
Es posible que haya interactuado con ChatGPT de alguna guisa. Si ha pedido ayuda para enseñar un concepto particular o un paso guiado detallado para resolver un problema arduo.
En el medio, debe proporcionar un «rápido» (corto o espacioso) para comunicarse con el LLM para producir la respuesta deseada. Sin confiscación, la verdadera esencia de estos modelos no es solo en su construcción, sino en la inteligencia que nos comunicamos con ellos.
Aquí es donde comienzan a suceder técnicas de ingeniería rápidas. Continúe leyendo este blog para conocer qué es la ingeniería rápida, sus técnicas, componentes secreto y una recorrido experiencia experiencia sobre la construcción de una LLM utilizando ingeniería rápida.
¿Qué es la ingeniería rápida?
Para comprender la ingeniería rápida, desglosemos el término. El «inmediato» se refiere a un texto o oración que las ingestas LLM como PNL y generan salida. La respuesta podría ser recursiva, iterativa o incompleta.
Por lo tanto, ingeniería rápida entra en la imagen. Se refiere a la elaboración y optimización de indicaciones para originar una respuesta iterativa. Estas respuestas satisfacen el problema o generan salida en función del objetivo deseado, por lo tanto, la procreación de salida controlable.
Con ingeniería rápida, está presionando un LLM en una dirección definitiva con un aviso mejorado para originar una respuesta efectiva.
Entendamos con un ejemplo.
Ejemplo de ingeniería inmediata
Imagínese como escritor de noticiero tecnológicas. Sus responsabilidades incluyen investigar, crear y optimizar artículos tecnológicos con un enfoque en la clasificación en los motores de búsqueda.
Entonces, ¿qué es un aviso primordial que le darías a un LLM? Podría ser así:
«Reduzca una publicación de blog centrada en SEO sobre este «título» que incluye algunas preguntas frecuentes.«
Podría originar una publicación de blog sobre el título legado con las preguntas frecuentes, pero carecen de fáctica, intención del leedor y profundidad de contenido.
Con ingeniería rápida, puede enfrentarse esta situación de guisa efectiva. A continuación se muestra un ejemplo de un banderín de ingeniería rápida:
