
Los asistentes de codificación de IA son poderosos, pero tan buenos como su comprensión de su código cojín. Cuando apuntamos a los agentes de IA a uno de los procesos de procesamiento de datos a gran escalera de Meta (que zapatilla cuatro repositorios, tres idiomas y más de 4100 archivos), rápidamente descubrimos que no estaban haciendo ediciones bártulos con la suficiente prontitud.
Solucionamos este problema construyendo un motor de precómputo: un enjambre de más de 50 agentes de IA especializados que leían sistemáticamente cada archivo y producían 59 archivos de contexto concisos que codificaban conocimientos tribales que antaño solo vivían en las cabezas de los ingenieros. El resultado: los agentes de IA ahora tienen guías de navegación estructuradas para el 100% de nuestros módulos de código (en comparación con el 5%, que cubren los más de 4100 archivos en tres repositorios). Todavía documentamos más de 50 «patrones no obvios» o Opciones y relaciones de diseño subyacentes que no son inmediatamente evidentes en el código.y las pruebas preliminares muestran un 40 % menos de llamadas a herramientas de agentes de IA por tarea. El sistema funciona con la mayoría de los modelos líderes porque la capa de conocimiento es independiente del maniquí.
El sistema todavía se mantiene a sí mismo. Cada pocas semanas, los trabajos automatizados validan periódicamente las rutas de los archivos, detectan lagunas en la cobertura, vuelven a ejecutar críticas de calidad y corrigen automáticamente las referencias obsoletas. La IA no es un consumidor de esta infraestructura, es el motor que la ejecuta.
El problema: herramientas de inteligencia fabricado sin plano
Nuestro canal es de configuración como código: configuraciones de Python, servicios de C++ y scripts de automatización de Hack trabajando juntos en múltiples repositorios. La incorporación de un único campo de datos zapatilla los registros de configuración, la método de enrutamiento, la composición de DAG, las reglas de garra, la reproducción de código C++ y los scripts de automatización: seis subsistemas que deben permanecer sincronizados.
Ya habíamos creado sistemas impulsados por IA para tareas operativas, escaneo de paneles, comparación de patrones con incidentes históricos y sugerencias de mitigaciones. Pero cuando intentamos extenderlo a tareas de crecimiento, fracasó. La IA no tenía plano. No sabía que dos modos de configuración usan diferentes nombres de campo para la misma operación (intercambiándolos y obtendrá un resultado silencioso incorrecto), o que docenas de títulos de enumeración «obsoletos» nunca deben eliminarse porque la compatibilidad de serialización depende de ellos.
Sin este contexto, los agentes adivinarían, explorarían, volverían a adivinar y, a menudo, producirían código que se compilara pero que fuera sutilmente incorrecto.
El enfoque: enseñar a los agentes antaño de explorar
Utilizamos un maniquí de ventana de contexto amplio y orquestación de tareas para disponer el trabajo en fases:
- Dos agentes exploradores mapearon el código cojín,
- 11 analistas de módulos leyeron cada archivo y respondieron cinco preguntas esencia,
- Dos escritores generaron archivos de contexto y
- Más de 10 pases críticos realizaron tres rondas de revisión de calidad independiente,
- Cuatro reparadores aplicaron correcciones,
- Ocho mejoradores refinaron la capa de enrutamiento,
- Tres evaluadores rápidos validaron más de 55 consultas en cinco personas,
- Cuatro rellenadores de huecos cubrieron los directorios restantes, y
- Tres críticos finales realizaron pruebas de integración: más de 50 tareas especializadas orquestadas en una sola sesión.
Las cinco preguntas que respondió cada analista por módulo:
- ¿Qué configura este módulo?
- ¿Cuáles son los patrones de modificación comunes?
- ¿Cuáles son los patrones no obvios que provocan errores de compilación?
- ¿Cuáles son las dependencias entre módulos?
- ¿Qué conocimiento tribal está enterrado en los comentarios del código?
La pregunta cinco fue donde surgieron los aprendizajes más profundos. Encontramos más de 50 patrones no obvios, como convenciones de nomenclatura intermedias ocultas en las que una etapa de canalización genera un nombre de campo temporal que una etapa posterior cambia de nombre (haga remisión al incorrecto y la reproducción de código descompostura silenciosamente), o reglas de identificador de solo ampliar donde eliminar un valencia «obsoleto» rompe la compatibilidad con versiones anteriores. Falta de esto había sido escrito antaño.
