
Con el tiempo de ejecución de Amazon EMR 7.10, Amazon EMR ha introducido EMR S3A, una implementación mejorada del conector del sistema de archivos S3A de código rajado. Este conector mejorado ahora se establece automáticamente como el conector del sistema de archivos S3 predeterminado para las opciones de implementación de Amazon EMR, incluidas Amazon EMR en EC2, Amazon EMR Servidor sin servidor, Amazon EMR en Amazon EKSy Amazon EMR en AWS OutpostsPermanecer la compatibilidad completa de API con el código rajado Apache Spark.
En el tiempo de ejecución de Amazon EMR 7.10 para Apache Spark, el conector EMR S3A exhibe un rendimiento comparable a los EMRF para las cargas de trabajo de recital, como lo demuestran TPC-DS Query Benchmark. Las ganancias de rendimiento más significativas del conector son evidentes en las operaciones de escritura, con una progreso del 7% en las sobrescrituras de partición estática y una progreso del 215% para las sobrescrituras dinámicas de partición en comparación con los EMRF. En esta publicación, mostramos las ventajas de rendimiento de recital y escritura mejoradas del uso de Amazon EMR 7.10.0 Runtime para Apache Spark con EMR S3A en comparación con EMRFS y el conector del sistema de archivos S3A de código rajado.
Descifrar Comparación de rendimiento de la carga de trabajo
Para evaluar el rendimiento de recital, utilizamos un entorno de prueba basado en Amazon EMR Runtime lectura 7.10.0 ejecutando Spark 3.5.5 y Hadoop 3.4.1. Nuestra infraestructura de prueba presentó una Nimbo de cuenta elástica de Amazon (Amazon EC2) Cluster compuesto por nueve instancias R5D.4XLarge. El nodo primario tiene 16 VCPU y 128 GB de memoria, y los ocho nodos centrales tienen un total de 128 VCPU y 1024 GB de memoria.
La evaluación del rendimiento se realizó utilizando una metodología de prueba integral diseñada para proporcionar resultados precisos y significativos. Para los datos de origen, elegimos el delegado de escalera de 3 TB, que contiene 17.7 mil millones de registros, aproximadamente 924 GB de datos comprimidos divididos en formato de archivo parquet. Las instrucciones de configuración y los detalles técnicos se pueden encontrar en el Repositorio de Github. Utilizamos el catálogo de datos en memoria de Spark para juntar metadatos para bases y tablas de datos TPC-DS.
Para producir una comparación reto y precisa entre EMR S3A vs. EMRFS e implementaciones de código rajado S3A, implementamos un enfoque de prueba trifásico:
- Escalón 1: rendimiento de raya de colchoneta:
- Establecí una raya de colchoneta utilizando la configuración predeterminada de Amazon EMR con el conector S3A de EMR
- Creó un punto de remisión para las comparaciones posteriores
- Escalón 2: Exploración EMRFS:
- Mantuvo el sistema de archivos predeterminado como EMRFS
- Preservado otras configuraciones de configuración
- Escalón 3: Prueba de código rajado S3A:
- Modificado solo el
hadoop-aws.jarArchivo reemplazándolo con la lectura Open Source Hadoop S3A 3.4.1 - Mantuvo configuraciones idénticas en otros componentes
- Modificado solo el
Este entorno de prueba controlado fue crucial para nuestra evaluación por las siguientes razones:
- Podríamos aislar el impacto del rendimiento específicamente para la implementación del conector S3A
- Eliminó posibles variables que podrían sesgar los resultados
- Proporcionó mediciones precisas de las mejoras de rendimiento entre la implementación S3A de Amazon y la alternativa de código rajado
Ejecución de pruebas y resultados
A lo abundante del proceso de prueba, mantuvimos la consistencia en las condiciones y configuraciones de la prueba, asegurándonos de que cualquier diferencia de rendimiento observada pueda atribuirse directamente a las variaciones de implementación del conector S3A. Un total de 104 consultas SparkSQL se ejecutaron en 10 iteraciones secuencialmente, y se utilizó un promedio del tiempo de ejecución de cada consulta en estas 10 iteraciones para la comparación. El promedio del tiempo de ejecución de las 10 iteraciones en el tiempo de ejecución de Amazon EMR 7.10 para Apache Spark con EMR S3A fue de 1116.87 segundos, que es 1.08 veces más rápido que el código rajado S3A y comparable con EMRFS. La futuro figura ilustra el tiempo de ejecución total en segundos.
