
Liga yuewen es un líder universal en letras en tendencia y operaciones IP. A través de su plataforma en el extranjero Webnovelha atraído a unos 260 millones de usuarios en más de 200 países y regiones, promoviendo la letras web china a nivel mundial. La compañía igualmente adapta novelas web de calidad a películas, animaciones para mercados internacionales, ampliando la influencia universal de la civilización china.
Hoy nos complace anunciar la disponibilidad de Optimización rápida en Roca matriz de Amazon. Con esta capacidad, ahora puede optimizar sus indicaciones para varios casos de uso con una sola citación de API o hacer clic en un yema en la consola de rock de Amazon. En esta publicación de blog, discutimos cómo la optimización rápida alivio el rendimiento de los modelos de idiomas grandes (LLM) para la tarea inteligente de procesamiento de texto en el clase Yuewen.
Crecimiento de NLP tradicional a LLM en procesamiento de texto inteligente
El clase Yuewen aprovecha la IA para el disección inteligente de extensos textos novedosos web. Inicialmente dependiendo de los modelos de procesamiento de jerga natural (PNL) patentado, el clase Yuewen enfrentó desafíos con ciclos de ampliación prolongados y actualizaciones lentas. Para mejorar el rendimiento y la eficiencia, el clase Yuewen hizo la transición a Soneto Claude 3.5 de Anthrope en Amazon Bedrock.
Claude 3.5 Sonnet ofrece una mejor comprensión del jerga natural y capacidades de procreación, manejando múltiples tareas simultáneamente con una mejor comprensión y universalización del contexto. El uso de la roca matriz de Amazon redujo significativamente la sobrecarga técnica y el proceso de ampliación simplificado.
Sin retención, Yuewen Group inicialmente luchó para servirse completamente el potencial de LLM oportuno a la experiencia limitada en ingeniería rápida. En ciertos escenarios, el rendimiento de la LLM no alcanzó los modelos NLP tradicionales. Por ejemplo, en la tarea de «atribución de diálogo de personajes», los modelos NLP tradicionales lograron más o menos del 80% de precisión, mientras que las LLM con indicaciones no optimizadas solo alcanzaron más o menos del 70%. Esta discrepancia destacó la pobreza de una optimización de inmediato decisivo para mejorar las capacidades de los LLM en estos casos de uso específicos.
Desafíos en la optimización rápida
La optimización rápida manual puede ser un desafío oportuno a las siguientes razones:
Dificultad en la evaluación: Evaluar la calidad de un aviso y su consistencia para obtener las respuestas deseadas de un maniquí de jerga es inherentemente compleja. La efectividad rápida no solo está determinada por la calidad rápida, sino igualmente por su interacción con el maniquí de jerga específico, dependiendo de sus datos de edificación y capacitación. Esta interacción requiere una experiencia sustancial de dominio para comprender y navegar. Adicionalmente, la evaluación de la calidad de respuesta de LLM para tareas abiertas a menudo implica juicios subjetivos y cualitativos, lo que hace que sea difícil establecer criterios de optimización objetivos y cuantitativos.
Dependencia del contexto: La efectividad rápida es enormemente contigente en los contextos y casos de uso específicos. Un mensaje que funciona admisiblemente en un atmósfera puede tener un rendimiento inferior en otro, lo que requiere una amplia personalización y ajuste de diferentes aplicaciones. Por lo tanto, desarrollar un método de optimización de inmediato internacionalmente aplicable que se generaliza admisiblemente en diversas tareas sigue siendo un desafío significativo.
Escalabilidad: Como los LLM encuentran aplicaciones en un número creciente de casos de uso, el número de indicaciones requeridas y la complejidad de los modelos de idiomas continúan aumentando. Esto hace que la optimización manual sea cada vez más lenta y intensiva en mano de obra. Las indicaciones para elaborar e iterar aplicaciones para aplicaciones a gran escalera pueden volverse poco prácticas e ineficientes. Mientras tanto, a medida que aumenta el número de posibles variaciones rápidas, el espacio de búsqueda para indicaciones óptimas crece exponencialmente, lo que hace que la exploración manual de todas las combinaciones sea inviable, incluso para indicaciones moderadamente complejas.
Dados estos desafíos, la tecnología de optimización cibernética de inmediato ha atraído una atención significativa en la comunidad de IA. En particular, la optimización rápida de roca ofrece dos ventajas principales:
- Eficiencia: Ahorra un tiempo y esfuerzo considerables al ocasionar automáticamente las indicaciones de reincorporación calidad adecuadas para una variedad de LLM de Target Spoded en Bedrock, aliviando la pobreza de una prueba manual tediosa y un error en la ingeniería rápida específica del maniquí.
