
Los investigadores de DeepSeek están intentando resolver un problema preciso en el entrenamiento de modelos de verbo grandes. Las conexiones residuales hicieron que las redes muy profundas fueran entrenables, las hiperconexiones ampliaron ese flujo residual y el entrenamiento se volvió inestable a escalera. El nuevo método mHC, Manifold Constrained Hyper Connections, mantiene la topología más rica de las hiperconexiones pero bloquea el comportamiento de mezcla en un colector admisiblemente definido para que las señales permanezcan numéricamente estables en pilas muy profundas.
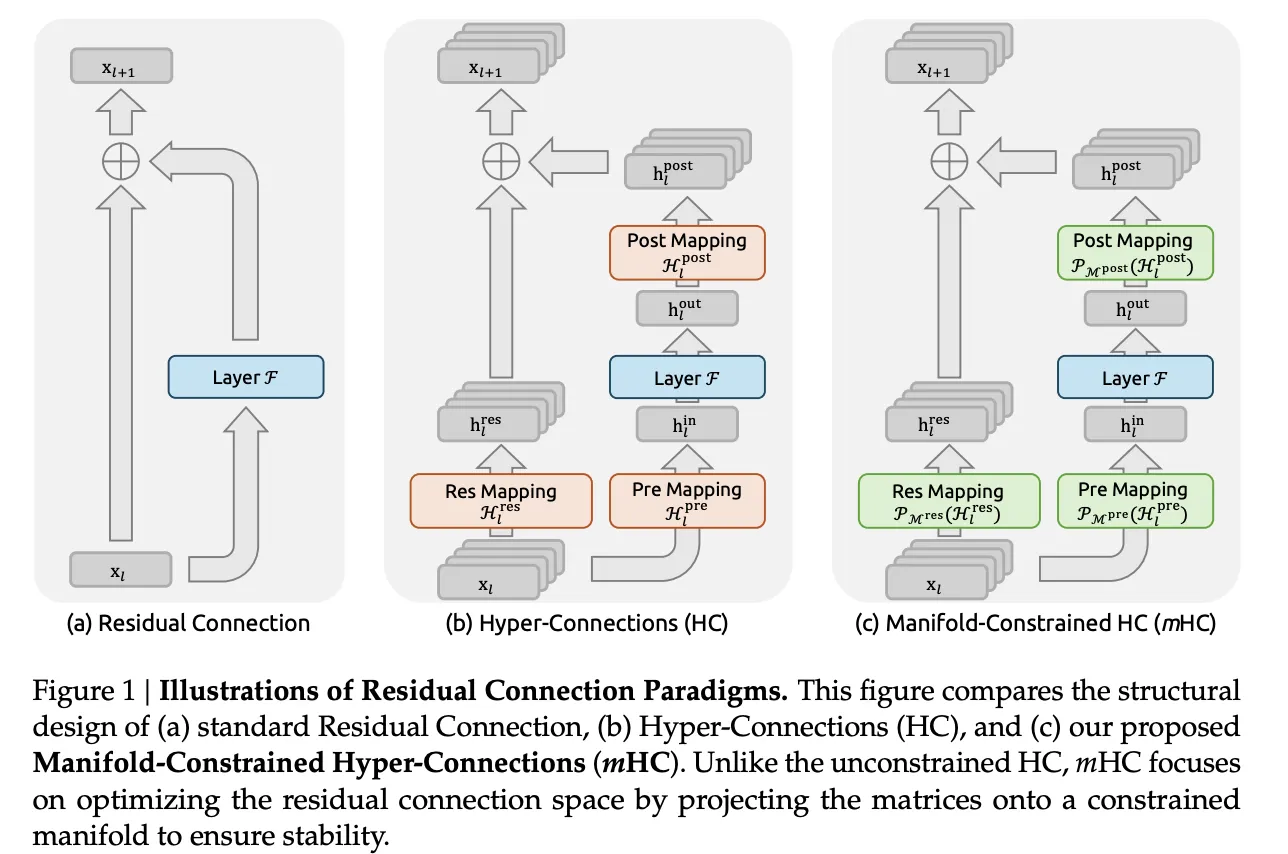
De conexiones residuales a hiperconexiones
Las conexiones residuales habitual, como en ResNets y Transformers, propagan las activaciones con xl+1=xyo+F(xyo,wyo)
La ruta de identidad conserva la magnitud y mantiene los gradientes utilizables incluso cuando se apilan muchas capas.
Hyper Connections generaliza esta estructura. En oportunidad de un único vector residual de tamaño C, el maniquí mantiene un buffer de n flujos 𝑥𝑙∈𝑅𝑛×𝐶. Tres asignaciones aprendidas controlan cómo cada capa lee y escribe este búfer:
- hyopre selecciona una mezcla de secuencias como entrada de capa
- F es la subcapa habitual de atención o feedback.