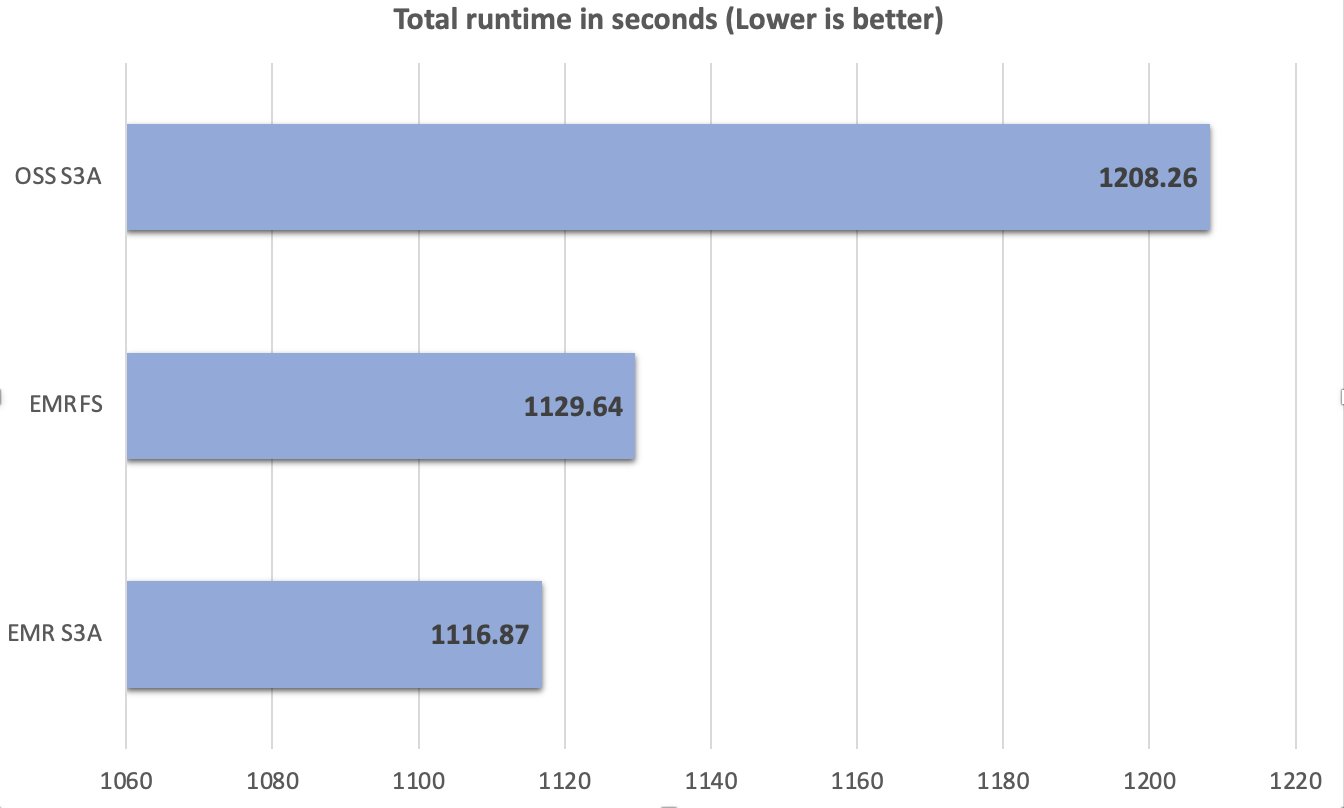
La futuro tabla resume las métricas.
| Métrico | OSS S3A | EMRFS | EMR S3A |
| Tiempo de ejecución promedio en segundos | 1208.26 | 1129.64 | 1116.87 |
| Media geométrica sobre consultas en segundos | 7.63 | 7.09 | 6.99 |
| Costo total * | $ 6.53 | $ 6.40 | $ 6.15 |
*Las estimaciones de costos detalladas se discuten más delante en esta publicación.
