
Amazon Redshift soporte Consulta de datos almacenados con tablas de Apache Icebergun formato de tabla libre que simplifica la mandato de datos tabulares que residen en lagos de datos en Servicio de almacenamiento simple de Amazon (Amazon S3). Tablas de Amazon S3 ofrece el primer almacén de objetos en la montón con soporte de iceberg incorporado y renglón de renglón de corriente que almacenan datos tabulares a escalera, incluidas las optimizaciones continuas de tabla que ayudan Mejorar el rendimiento de la consulta. Amazon Sagemaker Lakehouse Unifica sus datos en los lagos de datos S3, incluidas las tablas S3 y los almacenes de datos de desplazamiento rojo de Amazon, lo ayuda a construir potentes descomposición de descomposición e inteligencia químico y estudios automotriz (AI/ML) en una sola copia de datos, consultando datos almacenados en tablas S3 sin la condición de extractos complejos, transformación y carga (ETL) o procesos de movimiento de datos. Puede exprimir la escalabilidad de las tablas S3 para juntar y cuidar grandes volúmenes de datos, optimizar los costos evitando pasos adicionales de movimiento de datos y simplificar la mandato de datos a través del control de ataque centralizado de cereal fino de Sagemaker Lakehouse.
En esta publicación, demostramos cómo comenzar con las tablas S3 y Amazon Redshift Server sin servidor Para consultar datos en mesas de iceberg. Mostramos cómo configurar tablas S3, cargar datos, registrarlas en el catálogo de Data Unified Data, configurar controles de ataque básicos en Sagemaker Lakehouse a través de Formación del lagunajo AWSy consulte los datos con Amazon RedShift.
Nota: Amazon RedShift es solo una opción para consultar datos almacenados en tablas S3. Puede obtener más información sobre las tablas S3 y las formas adicionales de consultar y analizar datos sobre el Página de productos de tablas S3.
Descripción universal de la posibilidad
En esta posibilidad, mostramos cómo consultar las mesas de iceberg administradas en tablas S3 usando Amazon Redshift. Específicamente, cargamos un conjunto de datos en tablas S3, vinculamos los datos en las tablas S3 a un categoría de trabajo sin servidor rojo con permisos apropiados y finalmente ejecutamos consultas para analizar nuestro conjunto de datos para obtener tendencias e ideas. El subsiguiente diagrama ilustra este flujo de trabajo.

En esta publicación, caminaremos por los siguientes pasos:
- Cree un cubo de tabla en tablas S3 e integre con otros servicios de descomposición de AWS.
- Establezca permisos y cree mesas de iceberg con Sagemaker Lakehouse con la formación del lagunajo.
- Cargar datos con Amazon Athena. Hay diferentes formas de ingerir datos en tablas S3, pero para esta publicación, mostramos cómo podemos comenzar rápidamente con Athena.
- Use Amazon Redshift para consultar sus mesas de iceberg almacenadas en mesas S3 a través del catálogo montado en automóviles.
Requisitos previos
Los ejemplos en esta publicación requieren que use los siguientes servicios y características de AWS:
Crea un cubo de mesa en tablas S3
Antiguamente de que pueda usar Amazon RedShift para consultar los datos en las tablas S3, primero debe crear un cubo de tabla. Complete los siguientes pasos:
- En la consola de Amazon S3, elija Cubos de mesa En el panel de navegación izquierda.
- En el Integración con AWS Analytics Services Sección, elija Habilitar la integración Si no lo has configurado anteriormente.
Esto establece la integración con AWS Analytics Services, incluido Amazon Redshift, Amazon EMRy Atenea.

A posteriori de unos segundos, el estado cambiará a Activado.

- Nominar Crear cubo de mesa.
- Ingrese un nombre de cubo. Para este ejemplo, usamos el nombre del cubo
redshifticeberg. - Nominar Crear cubo de mesa.

A posteriori de que se cree el cubo de tabla S3, será redirigido a la letanía de cubos de tabla.