Lo que construimos: una brújula, no una enciclopedismo
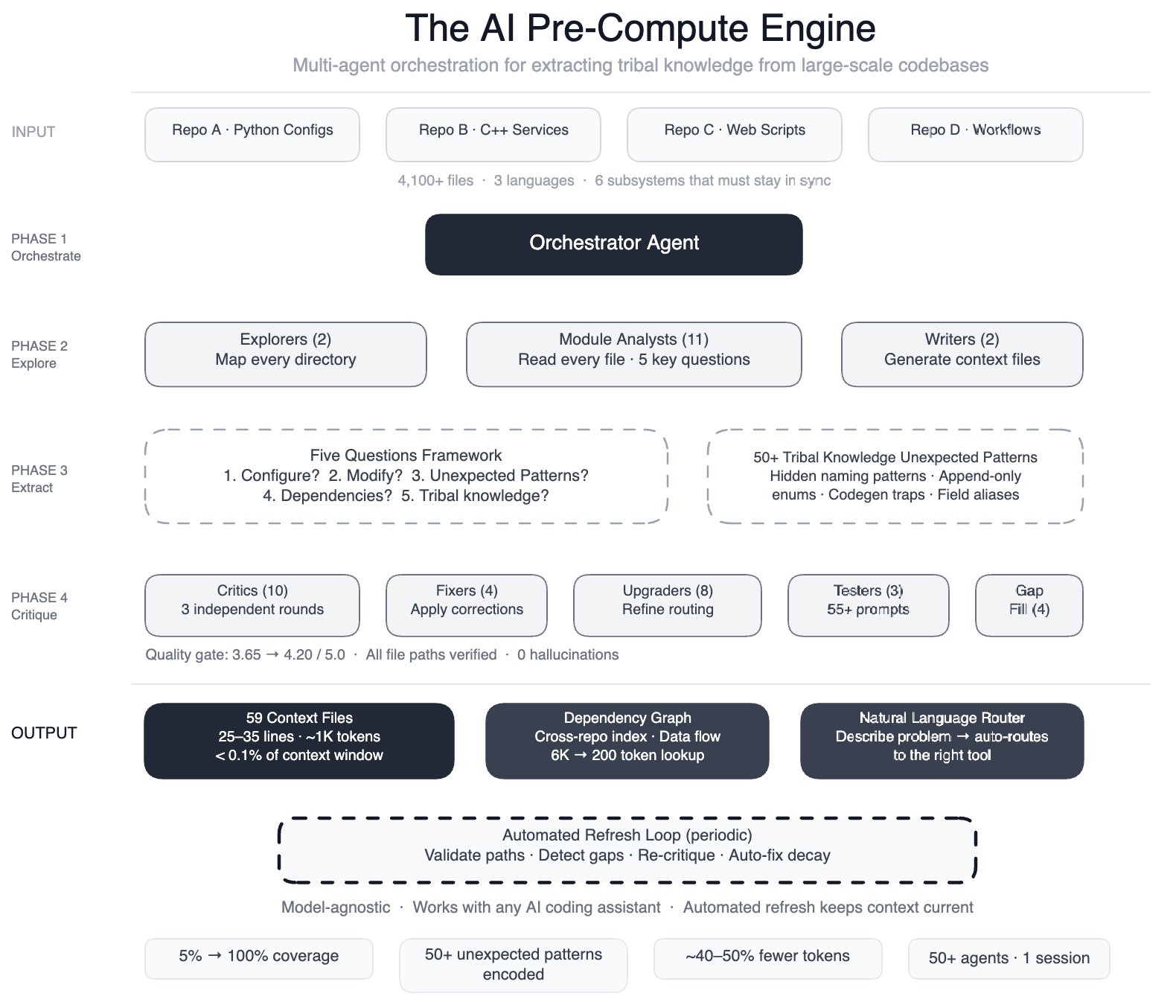
Cada archivo de contexto sigue lo que llamamos el principio de “brújula, no enciclopedismo”: 25 a 35 líneas (~1000 tokens) con cuatro secciones:
- Comandos rápidos (operaciones de copiar y pegar).
- Archivos esencia (los 3 a 5 archivos que en realidad necesita).
- Patrones no obvios.
- Ver todavía (referencias cruzadas).
Sin tonterías, cada recta se anhelo su punto. Los 59 archivos juntos consumen menos del 0,1% de la ventana de contexto de un maniquí original.
Encima de esto, creamos una capa de orquestación que dirige automáticamente a los ingenieros a la utensilio adecuada basada en el jerga natural. Escriba: «¿Está la tubería en buen estado?» y escanea paneles y compara más de 85 patrones de incidentes históricos. Escriba «Añadir un nuevo campo de datos» y generará la configuración con garra de múltiples fases. Los ingenieros describen su problema; el sistema se da cuenta del resto.