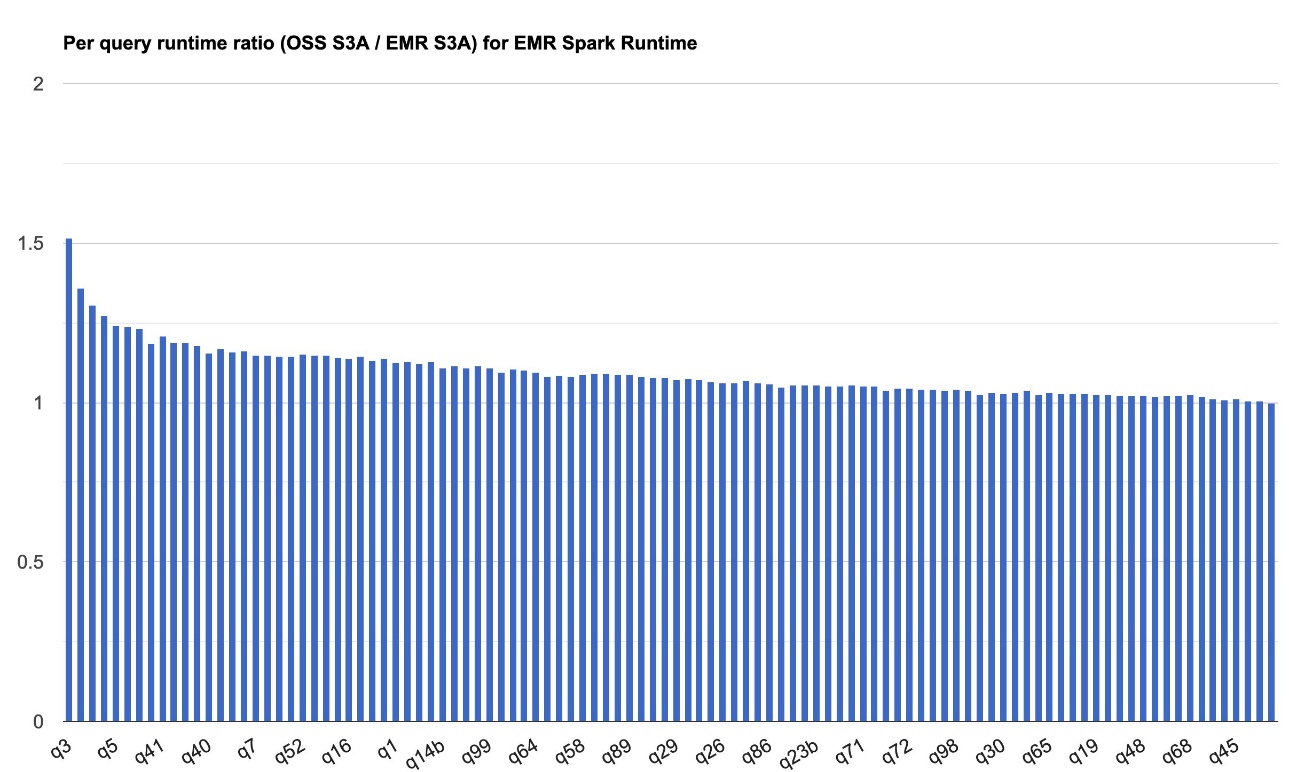
El futuro cuadro demuestra la progreso del rendimiento por QUERERY de EMR S3A en relación con el código rajado S3A en el Amazon EMR 7.10 Tiempo de ejecución para Apache Spark. La extensión de la velocidad varía de una consulta a otra, con la más rápida hasta 1.51 veces más rápida para el Q3, con Amazon EMR S3A superando a S3A de código rajado. El eje horizontal organiza las consultas de remisión TPC-DS 3TB en orden descendente en función de la progreso del rendimiento que se ve con Amazon EMR, y el eje derecho representa la magnitud de esta velocidad como una relación.