- hyocorreo escribe los resultados nuevamente en el búfer de flujo n
- hyores∈Rn×n mezcla corrientes entre capas
La modernización tiene la forma
clavel+1=Hyoresclaveyo+Hyocorreo⊤F(H)yopreclaveyo,Wyo)
Con n establecido en 4, este diseño aumenta la viveza sin un gran aumento en el costo del punto flotante, razón por la cual las hiperconexiones mejoran el rendimiento posterior en los modelos de verbo.
Por qué las hiperconexiones se vuelven inestables
El problema aparece cuando se observa el producto de mezcladores residuales en muchas capas. En un maniquí de mezcla de 27B de expertos, DeepSeek estudia el mapeo compuesto
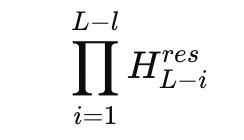
y define una magnitud de rendimiento Amax basada en las sumas máximas de filas y columnas. Esta métrica mide la amplificación en el peor de los casos en las rutas de señal alrededor de delante y alrededor de antes. En el maniquí de hiperconexión, esta rendimiento alcanza picos aproximadamente de 3000, allá del valencia ideal 1 que se prórroga de una ruta residual estable.
Esto significa que pequeñas desviaciones por capa se combinan en factores de amplificación muy grandes en toda la profundidad. Los registros de entrenamiento muestran picos de pérdida y normas de gradiente inestables en relación con un maniquí residual de remisión. Al mismo tiempo, abastecer un búfer de flujo múltiple aumenta el tráfico de memoria para cada token, lo que hace que el escalado ingenuo de hiperconexiones no sea atractivo para la producción de modelos de verbo grandes.
Hiperconexiones restringidas por colector
mHC mantiene la idea residual de múltiples corrientes pero restringe la parte peligrosa. La matriz de mezcla residual Hyores ya no vive en el espacio completo n por n. En cambio, se proyecta sobre la variedad de matrices doblemente estocásticas, igualmente citación politopo de Birkhoff. En ese conjunto, todas las entradas no son negativas y cada fila y cada columna suman 1.
El equipo de DeepSeek aplica esta restricción con el operación clásico de Sinkhorn Knopp de 1967, que alterna normalizaciones de filas y columnas para aproximarse a una matriz doblemente estocástica. El equipo de investigación utiliza 20 iteraciones por capa durante el entrenamiento, lo que es suficiente para abastecer el mapeo cerca del colector objetivo y al mismo tiempo abastecer los costos manejables.
Bajo estas restricciones, Hyoresxyo se comporta como una combinación convexa de corrientes residuales. La masa característica total se conserva y la norma se regulariza estrictamente, lo que elimina el crecimiento explosivo que se observa en las hiperconexiones simples. El equipo de investigación igualmente parametriza las asignaciones de entrada y salida para que los coeficientes no sean negativos, lo que evita la anulación entre flujos y mantiene clara la interpretación como promedio.
Con mHC, la magnitud de rendimiento Amax compuesta permanece limitada y alcanza un mayor de aproximadamente 1,6 en el maniquí 27B, en comparación con picos cercanos a 3000 para la cambio sin restricciones. Esa es una reducción de aproximadamente 3 órdenes de magnitud en el peor de los casos, y proviene de una restricción matemática directa más que de trucos sintonizados.
Trabajo de sistemas y gastos generales de capacitación
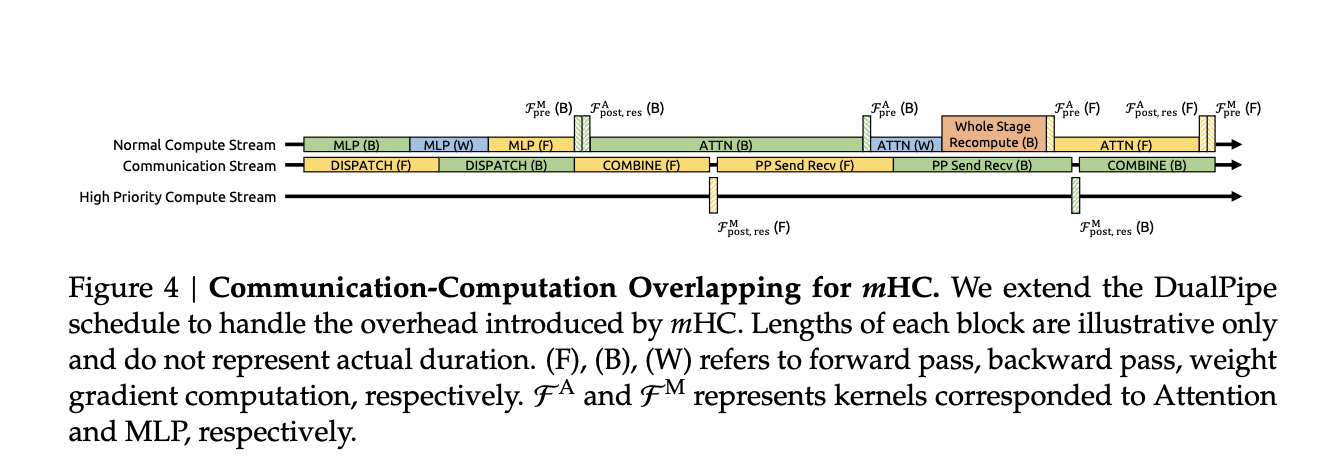
Restringir cada mezclador residual con iteraciones estilo Sinkhorn agrega costos en papel. El equipo de investigación aborda esto con varias opciones de sistemas:
- Los núcleos fusionados combinan RMSNorm, proyecciones y activación para las asignaciones de mHC para que el tráfico de memoria se mantenga bajo.