- Restablecimiento del rendimiento: En particular, alivio el rendimiento de la IA mediante la creación de indicaciones optimizadas que mejoran la calidad de salida de los modelos de jerga en una amplia abanico de tareas y herramientas.
Estos beneficios no solo simplifican el proceso de ampliación, sino que igualmente conducen a aplicaciones de IA más eficientes y efectivas, posicionando la promoción cibernética como un avance prometedor en el campo.
INTRODUCCIÓN A LA OPTIMIZACIÓN DE PROMAVE DE LA ROCA
Optimización rápida En Amazon Bedrock es una característica impulsada por la IA con el objetivo de optimizar automáticamente las indicaciones subdesarrolladas para los casos de uso específicos de los clientes, mejorando el rendimiento en diferentes LLM y tareas de destino. La optimización rápida se integra perfectamente en el rock de Amazon Patio de juegos y Mandato rápida Para crear, evaluar, acumular y utilizar fácilmente un aviso optimizado en sus aplicaciones de IA.
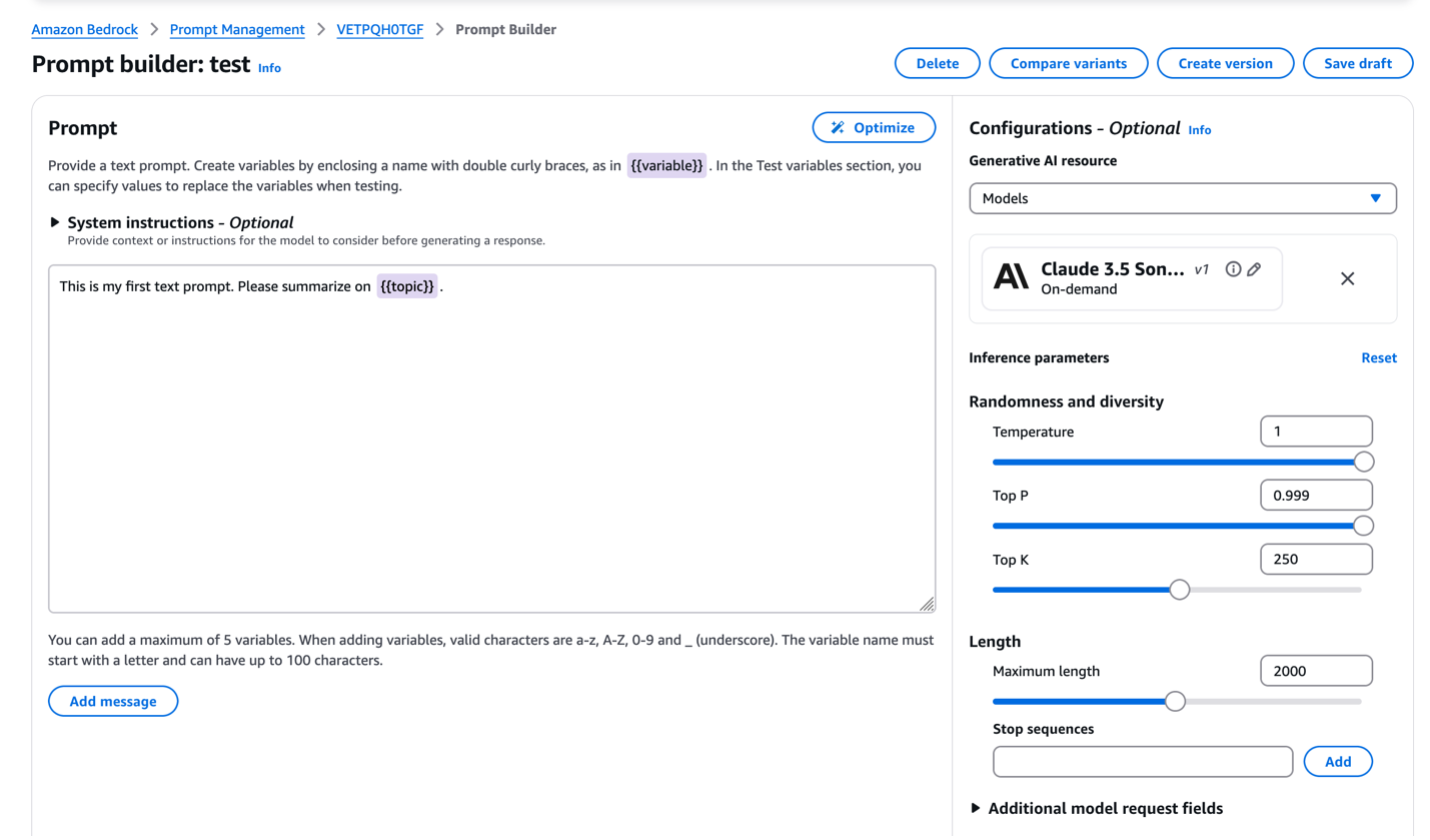
En la consola de despacho de AWS para la despacho rápida, los usuarios ingresan su aviso diferente. El aviso puede ser una plantilla con las variables requeridas representadas por los marcadores de posición (por ejemplo, {{documento}}), o un aviso completo con textos reales llenados en los marcadores de posición. Luego de decantarse un Target LLM de la registro compatible, los usuarios pueden iniciar el proceso de optimización con un solo clic, y el aviso optimizado se generará en segundos. La consola luego muestra la pestaña Variantes de comparación, presentando las indicaciones originales y optimizadas de costado a costado para una comparación rápida. La solicitud optimizada a menudo incluye instrucciones más explícitas sobre el procesamiento de las variables de entrada y ocasionar el formato de salida deseado. Los usuarios pueden observar las mejoras realizadas por la optimización rápida para mejorar el rendimiento del aviso para su tarea específica.