Descifrar comparación de costos
Nuestro punto de remisión genera el tiempo de ejecución total y las cifras medias geométricas para evaluar el rendimiento de tiempo de ejecución de chispa. La métrica de costos puede proporcionarnos información adicional. Las estimaciones de costos se calculan utilizando las siguientes fórmulas. Factoran en Amazon EC2, Tienda de bloques elástica de Amazon (Amazon EBS) y los costos de Amazon EMR, pero no incluyan Servicio de almacenamiento simple de Amazon (Amazon S3) Get y pongan costos.
- Costo de Amazon EC2 (incluir el costo de SSD) = número de instancias * R5D.4XLARGE TARIA HORA HORA * Tiempo de ejecución del trabajo en horas
- R5D.4XLARGE Tasa por hora = $ 1.152 por hora
- Root Amazon EBS Costo = Número de instancias * Amazon EBS por velocidad de hora GB * Tamaño de barriguita de Root EBS * Tiempo de ejecución del trabajo en horas
- Amazon EMR Costo = Número de instancias * R5D.4XLARGE Amazon EMR Costo * Trabajo Tiempo de ejecución en horas
- R5D.4xLarge Amazon EMR Costo = $ 0.27 por hora
- Costo total = Amazon EC2 Costo + Root Amazon EBS Costo + Amazon EMR Costo
La futuro tabla resume estos costos.
| Métrico | EMRFS | EMR S3A | OSS S3A |
| Tiempo de ejecución en horas | 0.5 | 0.48 | 0.51 |
| Número de instancias EC2 | 9 | 9 | 9 |
| Tamaño de Amazon EBS | 0 GB | 0 GB | 0 GB |
| Costo de Amazon EC2 | $ 5.18 | $ 4.98 | $ 5.29 |
| Costo de Amazon EBS | $ 0.00 | $ 0.00 | $ 0.00 |
| Costo de Amazon EMR | $ 1.22 | $ 1.17 | $ 1.24 |
| Costo total | $ 6.40 | $ 6.15 | $ 6.53 |
| Economía de costos | Almohadilla | EMR S3A es 1.04 veces mejor que EMRFS | EMR S3A es 1.06 veces mejor que OSS S3A |
Escriba la comparación de rendimiento de la carga de trabajo
