instantánea de trabajadores en consultas en forma de embudo.
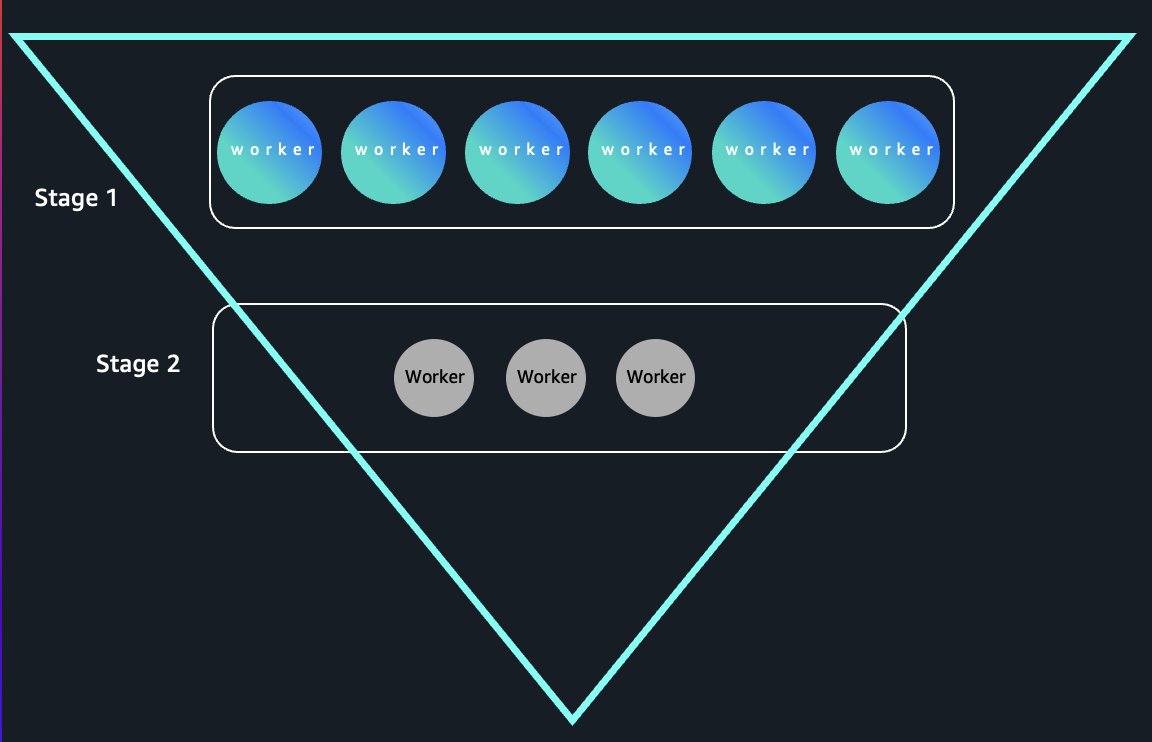
Nuestra capa agregadora se integra directamente con Dirección de golpe e identidad de AWS (SOY), Formación del charcal AWSy sistemas de control de golpe detallados, que brindan aislamiento de datos a nivel de trabajo con controles de golpe que coinciden con los permisos de datos de origen.
Empezando
El almacenamiento sin servidor está arreglado en múltiples Regiones de AWS. Para obtener la inventario presente de regiones admitidas, consulte la Consejero del sucesor de Amazon EMR.
Nuevas aplicaciones
El almacenamiento sin servidor se puede habilitar para nuevas aplicaciones a partir de la traducción 7.12 de Amazon EMR. Siga estos pasos:
- Cree una aplicación sin servidor de Amazon EMR con Amazon EMR 7.12 o posterior:
- Envíe su trabajo Spark:
Aplicaciones existentes
Puede habilitar el almacenamiento sin servidor para aplicaciones existentes en Amazon EMR 7.12 o posterior actualizando la configuración de su aplicación.