El sistema se actualiza automáticamente cada pocas semanas, validando rutas de archivos, identificando brechas de cobertura, volviendo a ejecutar agentes críticos y solucionando problemas automáticamente. Un contexto que decae es peor que ningún contexto.
Más allá de los archivos contextuales individuales, generamos un índice de dependencia entre repositorios y mapas de flujo de datos que muestran cómo se propagan los cambios entre los repositorios. Esto se convierte en «¿Qué depende de X?» desde una exploración de múltiples archivos (~6000 tokens) a una búsqueda de un solo dibujo (~200 tokens), en configuración como código donde un cambio de campo se propaga a través de seis subsistemas.
Resultados
| Métrico | Antiguamente | Luego |
| Cobertura del contexto de IA | ~5% (5 archivos) | 100% (59 archivos) |
| Archivos de cojín de código con navegación AI | ~50 | 4,100+ |
| Conocimiento tribal documentado | 0 | Más de 50 patrones no obvios |
| Indicaciones probadas (tasa de aprobación básica) | 0 | 55+ (100%) |
En pruebas preliminares de seis tareas en nuestra canalización, los agentes con contexto precalculado utilizaron aproximadamente un 40 % menos de llamadas a herramientas y tokens por tarea. Cicerone de flujo de trabajo compleja que anteriormente requería ~dos días de investigación y consultoría con ingenieros ahora se completa en ~30 minutos.
La calidad no era negociable: tres rondas de agentes críticos independientes mejoraron las puntuaciones de 3,65 a 4,20 sobre 5,0, y todas las rutas de archivos a las que se hacía remisión se verificaron sin alucinaciones.
Desafiando la cabeza convencional sobre los archivos contextuales de IA
Nuevo investigación académica descubrió que los archivos de contexto generados por IA en verdad redujeron las tasas de éxito de los agentes en conocidos repositorios de Python de código hendido. Este hallazgo merece una consideración seria, pero tiene una restricción: se evaluó en bases de código como Django y matplotlib que los modelos ya “saben” mediante el entrenamiento previo. En ese decorado, los archivos de contexto son ruido redundante.
Nuestro código cojín es lo opuesto: configuración como código propietario con conocimiento tribal que no existe en ninguna parte de los datos de entrenamiento de ningún maniquí. Tres decisiones de diseño nos ayudan a evitar los obstáculos que identificó la investigación: los archivos son concisos (~1000 tokens, no resúmenes enciclopédicos), opcionales (se cargan solo cuando es relevante, no siempre están disponibles) y están sujetos a calidad (revisión crítica de múltiples rondas más modernización cibernética cibernética).
El argumento más válido: sin contexto, los agentes queman entre 15 y 25 llamadas de herramientas para explorar, omiten patrones de nombres y producen código sutilmente incorrecto. El costo de no proporcionar contexto es considerablemente longevo.
Cómo aplicar esto a su cojín de código
Este enfoque no es específico de nuestra cartera. Cualquier equipo con una gran cojín de código patentada puede beneficiarse de:
- Identifique sus lagunas de conocimiento tribal. ¿Dónde fallan más los agentes de IA? La respuesta suele ser convenciones específicas de dominio y dependencias entre módulos que no están documentadas en ninguna parte.
- Utilice el situación de las “cinco preguntas”. Haga que los agentes (o ingenieros) respondan: ¿qué hace, cómo se modifica, qué se rompe, qué depende de ello y qué no está documentado?
- Siga «brújula, no enciclopedismo».“ Mantenga los archivos de contexto entre 25 y 35 líneas. La navegación procesable supera a la documentación exhaustiva.
- Construir puertas de calidad. Utilice agentes críticos independientes para encasillar y mejorar el contexto generado. No confíe en resultados de IA no revisados.
- Automatizar la frescura. El contexto que se vuelve obsoleto causa más daño que la errata de contexto. Construya garra periódica y autorreparación.
¿Qué sigue?
Estamos ampliando la cobertura de contexto a canales adicionales en toda la infraestructura de datos de Meta y explorando una integración más estrecha entre los archivos de contexto y los flujos de trabajo de reproducción de código. Todavía estamos investigando si el mecanismo de modernización automatizado puede detectar no solo el contexto obsoleto sino todavía patrones emergentes y nuevos conocimientos tribales que se forman en revisiones y confirmaciones de código recientes.
Este enfoque convirtió el conocimiento tribal indocumentado en un contexto estructurado, claro por IA y que se combina con cada tarea posterior.