Realizamos pruebas de remisión para evaluar el rendimiento de escritura del Amazon EMR 7.10 Time para Apache Spark.
Tabla estática/Partición sobrescribir
Evaluamos la tabla estática/partición sobrescribir el rendimiento de escritura del sistema de archivos diferente ejecutando lo futuro INSERT OVERWRITE Spark SQL Consuly. El SELECT * FROM range(...) Los datos generados por la cláusula en el momento de la ejecución. Esto produjo aproximadamente 15 GB de datos en exactamente 100 archivos de parquet en Amazon S3.
El entorno de prueba se configuró de la futuro forma:
- EMR Cluster con EMR-7.10.0 Protocolo de divulgación
- Instancia única de M5D.2XLarge (asociación primario)
- Ocho instancias M5D.2XLarge (Clan Core)
- Cubo S3 en la misma región de AWS que el clúster EMR
- El
trial_idLa propiedad utilizó un magneto UUID para evitar conflictos entre las pruebas
Resultados
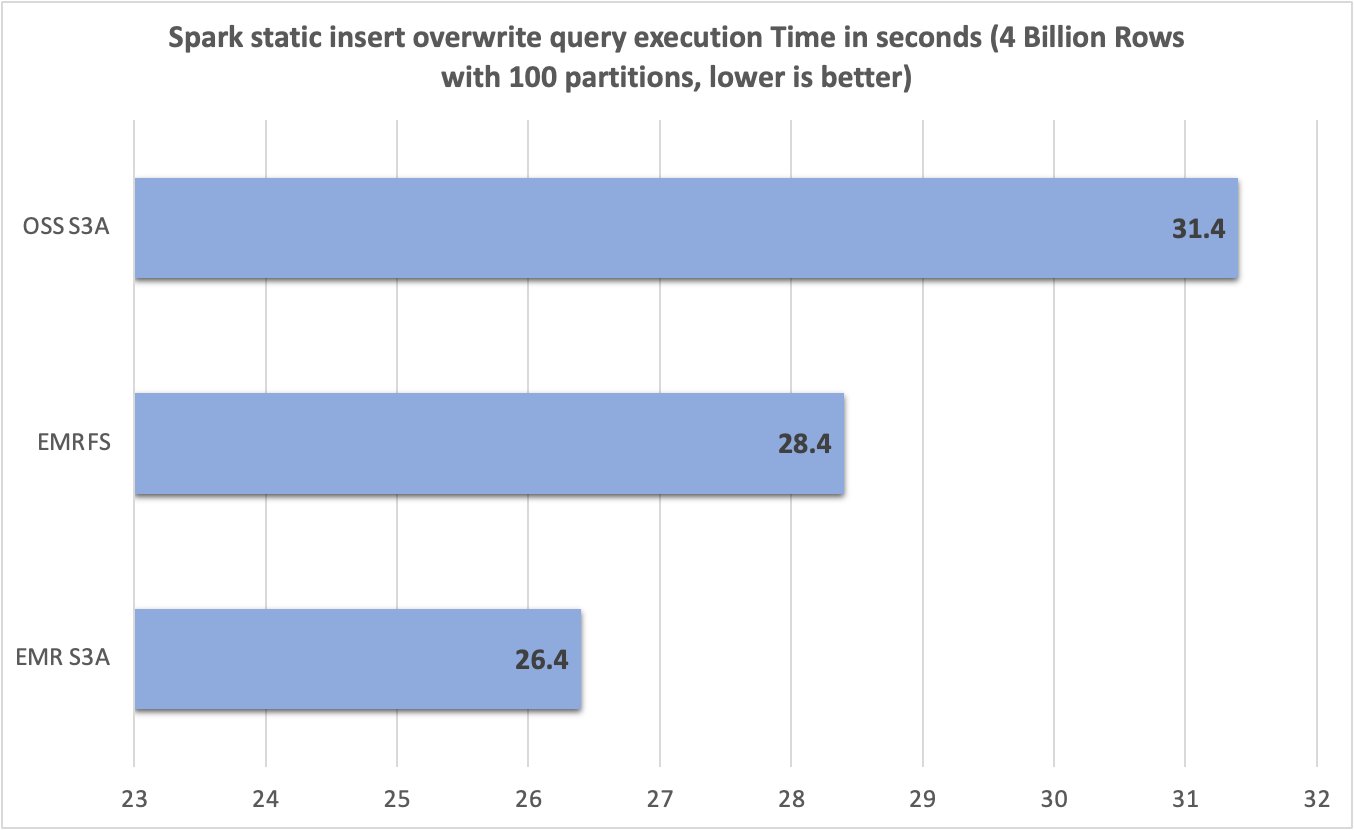
Posteriormente de ejecutar 10 pruebas para cada sistema de archivos, capturamos y resumimos los tiempos de ejecución de consultas en el futuro cuadro. Mientras que EMR S3A promedió solo 26.4 segundos, el EMRFS y el código rajado S3A promediaron 28.4 segundos y 31.4 segundos, un 1.07 veces y 1.19 veces mejoras, respectivamente.
Partition dinámica sobrescribir
Todavía evaluamos el rendimiento de escritura ejecutando lo futuro INSERT OVERWRITE Partition Dynamic Spark SQL Consuly, que se une a los datos de parquet particionados TPC-DS 3TB de la tabla web_sales y date_dim Tablas, que inserta aproximadamente 2,100 particiones, donde cada partición contiene un archivo de parquet con un tamaño combinado de aproximadamente 31.2 GB en Amazon S3.