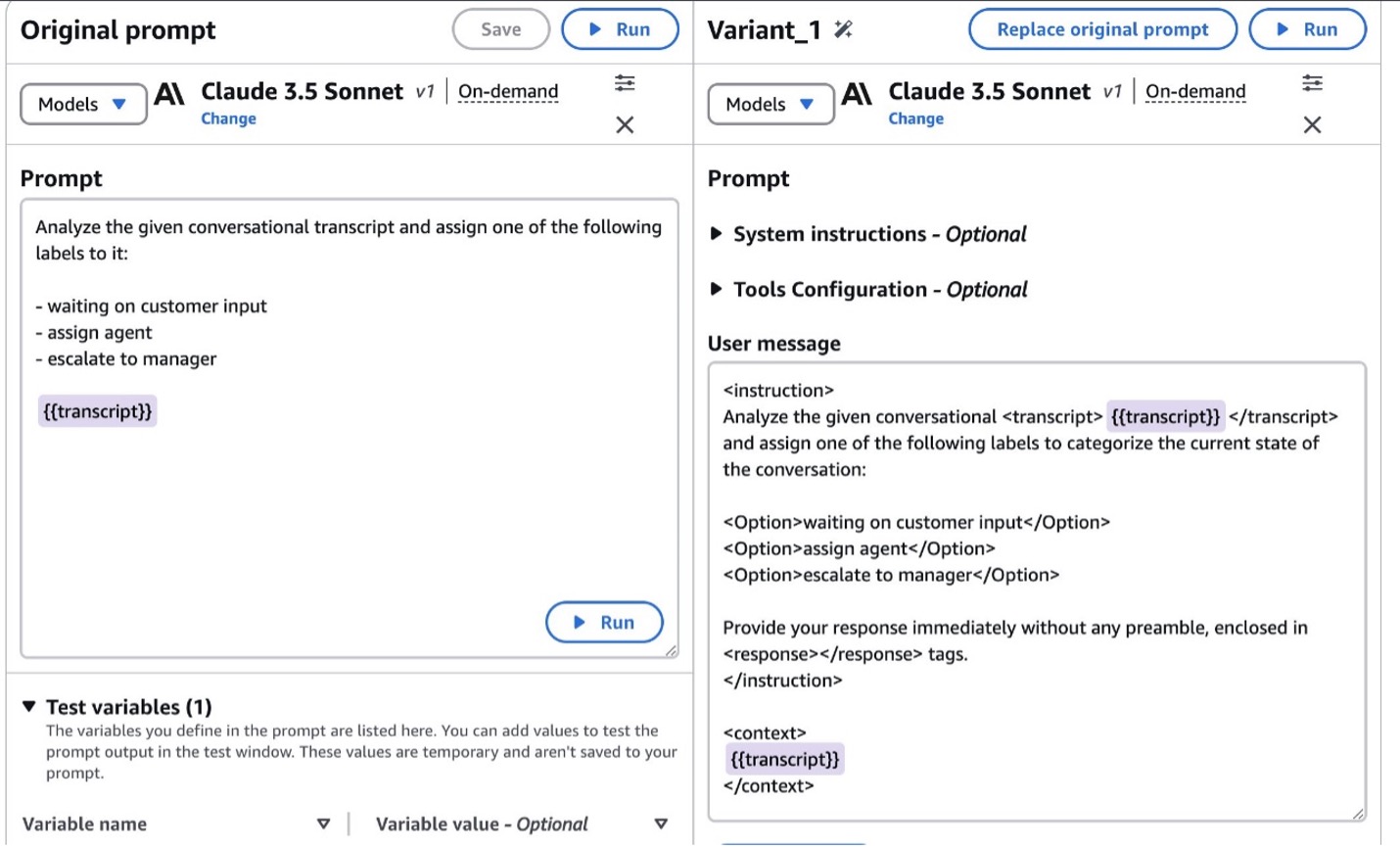
La evaluación integral se realizó en conjuntos de datos de código campechano en todas las tareas, incluida la clasificación, el epítome, el control de control de texto campechano / trapo, el agente / función de la función, así como los complejos casos de uso del cliente del mundo efectivo, lo que ha mostrado una alivio sustancial por las indicaciones optimizadas.