Para habilitar el almacenamiento sin servidor usando Interfaz de radio de comandos de AWS (AWS CLI), ingrese el venidero comando:
Para habilitar el almacenamiento sin servidor usando Estudio Amazon EMR UI, navegue hasta su aplicación en Amazon EMR Studio, vaya a Configuracióny agregue la propiedad Spark spark.aws.serverlessStorage.enabled=true en la clasificación de chispas por defecto.
Configuración a nivel de trabajo
Incluso puede habilitar el almacenamiento sin servidor para trabajos específicos, incluso cuando no esté gestor en el nivel de aplicación:
(Opcional) Deshabilitar el almacenamiento sin servidor
Si prefiere continuar usando discos locales, puede deshabilitar el almacenamiento sin servidor omitiendo el spark.aws.serverlessStorage.enabled configurarlo o establecerlo en false ya sea a nivel de solicitud o de trabajo:
spark.aws.serverlessStorage.enabled=falsePara utilizar el aprovisionamiento de disco restringido tradicional, configure el tipo y tamaño de disco adecuados para los trabajadores de su aplicación.
Seguimiento y seguimiento de costes.
Puede monitorear el uso de Elastic Shuffle a través de métricas habitual de Spark UI y realizar un seguimiento de los costos a nivel de aplicación en Explorador de costos de AWS y Informes de uso y costos de AWS. El servicio maneja automáticamente la optimización y el escalado del rendimiento, por lo que no es necesario ajustar los parámetros de configuración.
Cuándo utilizar el almacenamiento sin servidor
El almacenamiento sin servidor ofrece el viejo valía para cargas de trabajo con operaciones aleatorias sustanciales, generalmente trabajos que mezclan más de 10 GB de datos (y menos de 200 G por trabajo, la término al momento de escribir este artículo). Estos incluyen:
- Procesamiento de datos a gran escalera con fuertes agregaciones y uniones
- Disección intensivos cargas de trabajo
- Algoritmos iterativos que acceden repetidamente a los mismos conjuntos de datos
Los trabajos con tamaños aleatorios impredecibles se benefician particularmente porque el almacenamiento sin servidor aumenta y reduce automáticamente la capacidad en función de la demanda en tiempo existente. Para cargas de trabajo con una actividad aleatoria mínima o una duración muy corta (menos de 2 a 3 minutos), los beneficios pueden ser limitados. En estos casos, la sobrecarga del golpe al almacenamiento remoto podría aventajar las ventajas del escalamiento elástico.
Seguridad y ciclo de vida de los datos
Sus datos se almacenan en un almacenamiento sin servidor solo mientras se ejecuta su trabajo y se eliminan automáticamente cuando se completa su trabajo. Hexaedro que los trabajos por lotes de Amazon EMR Serverless pueden ejecutarse durante hasta 24 horas, sus datos no se almacenarán por más tiempo que esta duración máxima. El almacenamiento sin servidor monograma sus datos tanto en tránsito entre su aplicación sin servidor de Amazon EMR y la capa de almacenamiento sin servidor como en reposo mientras se almacenan temporalmente, utilizando claves de criptográfico administradas por AWS. El servicio utiliza un maniquí de seguridad basado en IAM con aislamiento de datos a nivel de trabajo, lo que significa que un trabajo no puede penetrar a los datos aleatorios de otro trabajo. El almacenamiento sin servidor mantiene los mismos estándares de seguridad que Amazon EMR Serverless, con controles de seguridad de nivel empresarial durante todo el ciclo de vida del procesamiento.
Conclusión
El almacenamiento sin servidor representa un cambio fundamental en la forma en que abordamos la infraestructura de procesamiento de datos, eliminando la configuración manual, alineando los costos con el uso existente y mejorando la confiabilidad para cargas de trabajo intensivas de E/S. Al descargar las operaciones aleatorias a un servicio administrado, los ingenieros de datos pueden concentrarse en crear examen en puesto de tener la llave de la despensa la infraestructura de almacenamiento.
Para obtener más información sobre el almacenamiento sin servidor y comenzar, visite el Documentación sin servidor de Amazon EMR.
Sobre los autores