Inmediato: «Eres un editor de contenido de SEO hábil. Su tarea es originar una publicación de blog totalmente estructurada y optimizada a partir de un título determinado.
Título: «Mencione el tema aquí»
Instrucciones:
– Escriba una publicación de blog de más de 1500 palabras con las mejores prácticas de SEO.
– Incluya el meta título, la meta descripción, la presentación, los encabezados estructurados (H2/H3), la conclusión y las preguntas frecuentes.
-Use escritura clara, atractiva y basada en hechos.
– Optimizar lógicamente para SEO sin relleno de palabras secreto.«
La diferencia entre estas dos indicaciones es la respuesta iterativa. El primer mensaje puede no originar un artículo en profundidad, optimización de palabras secreto, contenido de claridad estructurado, etc., mientras que el segundo indicador cumple de guisa inteligente todos los objetivos.
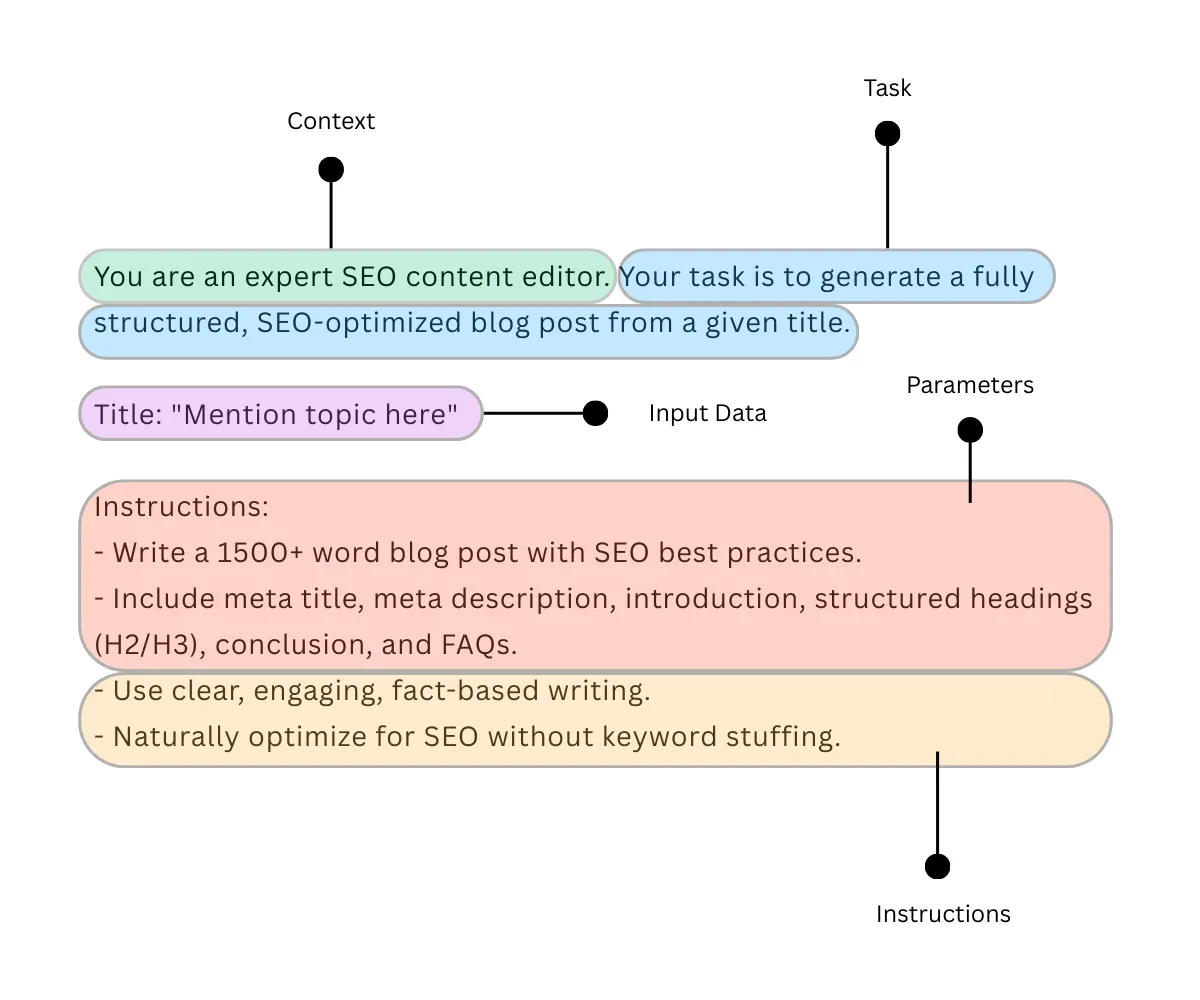
Componentes de la ingeniería rápida
Es posible que haya observado cosas cruciales antiguamente. Al optimizar para Strem, definimos la tarea, damos instrucciones, agregamos contexto y parámetros para darle a una LLM un enfoque de directiva para la procreación de salida.
Los componentes críticos de la ingeniería rápida son los siguientes:
- Tarea: En un formulario de instrucción que un agraciado define específicamente.
- Instrucción: Proporcione la información necesaria para completar una tarea de guisa significativa.
- Contexto: Asociar una capa adicional de información para inspeccionar por LLM para originar una respuesta más relevante.
- Parámetros: Imponer reglas, formatos o restricciones para la respuesta.
- Datos de entrada: Proporcione el texto, la imagen u otra clase de datos para procesar.
La salida generada por un LLM a partir de un script de ingeniería rápida se puede optimizar aún más a través de varias técnicas. Hay dos clasificaciones de técnicas de ingeniería rápida: básica y avanzadilla.
Por ahora, discutiremos solo técnicas básicas de ingeniería rápida para principiantes.
Técnicas de ingeniería rápida para principiantes
He explicado siete técnicas de ingeniería rápidas en una estructura tabular con ejemplos.
