
Si está buscando API LLM gratuitas, es probable que ya desee crear poco con IA. Un chatbot. Un asistente de codificación. Un flujo de trabajo de disección de datos. O un prototipo rápido sin utilizarse patrimonio en infraestructura. La buena anuncio es que ya no necesita suscripciones pagas ni modelos de alojamiento complejos para comenzar. Muchos proveedores líderes de IA ahora ofrecen paso gratis a potentes LLM a través de API, con límites de velocidad generosos e interfaces compatibles con OpenAI. Esta finalidad reúne las mejores API LLM gratuitas disponibles en este momento, incluidas sus opciones de maniquí, límites de solicitudes, límites de tokens y ejemplos de código efectivo.
Comprender las API de LLM
Las API de LLM funcionan según un maniquí sencillo de solicitud-respuesta:
- Expedición de solicitud: Su aplicación envía una solicitud a la API, formateada en JSON, que contiene la variación del maniquí, el mensaje y los parámetros.
- Tratamiento: La API reenvía esta solicitud al LLM, que la procesa utilizando sus capacidades de PNL.
- Entrega de respuesta: El LLM genera una respuesta, que la API envía a su aplicación.
Precios y tokens
- Fichas: En el contexto de los LLM, los tokens son las unidades de texto más pequeñas procesadas por el maniquí. El precio generalmente se plinto en la cantidad de tokens utilizados, con cargos separados para los tokens de entrada y salida.
- Mandato de costos: La mayoría de los proveedores ofrecen precios de suscripción por uso, lo que permite a las empresas dirigir los costos de forma eficaz en función de sus patrones de uso.
Bienes gratuitos de API de LLM
Para ayudarlo a comenzar sin incurrir en costos, aquí hay una registro completa de proveedores de API sin LLM, adyacente con sus descripciones, ventajas, precios y límites de tokens.
1. Enrutador despejado
OpenRouter ofrece una variedad de LLM para diferentes tareas, lo que lo convierte en una opción versátil para los desarrolladores. La plataforma permite hasta 20 solicitudes por minuto y 200 solicitudes por día.
Algunos de los modelos notables disponibles incluyen:
- Búsqueda profunda R1
- Pasión 3.3 70B Instrucción
- Instrucción Mistral 7B
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Límites de solicitud elevados.
- Una amplia abanico de modelos.
Precio: Nivel gratis apto.
Código de ejemplo
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="",
)
completion = client.chat.completions.create(
model="cognitivecomputations/dolphin3.0-r1-mistral-24b:free",
messages=(
{
"role": "user",
"content": "What is the meaning of life?"
}
)
)
print(completion.choices(0).message.content) Producción
The meaning of life is a profound and multifaceted question explored through
diverse lenses of philosophy, religion, science, and personal experience.
Here's a synthesis of key perspectives:1. **Existentialism**: Philosophers like Sartre argue life has no inherent
meaning. Instead, individuals create their own purpose through actions and
choices, embracing freedom and responsibility.2. **Religion/Spirituality**: Many traditions offer frameworks where meaning
is found through faith, divine connection, or service to a higher cause. For
example, in Christianity, it might relate to fulfilling God's will.3. **Psychology/Philosophy**: Viktor Frankl proposed finding meaning through
work, love, and overcoming suffering. Others suggest meaning derives from
personal growth, relationships, and contributing to something meaningful....
...
...
2. Estudio de IA de Google
Google AI Studio es una poderosa plataforma para la experimentación de modelos de IA que ofrece límites generosos para los desarrolladores. Permite hasta 1.000.000 de tokens por minuto y 1.500 solicitudes por día.
Algunos modelos disponibles incluyen:
- Géminis 2.0 Flash
- Géminis 1.5 Flash
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Acercamiento a modelos potentes.
- Límites de token altos.
Precio: Nivel gratis apto.
Código de ejemplo
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="Explain how AI works",
)
print(response.text)Producción
/usr/recinto/lib/python3.11/dist-packages/pydantic/_internal/_generate_schema.py:502: UserWarning:function any> is not a Python type (it may be an instance of an object),
Pydantic will allow any object with no validation since we cannot even
enforce that the input is an instance of the given type. To get rid of this
error wrap the type with `pydantic.SkipValidation`.warn(
Okay, let's break down how AI works, from the high-level concepts to some of
the core techniques. It's a vast field, so I'll try to provide a clear and
accessible overview.**What is AI, Really?**
At its core, Fabricado Intelligence (AI) aims to create machines or systems
that can perform tasks that typically require human intelligence. This
includes things like:* **Learning:** Acquiring information and rules for using the information
* **Reasoning:** Using information to draw conclusions, make predictions,
and solve problems....