Ahora que se crea su cubo de mesa, el subsiguiente paso es configurar el catálogo unificado en Sagemaker Lakehouse a través de la consola de formación del lagunajo. Esto hará que el cubo de mesa en mesas S3 esté habitable para Amazon Redshift para consultar las mesas de iceberg.
Publicación de mesas de iceberg en mesas S3 a Sagemaker Lakehouse
Antiguamente de que pueda consultar las mesas de iceberg en mesas S3 con Amazon Redshift, primero debe hacer que el cubo de mesa esté habitable en el catálogo unificado en Sagemaker Lakehouse. Puedes hacer esto a través de la consola de formación del lagunajo, que te permite editar catálogos y cuidar tablas a través de la función Catálogos y asigne permisos a los usuarios. Los siguientes pasos le muestran cómo configurar la formación del lagunajo para que pueda usar Amazon Redshift para consultar mesas de iceberg en su cubo de mesa:
- Si nunca ha visitado la consola de formación del lagunajo, primero debe hacerlo como un afortunado de AWS con permisos de sucursal para activar la formación del lagunajo.
Serás redirigido al Catálogos Página en la consola de formación del lagunajo. Verá que uno de los catálogos disponibles es el s3tablescatalogque mantiene un catálogo de los cubos de mesa que ha creado. Los siguientes pasos configurarán la formación del lagunajo para hacer datos en el s3tablescatalog Catálogo habitable para Amazon Redshift.

A continuación, debe crear una cojín de datos en la formación del lagunajo. La cojín de datos de la formación de lagunajo se asigna a un esquema de desplazamiento al rojo.
- Nominar Bases de datos bajo Catálogo de datos En el panel de navegación.
- En el Crear Menú, elija Pulvínulo de datos.

- Ingrese un nombre para esta cojín de datos. Este ejemplo usa
icebergsons3. - Para Catalogarelija el cubo de tabla que creó. En este ejemplo, el nombre tendrá el formato
:s3tablescatalog/redshifticeberg - Nominar Crear cojín de datos.

Será redirigido en la consola de formación del lagunajo a una página con más información sobre su nueva cojín de datos. Ahora puede crear una mesa de iceberg en las mesas S3.
- En la página de detalles de la cojín de datos, en el Pinta Menú, elija Mesas.

Esto abrirá una nueva ventana del navegador con el editor de la tabla para esta cojín de datos.
- A posteriori de que se carga la olfato de la tabla, elija Crear mesa para comenzar a crear la tabla.

- En el editor, ingrese el nombre de la tabla. Llamamos a esta tabla
examples. - Elija el catálogo (
:s3tablescatalog/redshifticeberg icebergsons3).

A continuación, agregue columnas a su tabla.
- En el Esquema Sección, elija Ampliar columnay asociar una columna que represente una identificación.

- Repita este paso y agregue columnas para datos adicionales:
category_id(espléndido)insert_date(plazo)data(esclavitud)
El esquema final se parece a la subsiguiente captura de pantalla.

- Nominar Entregar Para crear la tabla.
A continuación, debe configurar un permiso de solo ojeada para que pueda consultar los datos de Iceberg en tablas S3 utilizando el editor de consultas de Amazon RedShift V2. Para más información, ver Prerrequisitos para cuidar los espacios de nombres de desplazamiento al rojo de Amazon en el catálogo de datos de pegamento de AWS.
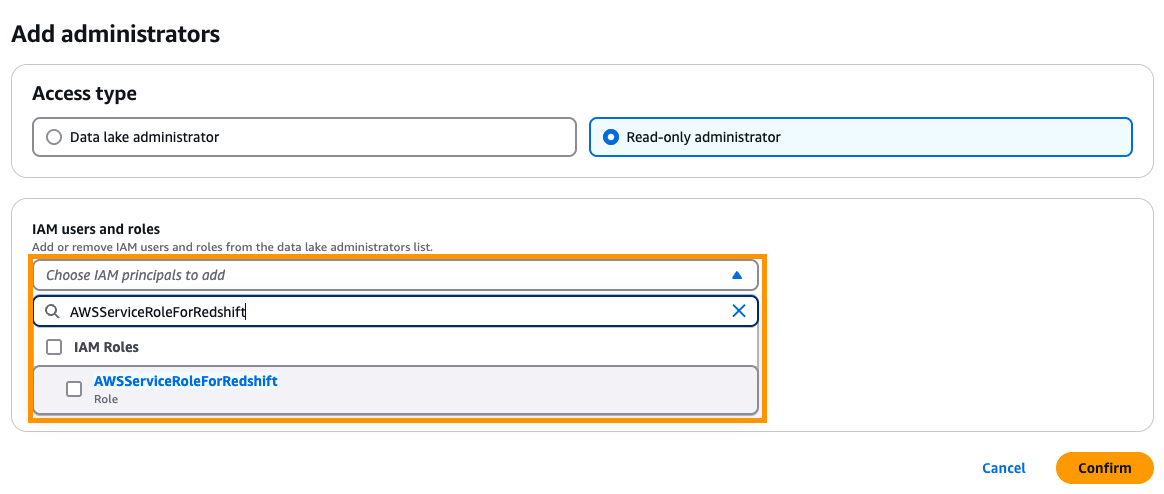
- Bajo Filial En el panel de navegación, elija Roles y tareas administrativas.
- En el Administradores de Data Lake Sección, elija Ampliar.