El entorno de prueba se configuró de la futuro forma:
- EMR Cluster con EMR-7.10.0 Protocolo de divulgación
- Instancia única R5D.4XLarge (asociación perito)
- Cinco instancias R5D.4XLarge (asociación central)
- Aproximadamente 2,100 particiones con un archivo de parquet cada
- Tamaño combinado de aproximadamente 31.2 GB en Amazon S3
Resultados
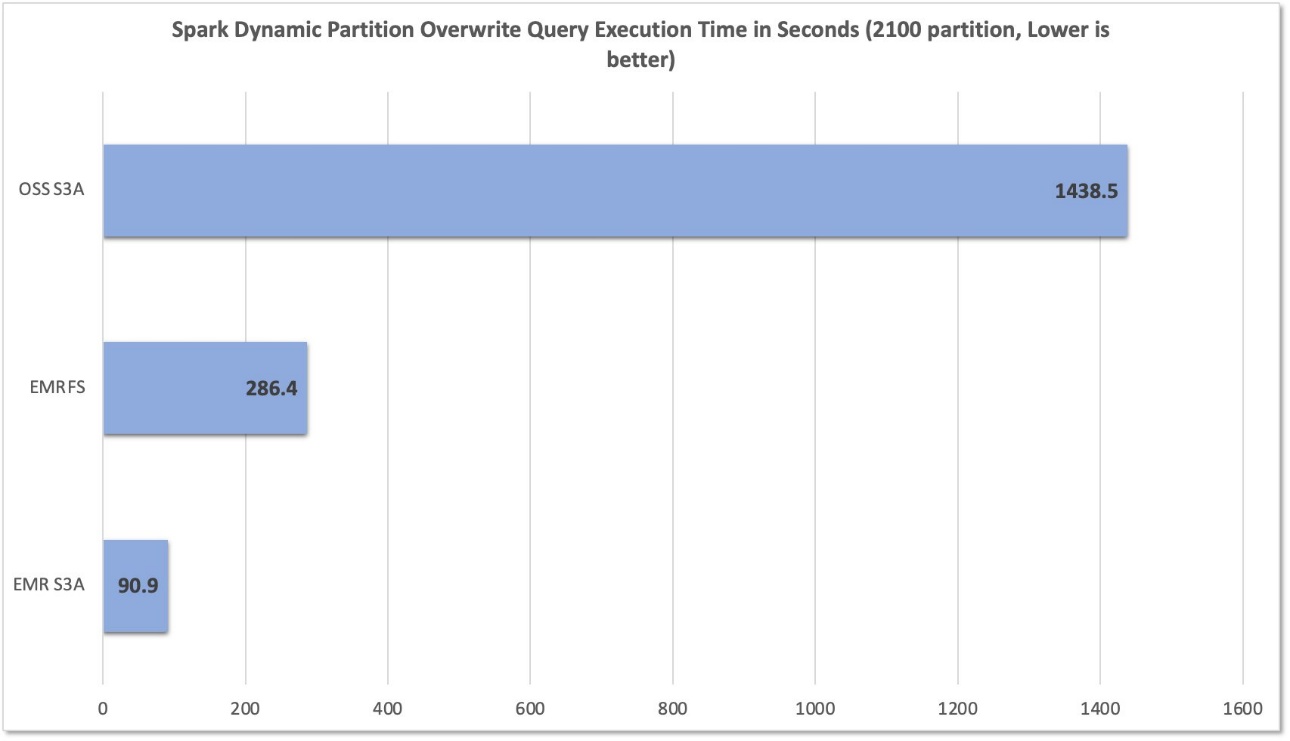
Posteriormente de ejecutar 10 pruebas para cada sistema de archivos, capturamos y resumimos los tiempos de ejecución de consultas en el futuro cuadro. Mientras que EMR S3A promedió solo 90.9 segundos, el EMRFS y el código rajado S3A promediaron 286.4 segundos y 1,438.5 segundos, una progreso de 3.15 veces y 15.82 veces, respectivamente.
Síntesis
Amazon EMR progreso constantemente su tiempo de ejecución Apache Spark y su conector S3A, ofreciendo mejoras de rendimiento continuas que ayudan a los clientes de Big Data a ejecutar cargas de trabajo de disección de forma más rentable. Más allá de las ganancias de rendimiento, el cambio clave a S3A introduce ventajas críticas, incluida la estandarización mejorada, la portabilidad multiplataforma mejorada y el apoyo sólido impulsado por la comunidad, todo mientras se mantiene o superan los puntos de remisión de rendimiento establecidos por la implementación inicial de EMRFS.
Le recomendamos que se mantenga actualizado con el posterior divulgación de Amazon EMR para beneficiarse el posterior rendimiento y los beneficios de funciones. Suscríbete al blog de AWS Big Data Alimento RSS Para obtener más información sobre el tiempo de ejecución de Amazon EMR para Apache Spark, las mejores prácticas de configuración y los consejos de ajuste.
Sobre los autores