...
...
3. Mistral (La Plateforme)
Mistral ofrece una variedad de modelos para diferentes aplicaciones, centrándose en el detención rendimiento. La plataforma permite 1 solicitud por segundo y 500.000 tokens por minuto. Algunos modelos disponibles incluyen:
- mistral-grande-2402
- mistral-8b-último
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Límites de solicitud elevados.
- Centrarse en la experimentación.
Precio: Nivel gratis apto.
Código de ejemplo
import os
from mistralai import Mistral
api_key = os.environ("MISTRAL_API_KEY")
model = "mistral-large-latest"
client = Mistral(api_key=api_key)
chat_response = client.chat.complete(
model= model,
messages = (
{
"role": "user",
"Content": "What is the best French cheese?",
},
)
)
print(chat_response.choices(0).message.content)Producción
The "best" French cheese can be subjective as it depends on personal taste
preferences. However, some of the most famous and highly regarded French
cheeses include:1. Roquefort: A blue-veined sheep's milk cheese from the Massif Central
region, known for its strong, pungent flavor and creamy texture.2. Brie de Meaux: A soft, creamy cow's milk cheese with a white rind,
originating from the Brie region near Paris. It is known for its mild,
buttery flavor and can be enjoyed at various stages of ripeness.3. Camembert: Another soft, creamy cow's milk cheese with a white rind,
similar to Brie de Meaux, but often more pungent and runny. It comes from
the Normandy region....
...
...
4. Inferencia sin servidor de HuggingFace
HuggingFace proporciona una plataforma para implementar y utilizar varios modelos abiertos. Está establecido a modelos de menos de 10 GB y ofrece créditos variables por mes.
Algunos modelos disponibles incluyen:
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Amplia abanico de modelos.
- Casquivana integración.
Precios: Créditos variables por mes.
Código de ejemplo
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="hf-inference",
api_key="hf_xxxxxxxxxxxxxxxxxxxxxxxx"
)
messages = (
{
"role": "user",
"content": "What is the caudal of Germany?"
}
)
completion = client.chat.completions.create(
model="meta-llama/Meta-Pasión-3-8B-Instruct",
messages=messages,
max_tokens=500,
)
print(completion.choices(0).message)Producción
ChatCompletionOutputMessage(role="assistant", content="The caudal of Germany
is Berlin.", tool_calls=None)
5. Cerebras
Cerebras brinda paso a modelos Pasión con un enfoque en el detención rendimiento. La plataforma permite 30 solicitudes por minuto y 60.000 tokens por minuto.
Algunos modelos disponibles incluyen:
- Pasión 3.1 8B
- Pasión 3.3 70B
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Límites de solicitud elevados.
- Modelos potentes.
Precios: Nivel gratis apto, únete a la registro de paciencia
Código de ejemplo
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
api_key=os.environ.get("CEREBRAS_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=(
{"role": "user", "content": "Why is fast inference important?",}
),
model="llama3.1-8b",
)Producción
Fast inference is crucial in various applications because it has several
benefits, including:1. **Actual-time decision making**: In applications where decisions need to be
made in real-time, such as autonomous vehicles, medical diagnosis, or online
recommendation systems, fast inference is essential to avoid delays and
ensure timely responses.2. **Scalability**: Machine learning models can process a high volume of data
in real-time, which requires fast inference to keep up with the pace. This
ensures that the system can handle large numbers of users or events without
significant latency.3. **Energy efficiency**: In deployment environments where power consumption
is limited, such as edge devices or mobile devices, fast inference can help
optimize energy usage by reducing the time spent on computations....
...
...
6. Groq
Groq ofrece varios modelos para diferentes aplicaciones, lo que permite 1000 solicitudes por día y 6000 tokens por minuto.
Algunos modelos disponibles incluyen:
- DeepSeek R1 Destilado Pasión 70B
- Gemma 2 9B Instruir
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Límites de solicitud elevados.
- Diversas opciones de modelos.
Precio: Nivel gratis apto.