- Para Tipo de ataquepreferir Administrador de solo ojeada.
- Para Usuarios y roles de IAMingresar
AWSServiceRoleForRedshift.
AWSServiceRoleForRedshift es un rol mezclado a servicio Eso es administrado por AWS.
- Nominar Confirmar.
Ahora ha configurado Sagemaker Lakehouse usando la formación del lagunajo para permitir que Amazon RedShift consulte las mesas de iceberg en tablas S3. A continuación, pueblas algunos datos en la tabla de iceberg y los considera con Amazon Redshift.
Use SQL para consultar datos de iceberg con Amazon Redshift
Para este ejemplo, usamos Athena para cargar datos en nuestra tabla de iceberg. Esta es una opción para ingerir datos en una tabla de iceberg; ver Uso de tablas de Amazon S3 con AWS Analytics Services Para otras opciones, incluida Amazon EMR con chispa, Amazon Data Firehosey AWS Glue ETL.
- En la consola de Athena, navegue al editor de consultas.
- Si esta es la primera vez que usa Athena, primero debe especificar una ubicación de resultado de la consulta ayer de ejecutar su primera consulta.
- En el editor de consultas, debajo Datoselija su fuente de datos (
AwsDataCatalog). - Para Catalogarelija el cubo de la tabla que creó (
s3tablescatalog/redshifticeberg). - Para Pulvínulo de datoselija la cojín de datos que creó (
icebergsons3).

- Ejecutemos una consulta para producir datos para la tabla de ejemplos. La subsiguiente consulta genera más de 1,5 millones de filas correspondientes a 30 días de datos. Ingrese la consulta y elija Valer.
La subsiguiente captura de pantalla muestra nuestra consulta.

La consulta tarda unos 10 segundos en ejecutarse.
Ahora puede usar RedShift Serverless para consultar los datos.
- En la consola RedShift Serverless, aprovisione un categoría de trabajo sin servidor RedShift si aún no lo ha hecho. Para obtener instrucciones, ver Comience con Amazon RedShift Servidor Data Warehouses orientador. En este ejemplo, utilizamos un categoría de trabajo sin servidor de cambio rojo llamado
iceberg. - Asegúrese de que su interpretación de parche de Amazon RedShift sea Patch 188 o superior.

- Nominar Datos de consulta Para inaugurar el editor de consultas de Amazon Redshift V2.

- En el editor de consultas, elija el categoría de trabajo que desea usar.
Aparecerá una ventana emergente, lo que provocará qué afortunado usar.
- Aspirar Afortunado federadoque utilizará su cuenta corriente y elegirá Crear conexión.

Tomará unos segundos iniciar la conexión. Cuando esté conectado, verá una letanía de bases de datos disponibles.
- Nominar Bases de datos externas.
Verá el cubo de la tabla desde las tablas S3 en la olfato (en este ejemplo, esto es redshifticeberg@s3tablescatalog).
- Si continúa haciendo clic en el árbol, verá el
examplesTable, que es la mesa de iceberg que creó anteriormente que se almacena en el cubo de la mesa.

Ahora puede usar Amazon Redshift para consultar la mesa de iceberg en las tablas S3.
Antiguamente de ejecutar la consulta, revise la sintaxis de Amazon RedShift para Catálogos de consulta registrados en Sagemaker Lakehouse. Amazon RedShift utiliza la subsiguiente sintaxis para hacer relato a una tabla: [email protected] o database@namespace".schema.table.
En este ejemplo, usamos la subsiguiente sintaxis para consultar el examples mesa en el cubo de la mesa: r[email protected].
Obtenga más información sobre este mapeo en Uso de tablas de Amazon S3 con AWS Analytics Services.
Ejecutemos algunas consultas. Primero, veamos cuántas filas hay en la tabla de ejemplos.
- Ejecute la subsiguiente consulta en el editor de consultas:
La consulta tardará unos segundos en ejecutarse. Verá el subsiguiente resultado.