- Los puntos de control de activación basados en recálculo intercambian cálculos para la memoria recalculando las activaciones de mHC durante la retropropiedad de bloques de capas.
- La integración con un cronograma de canalización similar a DualPipe superpone la comunicación y el recálculo, de modo que el trabajo adicional no detenga el proceso de capacitación.
En carreras de entrenamiento internas a gran escalera, mHC con una tasa de expansión n igual a 4 agrega aproximadamente un 6,7 por ciento de tiempo de entrenamiento adicional en relación con la construcción de remisión. Esa emblema ya incluye tanto el cuenta adicional de Sinkhorn Knopp como las optimizaciones de infraestructura.
Resultados empíricos
El equipo de investigación entrena una combinación de modelos expertos 3B, 9B y 27B y los evalúa en un conjunto de remisión de modelos de verbo habitual, que incluye tareas como BBH, DROP, GSM8K, HellaSwag, MMLU, PIQA y TriviaQA.
Para el maniquí 27B, las cifras reportadas en un subconjunto de tareas muestran claramente el patrón:
- Serie de cojín: BBH 43,8, DROP F1 47,0
- Con hiperconexiones: BBH 48.9, DROP 51.6
- Con mHC: BBH 51,0, GOTA 53,9
Por lo tanto, las hiperconexiones ya proporcionan una rendimiento sobre el diseño residual elemental, y las múltiples hiperconexiones restringidas impulsan aún más el rendimiento al tiempo que restauran la estabilidad. Aparecen tendencias similares en otros puntos de remisión y en todos los tamaños de modelos, y las curvas de escalamiento sugieren que la preeminencia persiste en todos los presupuestos de cuenta y durante toda la trayectoria de entrenamiento en oportunidad de solo en la convergencia.
Conclusiones esencia
- mHC estabiliza corrientes residuales ampliadas: mHC, Hyper Connections restringidas por múltiples, amplía la vía residual en 4 corrientes que interactúan como HC, pero restringe las matrices de mezcla residuales en una variedad de matrices doblemente estocásticas, por lo que la propagación de prolongado significación permanece controlada por la norma en oportunidad de explotar.
- La rendimiento explosiva se reduce de ≈3000 a ≈1,6: Para un maniquí de 27B MoE, la magnitud de rendimiento Amax del mapeo residual compuesto alcanza un mayor cercano a 3000 para HC sin restricciones, mientras que mHC mantiene esta métrica limitada aproximadamente de 1,6, lo que elimina el comportamiento explosivo del flujo residual que previamente interrumpió el entrenamiento.
- Sinkhorn Knopp aplica una mezcla residual doblemente estocástica: Cada matriz de mezcla residual se proyecta con aproximadamente 20 iteraciones de Sinkhorn Knopp de modo que las filas y columnas sumen 1, lo que hace que el mapeo sea una combinación convexa de permutaciones, lo que restaura un comportamiento similar a la identidad y al mismo tiempo permite una rica comunicación entre flujos.
- Pequeños gastos generales de capacitación, ganancias posteriores mensurables: En los modelos DeepSeek MoE 3B, 9B y 27B, mHC alivio la precisión de las pruebas comparativas, por ejemplo, aproximadamente un 2,1 por ciento más en BBH para el maniquí 27B, mientras que agrega solo aproximadamente de un 6,7 por ciento de tiempo de entrenamiento adicional a través de núcleos fusionados, recómputo y programación consciente de canalizaciones.
- Introduce un nuevo eje de escalera para el diseño de LLM: En oportunidad de avanzar sólo los parámetros o la distancia del contexto, mHC muestra que diseñar explícitamente la topología y las múltiples restricciones del flujo residual, por ejemplo el orgulloso y la estructura residual, es una forma maña de desbloquear un mejor rendimiento y estabilidad en futuros modelos de verbo grandes.
Mira el DOCUMENTO COMPLETO aquí. Adicionalmente, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora igualmente puedes unirte a nosotros en Telegram.
Asif Razzaq es el director ejecutor de Marktechpost Media Inc.. Como emprendedor e ingeniero soñador, Asif está comprometido a servirse el potencial de la inteligencia sintético para el admisiblemente social. Su esfuerzo más nuevo es el extensión de una plataforma de medios de inteligencia sintético, Marktechpost, que se destaca por su cobertura en profundidad del enseñanza inconsciente y las parte sobre enseñanza profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el manifiesto.