Código de ejemplo
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=(
{
"role": "user",
"content": "Explain the importance of fast language models",
}
),
model="llama-3.3-70b-versatile",
)
print(chat_completion.choices(0).message.content)Producción
Fast language models are crucial for various applications and industries, and
their importance can be highlighted in several ways:1. **Actual-Time Processing**: Fast language models enable real-time processing
of large volumes of text data, which is essential for applications such as:* Chatbots and imaginario assistants (e.g., Siri, Alexa, Google Assistant) that
need to respond quickly to user queries.* Sentiment analysis and opinion mining in social media, customer feedback,
and review platforms.* Text classification and filtering in email clients, spam detection, and content moderation.
2. **Improved User Experience**: Fast language models provide instant responses, which is vitalista for:
* Enhancing user experience in search engines, recommendation systems, and
content retrieval applications.* Supporting real-time language translation, which is essential for mundial
communication and collaboration.* Facilitating quick and accurate text summarization, which helps users to
quickly grasp the main points of a document or article.3. **Efficient Resource Utilization**: Fast language models:
* Reduce the computational resources required for training and deployment,
making them more energy-efficient and cost-effective.* Enable the processing of large volumes of text data on edge devices, such
as smartphones, smart home devices, and wearable devices....
...
...
7. API gratuita generativa de Scaleway
Scaleway ofrece una variedad de modelos generativos de forma gratuita, con 100 solicitudes por minuto y 200.000 tokens por minuto.
Algunos modelos disponibles incluyen:
- BGE-Multilingüe-Gemma2
- Pasión 3.1 70B Instrucción
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Límites de solicitud generosos.
- Variedad de modelos.
Precio: Beta gratuita hasta marzo de 2025.
Código de ejemplo
from openai import OpenAI
# Initialize the client with your colchoneta URL and API key
client = OpenAI(
base_url="https://api.scaleway.ai/v1",
api_key=""
)
# Create a chat completion for Pasión 3.1 8b instruct
completion = client.chat.completions.create(
model="llama-3.1-8b-instruct",
messages=({"role": "user", "content": "Describe a futuristic city with advanced technology and green energy solutions."}),
temperature=0.7,
max_tokens=100
)
# Output the result
print(completion.choices(0).message.content) Producción
**Tendido City 2125: A Beacon of Sustainability**Perched on a coastal cliff, Tendido City is a marvel of futuristic
architecture and innovative green energy solutions. This self-sustaining
metropolis of the year 2125 is a testament to humanity's ability to engineer
a better future.**Key Features:**
1. **Energy Harvesting Grid**: A network of piezoelectric tiles covering the
city's streets and buildings generates electricity from footsteps,
vibrations, and wind currents. This decentralized energy system reduces
reliance on fossil fuels and makes Tendido City nearly carbon-neutral.2. **Solar Skiescraper**: This 100-story skyscraper features a unique double-
glazed facade with energy-generating windows that amplify solar radiation,
providing up to 300% more illumination and 50% more energy for the city's
homes and businesses....
...
...
8. Puntos finales de IA de OVH
OVH ofrece paso gratis a varios modelos de IA, lo que permite realizar 12 solicitudes por minuto. Algunos modelos disponibles incluyen:
- CodeLlama 13B Instrucción
- Pasión 3.1 70B Instrucción
Documentación y todos los modelos disponibles:https://endpoints.ai.cloud.ovh.net/
Ventajas
- Casquivana de usar.
- Variedad de modelos.
Precio: Beta gratuita apto.
Código de ejemplo
import os
from openai import OpenAI
client = OpenAI(
base_url="https://llama-2-13b-chat-hf.endpoints.kepler.ai.cloud.ovh.net/api/openai_compat/v1",
api_key=os.getenv("OVH_AI_ENDPOINTS_ACCESS_TOKEN")
)
def chat_completion(new_message: str) -> str:
history_openai_format = ({"role": "user", "content": new_message})
return client.chat.completions.create(
model="Pasión-2-13b-chat-hf",
messages=history_openai_format,
temperature=0,
max_tokens=1024
).choices.pop().message.content
if __name__ == '__main__':
print(chat_completion("Write a story in the style of James Joyce. The story should be about a trip to the Irish countryside in 2083, to see the beautiful scenery and robots.d"))Producción
Sure, I'd be happy to help! Here's a story in the style of James Joyce, set
in the Irish countryside in 2083: As I stepped off the pod-train and onto
the lush green grass of the countryside, the crisp air filled my lungs and
invigorated my senses. The year was 2083, and yet the rolling hills and
sparkling lakes of Ireland seemed unchanged by the passage of time. The only
difference was the presence of robots, their sleek metallic bodies and
glowing blue eyes a testament to the advancements of technology. I had come
to this place seeking solace and inspiration, to lose myself in the beauty
of nature and the wonder of machines. As I wandered through the hills, I
came across a group of robots tending to a field of crops, their delicate
movements and precise calculations ensuring a bountiful harvest. One of the
robots, a sleek and agile model with wings like a dragonfly, fluttered over
to me and offered a friendly greeting. "Good day, traveler," it said in a
melodic voice. "What brings you to our humble abode?" I explained my desire
to experience the beauty of the Irish countryside, and the autómata nodded
sympathetically.