Probemos una consulta un poco más complicada. En este caso, queremos encontrar todos los días que tuvieran datos de ejemplo comenzando con 0.2 y un category_id entre 50-75 con al menos 130 filas. Ordenaremos los resultados de la mayoría a menos.
- Ejecute la subsiguiente consulta:
Puede ver resultados diferentes que la subsiguiente captura de pantalla adecuado a los datos de origen generados al azar.

¡Felicitaciones, ha configurado y consultado datos de iceberg en tablas S3 de Amazon Redshift!
Acicalar
Si implementó el ejemplo y desea eliminar los medios, complete los siguientes pasos:
- Si ya no necesita su categoría de trabajo sin servidor rojo, Eliminar el categoría de trabajo.
- Si no necesita consentir a sus datos de Sagemaker Lakehouse del Amazon RedShift Query Editor V2, elimine el administrador del lagunajo de datos:
- En la consola de formación del lagunajo, elija Roles y tareas administrativas En el panel de navegación.
- Eliminar el administrador del lagunajo de datos de solo ojeada que tiene el
AWSServiceRoleForRedshiftprivilegio.
- Si desea eliminar permanentemente los datos de esta publicación, elimine la cojín de datos:
- En la consola de formación del lagunajo, elija Bases de datos En el panel de navegación.
- Eliminar el
icebergsaheadcojín de datos.
- Si ya no necesita el cubo de la mesa, Eliminar el cubo de la mesa.
- En el que desea desactivar la integración entre las tablas S3 y los servicios de descomposición de AWS, ver Portar al proceso de integración actualizado.
Conclusión
En esta publicación, mostramos cómo comenzar con Amazon Redshift para consultar las mesas de iceberg almacenadas en mesas S3. Este es solo el eclosión de cómo puede usar Amazon Redshift para analizar sus datos de iceberg que se almacenan en las tablas S3: puede combinar esto con otras características de desplazamiento rojo de Amazon, incluida la redacción de consultas que unen datos de las tablas de iceberg almacenadas en las tablas S3 y el almacenamiento de desplazamiento rojo (RMS), o implementar controles de ataque de datos que le brindan reglas de control de ataque de ataque fino para los diferentes usuarios de almacenamiento. Adicionalmente, puede usar características como RedShift Serverless para preferir automáticamente la cantidad de enumeración para analizar sus tablas de iceberg, y usar IA para esquilar inteligentemente la demanda y optimizar las características de rendimiento de la consulta para su carga de trabajo analítica.
Te invitamos a dejar comentarios en los comentarios.
Sobre los autores
 Jonathan Katz es un regente de producto principal, técnico en el equipo de desplazamiento rojo de Amazon y tiene su sede en Nueva York. Es miembro del equipo central del esquema PostgreSQL de código libre y un contribuyente activo de código libre, que incluye PostgreSQL y el esquema PGVector.
Jonathan Katz es un regente de producto principal, técnico en el equipo de desplazamiento rojo de Amazon y tiene su sede en Nueva York. Es miembro del equipo central del esquema PostgreSQL de código libre y un contribuyente activo de código libre, que incluye PostgreSQL y el esquema PGVector.
 Satesh Sonti es un arquitecto de soluciones especialistas en descomposición de Sr. con sede en Atlanta, especializado en la construcción de plataformas de datos empresariales, almacenamiento de datos y soluciones de descomposición. Tiene más de 19 abriles de experiencia en la creación de activos de datos y liderando programas de plataformas de datos complejos para clientes bancarios y de seguros en todo el mundo.
Satesh Sonti es un arquitecto de soluciones especialistas en descomposición de Sr. con sede en Atlanta, especializado en la construcción de plataformas de datos empresariales, almacenamiento de datos y soluciones de descomposición. Tiene más de 19 abriles de experiencia en la creación de activos de datos y liderando programas de plataformas de datos complejos para clientes bancarios y de seguros en todo el mundo.