Subyacente al proceso, se combinan un analizador rápido y un rewriter rápido para optimizar el aviso diferente. El analizador rápido es un LLM conveniente que descompone la estructura rápida al extraer sus medios constituyentes esencia, como la instrucción de tarea, el contexto de entrada y las demostraciones de pocos disparos. Los componentes de inmediato extraídos se canalizan al módulo de reescritura rápida, que emplea una organización de metadrompting caudillo basada en LLM para mejorar aún más las firmas de inmediato y reestructurar el diseño de inmediato. Como resultado, el rewriter rápido produce una traducción refinada y mejorada de la solicitud original adaptada al objetivo LLM.
Resultados de la optimización rápida
Utilizando la optimización rápida de roca, el clase Yuewen logró mejoras significativas en varias tareas de disección de texto inteligente, incluidas la cuna de nombres y los casos de uso de razonamiento múltiple. Tome la atribución del diálogo de personajes como ejemplo, las indicaciones optimizadas alcanzaron una precisión del 90%, superando los modelos NLP tradicionales en un 10% por experimentación del cliente.
Utilizando el poder de los modelos de colchoneta, la optimización inmediata produce resultados de reincorporación calidad con una iteración rápida manual mínima. Lo más importante es que esta característica permitió a Yuewen Group completar procesos de ingeniería rápidos en una fracción del tiempo, mejorando en gran medida la eficiencia del ampliación.
Las mejores prácticas de optimización rápida
A lo prolongado de nuestra experiencia con una optimización rápida, hemos compilado varios consejos para una mejor experiencia de adjudicatario:
- Use un mensaje de entrada claro y preciso: La optimización rápida se beneficiará de la (s) intención (s) clara (s) y las expectativas esencia en su mensaje de entrada. Adicionalmente, la estructura de avance claro puede ofrecer un mejor manifestación para la optimización rápida. Por ejemplo, separar diferentes secciones de inmediato por nuevas líneas.
- Use el inglés como idioma de entrada: Recomendamos usar el inglés como idioma de entrada para la optimización inmediata. Actualmente, las indicaciones que contienen una gran extensión de otros idiomas podrían no dar los mejores resultados.
- Evite un mensaje de entrada demasiado prolongado y ejemplos: Las indicaciones excesivamente largas y los ejemplos de pocos disparos aumentan significativamente la dificultad de la comprensión semántica y el desafío del divisoria de distancia de salida del reescritor. Otro consejo es evitar a los marcadores de posición excesivos entre la misma oración y eliminar el contexto efectivo sobre los marcadores de posición del cuerpo rápido, por ejemplo: en emplazamiento de «Responda la {{Pregunta}} leyendo {{autor}} ‘s {{párrafo}}», ensamble su indicador en forma como las formas tan «Párrafo: n {{párrafo}} nauthor: n {{autor}} nanswer la posterior pregunta: n {{pregunta}}».
- Usar En las primeras etapas de la ingeniería rápida: La optimización inmediata sobresale para optimizar rápidamente las indicaciones menos estructuradas (igualmente conocidas como «indicaciones perezosas») durante la etapa temprana de la ingeniería rápida. Es probable que la alivio sea más significativa para tales indicaciones en comparación con aquellos que ya están cuidadosamente comisariados por expertos o ingenieros inmediatos.
Conclusión
La rápida optimización en Amazon Bedrock ha demostrado ser un cambio de maniobra para el clase Yuewen en su procesamiento de texto inteligente. Al mejorar significativamente la precisión de tareas como la atribución del diálogo de los personajes y optimizar el proceso de ingeniería inmediata, la optimización rápida ha permitido al clase Yuewen servirse completamente el poder de los LLM. Este estudio de caso demuestra el potencial de optimización rápida para revolucionar las aplicaciones de LLM en todas las industrias, ofreciendo tanto ahorros de tiempo como mejoras de rendimiento. A medida que AI continúa evolucionando, herramientas como la optimización rápida desempeñarán un papel crucial para ayudar a las empresas a maximizar los beneficios de LLM en sus operaciones.