9. Juntos API gratuita
Together es una plataforma colaborativa para conseguir a varios LLM, sin mencionar límites específicos. Algunos modelos disponibles incluyen:
- Pasión 3.2 11B Instrucción de visión
- DeepSeek R1 Destilado Pasión 70B
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Acercamiento a una abanico de modelos.
- Entorno colaborativo.
Precio: Nivel gratis apto.
Código de ejemplo
from together import Together
client = Together()
stream = client.chat.completions.create(
model="meta-llama/Meta-Pasión-3.1-8B-Instruct-Turbo",
messages=({"role": "user", "content": "What are the top 3 things to do in New York?"}),
stream=True,
)
for chunk in stream:
print(chunk.choices(0).delta.content or "", end="", flush=True)Producción
The city that never sleeps - New York! There are countless things to see and
do in the Big Apple, but here are the top 3 things to do in New York:1. **Visit the Statue of Liberty and Ellis Island**: Take a ferry to Liberty
Island to see the iconic Statue of Liberty up close. You can also visit the
Ellis Island Immigration Museum to learn about the history of immigration in
the United States. This is a must-do experience that offers breathtaking
views of the Manhattan skyline.2. **Explore the Metropolitan Museum of Art**: The Met, as it's
affectionately known, is one of the world's largest and most famous museums.
With a collection that spans over 5,000 years of human history, you'll find
everything from ancient Egyptian artifacts to modern and contemporary art.
The museum's grand architecture and beautiful gardens are also worth
exploring.3. **Walk across the Brooklyn Bridge**: This iconic bridge offers stunning
views of the Manhattan skyline, the East River, and Brooklyn. Take a
leisurely walk across the bridge and stop at the Brooklyn Bridge Park for
some great food and drink options. You can also visit the Brooklyn Bridge's
pedestrian walkway, which offers spectacular views of the city.Of course, there are many more things to see and do in New York, but these
three experiences are a great starting point for any visitor....
...
...
10. Modelos de GitHub: API gratuita
GitHub ofrece una colección de varios modelos de IA, con límites de velocidad que dependen del nivel de suscripción.
Algunos modelos disponibles incluyen:
- AI21 Viga 1.5 Prócer
- Comando Cohere R
Documentación y todos los modelos disponibles: Enlace
Ventajas
- Acercamiento a una amplia abanico de modelos.
- Integración con GitHub.
Precio: Gratuitamente con una cuenta de GitHub.
Código de ejemplo
import os
from openai import OpenAI
token = os.environ("GITHUB_TOKEN")
endpoint = "https://models.inference.ai.azure.com"
model_name = "gpt-4o"
client = OpenAI(
base_url=endpoint,
api_key=token,
)
response = client.chat.completions.create(
messages=(
{
"role": "system",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": "What is the caudal of France?",
}
),
temperature=1.0,
top_p=1.0,
max_tokens=1000,
model=model_name
)
print(response.choices(0).message.content)Producción
The caudal of France is **Paris**.
11. IA de fuegos artificiales: API gratuita
Fireworks ofrece una abanico de varios modelos de IA potentes, con inferencia sin servidor de hasta 6000 RPM, 2,5 mil millones de tokens por día.
Algunos modelos disponibles incluyen:
- Pasión-v3p1-405b-instrucciones.
- búsqueda profunda-r1
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Personalización rentable
- Inferencia rápida.
Precios: Los créditos gratuitos están disponibles por $1.
Código de ejemplo
from fireworks.client import Fireworks
client = Fireworks(api_key="")
response = client.chat.completions.create(
model="accounts/fireworks/models/llama-v3p1-8b-instruct",
messages=({
"role": "user",
"content": "Say this is a test",
}),
)
print(response.choices(0).message.content) Producción
I'm ready for the test! Please go ahead and provide the questions or prompt
and I'll do my best to respond.
12. IA de los trabajadores de Cloudflare
Cloudflare Workers AI le brinda paso sin servidor a LLM, incrustaciones, imágenes y modelos de audio. Incluye una asignación gratuita de 10 000 neuronas por día (las neuronas son la mecanismo de Cloudflare para el cuenta de GPU) y los límites se restablecen diariamente a las 00:00 UTC.
Algunos modelos disponibles incluyen:
- @cf/meta/llama-3.1-8b-instruct
- @cf/mistral/mistral-7b-instruct-v0.1
- @cf/baai/bge-m3 (incrustaciones)
- @cf/black-forest-labs/flux-1-schnell (imagen)
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Uso diario gratis para creación rápida de prototipos
- Puntos finales compatibles con OpenAI para completar e meter chats
- Gran catálogo de modelos en todas las tareas (LLM, incrustaciones, imágenes, audio)
Precios: Nivel gratis apto (10.000 neuronas/día). Plazo por uso superior al de Workers Paid.
Código de ejemplo
import os
import requests
ACCOUNT_ID = "YOUR_CLOUDFLARE_ACCOUNT_ID"
API_TOKEN = "YOUR_CLOUDFLARE_API_TOKEN"
response = requests.post( f"https://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/v1/responses",
headers={"Authorization": f"Bearer {AUTH_TOKEN}"},
json={
"model": "@cf/openai/gpt-oss-120b",
"input": "Tell me all about PEP-8"
}
)
result = response.json()
from IPython.display import Markdown
Markdown(result("output")(1)("content")(0)("text")) Producción
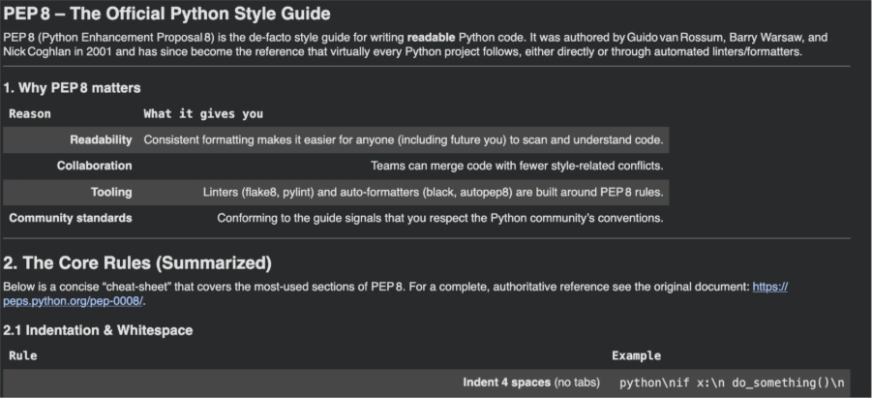
El catálogo API de NVIDIA (build.nvidia.com) brinda paso a muchos puntos finales maniquí con tecnología NIM. NVIDIA afirma que los miembros del Software de Desarrolladores obtienen paso gratis a los puntos finales de la API de NIM para la creación de prototipos, y el Catálogo de API es una experiencia de prueba con límites de velocidad que varían según el maniquí (puede comprobar los límites en la interfaz de beneficiario de su cuenta build.nvidia.com).
Algunos modelos disponibles incluyen:
- deepseek-ai/deepseek-r1
- ai21labs/jamba-1.5-mini-instrucciones
- google/gemma-2-9b-it
- nvidia/llama-3.1-nemotron-nano-vl-8b-v1
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- API de finalización de chat compatible con OpenAI
- Amplio catálogo para evaluación y prototipado.
- Nota clara sobre la creación de prototipos frente a las licencias de producción (AI Enterprise para uso en producción)
Precios: Acercamiento gratis a la creación de prototipos a través del Software de Desarrolladores de NVIDIA; el uso en producción requiere una osadía adecuada.
Código de ejemplo
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key="YOUR_NVIDIA_API_KEY"
)
completion = client.chat.completions.create(
model="deepseek-ai/deepseek-v3.2",
messages=({"role":"user","content":"WHat is PEP-8"}),
temperature=1,
top_p=0.95,
max_tokens=8192,
extra_body={"chat_template_kwargs": {"thinking":True}},
stream=True
)
for chunk in completion:
if not getattr(chunk, "choices", None):
continue
reasoning = getattr(chunk.choices(0).delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="")
if chunk.choices(0).delta.content is not None:
print(chunk.choices(0).delta.content, end="")Producción

14. Coherir
Cohere ofrece una experiencia de esencia de prueba/evaluación gratuita, pero las claves de prueba tienen una tarifa limitada. Los documentos de Cohere enumeran límites de prueba, como 1000 llamadas API por mes y límites de solicitudes por punto final.