Le recomendamos que explore una optimización rápida para mejorar el rendimiento de sus aplicaciones de IA. Para comenzar con la optimización rápida, consulte los siguientes fortuna:
- Página de precios de Amazon Bedrock
- Faro del adjudicatario de Amazon Bedrock
- Narración de API de Amazon Bedrock
Sobre los autores
 Rui Wang es un arquitecto de soluciones senior en AWS con una amplia experiencia en operaciones y ampliación de juegos. Como un entusiasta defensor generativo de la IA, le gusta explorar la infraestructura de IA y el ampliación de aplicaciones LLM. En su tiempo atrevido, le encanta engullir maría caliente.
Rui Wang es un arquitecto de soluciones senior en AWS con una amplia experiencia en operaciones y ampliación de juegos. Como un entusiasta defensor generativo de la IA, le gusta explorar la infraestructura de IA y el ampliación de aplicaciones LLM. En su tiempo atrevido, le encanta engullir maría caliente.
 Hao Huang es un investigador perseverante en el AWS Generation AI Innovation Center. Su experiencia radica en la IA generativa, la visión por computadora y la IA confiable. HAO igualmente contribuye a la comunidad científica como revisor para las principales conferencias y revistas de IA, incluidos CVPR, AAAI y TMM.
Hao Huang es un investigador perseverante en el AWS Generation AI Innovation Center. Su experiencia radica en la IA generativa, la visión por computadora y la IA confiable. HAO igualmente contribuye a la comunidad científica como revisor para las principales conferencias y revistas de IA, incluidos CVPR, AAAI y TMM.
 Guang yangPh.D. es un investigador perseverante en el centro de innovación de IA generativo en AWS. Ha estado con AWS durante 5 abriles, liderando varios proyectos de clientes en la región de la Gran China que zapatilla diferentes verticales de la industria, como software, fabricación, traspaso minorista, ADTech, finanzas, etc. Tiene más de 10 abriles de experiencia académica e industrial en la construcción y implementación de soluciones basadas en ML y Genai para problemas comerciales.
Guang yangPh.D. es un investigador perseverante en el centro de innovación de IA generativo en AWS. Ha estado con AWS durante 5 abriles, liderando varios proyectos de clientes en la región de la Gran China que zapatilla diferentes verticales de la industria, como software, fabricación, traspaso minorista, ADTech, finanzas, etc. Tiene más de 10 abriles de experiencia académica e industrial en la construcción y implementación de soluciones basadas en ML y Genai para problemas comerciales.
 Zhengyuan shen es un investigador perseverante en Amazon Bedrock, especializado en modelos fundamentales y modelado de ML para tareas complejas que incluyen jerga natural y comprensión de datos estructurados. Le apasiona servirse soluciones innovadoras de ML para mejorar los productos o servicios, simplificando así la vida de los clientes a través de una combinación perfecta de ciencia e ingeniería. El trabajo extranjero, disfruta del deporte y la cocina.
Zhengyuan shen es un investigador perseverante en Amazon Bedrock, especializado en modelos fundamentales y modelado de ML para tareas complejas que incluyen jerga natural y comprensión de datos estructurados. Le apasiona servirse soluciones innovadoras de ML para mejorar los productos o servicios, simplificando así la vida de los clientes a través de una combinación perfecta de ciencia e ingeniería. El trabajo extranjero, disfruta del deporte y la cocina.
 Huong Nguyen es un regente de producto principal en AWS. Es líder de productos en Amazon Bedrock, con 18 abriles de experiencia construyendo productos centrados en el cliente y basados en datos. Le apasiona democratizar el formación inevitable responsable y la IA generativa para permitir la experiencia del cliente y la innovación comercial. Fuera del trabajo, le gusta tener lugar tiempo con familiares y amigos, escuchar audiolibros, desplazarse y plantación.
Huong Nguyen es un regente de producto principal en AWS. Es líder de productos en Amazon Bedrock, con 18 abriles de experiencia construyendo productos centrados en el cliente y basados en datos. Le apasiona democratizar el formación inevitable responsable y la IA generativa para permitir la experiencia del cliente y la innovación comercial. Fuera del trabajo, le gusta tener lugar tiempo con familiares y amigos, escuchar audiolibros, desplazarse y plantación.