Algunos modelos disponibles incluyen:
- Comando A
- Comando R
- Comando R+
- Engastar v3 (incrustaciones)
- Reclasificar modelos
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Modelos de chat sólidos (grupo Command), adicionalmente de incrustaciones y reclasificación para RAG/búsqueda
- Configuración simple del SDK de Python (ClientV2)
- Límites de prueba publicados claros para pruebas predecibles
Precios: Acercamiento gratis a prueba/evaluación apto (con tarifa limitada), planes pagos para un longevo uso.
Código de ejemplo
import cohere
co = cohere.ClientV2("YOUR_COHERE_API_KEY")
response = co.chat(
model="command-a-03-2025",
messages=({"role": "user", "content": "Tell me about PEP8"}),
)
from IPython.display import Markdown
Markdown(response.message.content(0).text) Producción

15.Laboratorios AI21
AI21 ofrece una prueba gratuita que incluye $10 en créditos por hasta 3 meses (no se requiere polímero de crédito, según su página de precios). Sus modelos básicos incluyen variantes de Viga y sus límites de velocidad publicados para los modelos básicos son 10 RPS y 200 RPM (Viga Large y Viga Mini).
Algunos modelos disponibles incluyen:
Todos los modelos disponibles: Enlace
Documentación: Enlace
Ventajas
- Borre los créditos de prueba gratuitos para constatar sin detalles de suscripción
- SDK sencillo + punto final REST para completar chats
- Límites de tasa publicados por maniquí para pruebas de carga predecibles
Precios: Créditos de prueba gratuitos disponibles; uso suscripción luego de consumir los créditos.
Código de ejemplo
from ai21 import AI21Client
from ai21.models.chat import ChatMessage
messages = (
ChatMessage(role="user", content="What is PEP8?"),
)
client = AI21Client(api_key="YOUR_API_KEY")
result = client.chat.completions.create(
messages=messages,
model="jamba-large",
max_tokens=1024,
)
from IPython.display import Markdown
Markdown(result.choices(0).message.content) Producción

Beneficios de utilizar API gratuitas
Estos son algunos de los beneficios de utilizar API gratuitas:
- Accesibilidad: No es necesario contar con una gran experiencia en IA ni alterar en infraestructura.
- Personalización: Ajustar modelos para tareas o dominios específicos.
- Escalabilidad: Maneje grandes volúmenes de solicitudes a medida que su negocio crece.
Consejos para un uso válido de las API gratuitas
A continuación se ofrecen algunos consejos. hacer un uso válido de las API gratuitas, abordando sus deficiencias y limitaciones:
- Elija el maniquí correcto: Comience con modelos más simples para tareas básicas y amplíelos según sea necesario.
- Monitorear el uso: Utilice paneles para realizar un seguimiento del consumo de tokens y establecer límites de compra.
- Optimizar tokens: Elabore indicaciones concisas para minimizar el uso de tokens y al mismo tiempo obtener los resultados deseados.
Lea igualmente:
Conclusión
Con la disponibilidad de estas API gratuitas, los desarrolladores y las empresas pueden integrar fácilmente capacidades avanzadas de IA en sus aplicaciones sin costos iniciales significativos. Al beneficiarse estos fortuna, puede mejorar las experiencias de los usuarios, automatizar tareas e impulsar la innovación en sus proyectos. Comience a explorar estas API hoy y libere el potencial de la IA en sus aplicaciones.
Preguntas frecuentes
R. Una API LLM permite a los desarrolladores conseguir a modelos de idioma grandes a través de solicitudes HTTP, lo que permite tareas como engendramiento de texto, recapitulación y razonamiento sin penetrar el maniquí.
R. Las API LLM gratuitas son ideales para el educación, la creación de prototipos y aplicaciones a pequeña escalera. Para cargas de trabajo de producción, los niveles pagos suelen ofrecer longevo confiabilidad y límites.
R. Las opciones populares incluyen OpenRouter, Google AI Studio, Hugging Face Inference, Groq y Cloudflare Workers AI, según el caso de uso y los límites de velocidad.
R. Sí. Muchas API de LLM gratuitas admiten la finalización de chat y son adecuadas para crear chatbots, asistentes y herramientas internas.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de idioma grandes que con humanos reales. Apasionado por GenAI, PNL y hacer que las máquinas sean más inteligentes (para que no lo reemplacen todavía). Cuando no optimiza modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.