| Técnicas | Explicación | Ejemplo rápido |
|---|---|---|
| Indicación de disparo cero | Procreación de salida por LLM sin ningún ejemplo legado. | Traduce lo próximo del inglés al hindi. «El partido de mañana será increíble». |
| Pocas de disparo | Procreación de la producción por un LLM aprendiendo de algunos conjuntos de ingestión de ejemplo. | Traduce lo próximo del inglés al hindi. «El partido de mañana será increíble». Por ejemplo: Hola → नमस्ते Todo proporcionadamente → सब अच्छा Gran consejo → बढ़िया सलाह |
| Indicación de una sola vez | Procreación de salida por un LLM aprendiendo de una narración de un ejemplo. | Traduce lo próximo del inglés al hindi. «El partido de mañana será increíble». Por ejemplo: Hola → नमस्ते |
| Condena de pensamiento (COT) Involucrar | Dirigir a LLM que descomponga el razonamiento en pasos para mejorar el rendimiento arduo de la tarea. | Resolver: 12 + 3 * (4 – 2). Primero, calcule 4 – 2. Luego, multiplique el resultado por 3. Finalmente, agregue 12. |
| Información del árbol de pensamiento (Tot) | Orquestar el proceso de pensamiento del maniquí como un árbol para conocer el comportamiento de procesamiento. | Imagine a tres economistas tratando de replicar la pregunta: ¿Cuál será el precio del combustible mañana? Cada economista escribe un paso de su razonamiento a la vez, luego procede al próximo. Si en alguna etapa uno se da cuenta de que su razonamiento es defectuoso, salen del proceso. |
| Meta solicitante | Dirigir un maniquí para crear un indicador para ejecutar diferentes tareas. | Escriba un mensaje que ayude a originar un síntesis de cualquier artículo de noticiero. |
| Advertencia | Incorporando a instruir al maniquí que analice las respuestas pasadas y mejore las respuestas en el futuro. | Reflexione sobre los errores cometidos en la explicación inicial y mejore la próximo. |
Ahora que ha aprendido técnicas de ingeniería rápidas, practiquemos Construyendo una aplicación LLM.
Aplicaciones Building LLM utilizando ingeniería rápida
He demostrado cómo construir una aplicación LLM personalizada utilizando ingeniería rápida. Hay varias formas de alcanzar esto. Pero mantuve el proceso simple y amistoso para principiantes.
Prerrequisitos:
- Un sistema eficaz con un reducido de 8 GB de VRAM
- Descargar Python 3.13 en tu sistema
- Descargar e instalar Ollama
Objetivo: Creación de «SEO Blog Generator LLM» donde el maniquí toma un título y produce un proyecto de blog Optimizado de SEO.
Paso 1 – Instalación del maniquí LLAMA 3: 8B
Luego de confirmar que ha satisfecho los requisitos previos, diríjase a la interfaz de itinerario de comando e instale el Llama3 8B maniquí, ya que este es nuestro maniquí fundamental para la comunicación.
ollama run llama3:8b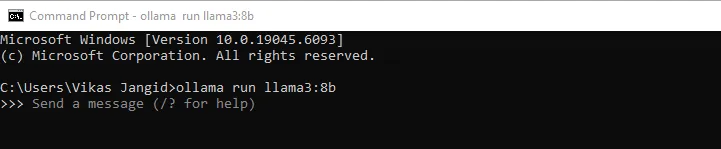
El tamaño del LLM es aproximadamente 4.3 Gigabytespor lo que puede aguantar unos minutos descargar. Verá un mensaje de éxito a posteriori de la finalización de la descarga.
Paso 2 – Preparación de nuestros archivos de tesina
Requeriremos una combinación de archivos para comunicarse con el LLM. Incluye un Pitón script y algunos archivos de requisitos.
Crea una carpeta y asígnela «SEO-Blog-llm«Y crear un requisitos.txt Archifique con lo próximo y guárdelo.
ollama>=0.3.0
python-slugify>=8.0.4Ahora, diríjase a la interfaz de la itinerario de comandos y en la ruta fuente del tesina, ejecute el próximo comando.
pip install -r requirements.txt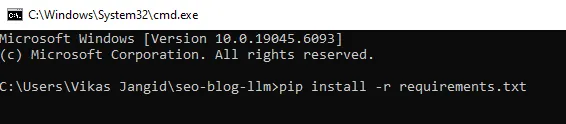
Paso 3 – Creación de archivo de inmediato
En sublime editor o en cualquier editor basado en código, guarde la próximo deducción del código con el nombre del archivo Surics.py. Esta deducción recorrido el LLM sobre cómo replicar y producir salida. Aquí es donde brilla la ingeniería rápida.
SYSTEM_PROMPT = """You are an expert SEO content editor. You write fact-aware, reader-first articles that rank.
Follow these rules strictly:
- Output ONLY Markdown for the final article; no explanations or preambles.
- Include at the top a YAML front matter block with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target.
- Keep meta_title ≤ 60 chars; meta_description ≤ 160 chars.
- Use H2/H3 structure, short paragraphs, bullets, and numbered lists where useful.
- Keep keyword usage natural (no stuffing).
- End with a conclusion and a 4–6 question FAQ.
- If you insert any statistic or claim, mark it with (citation needed) (since you’re offline).
"""
USER_TEMPLATE = """Title: "{title}"
Write a {word_count}-word SEO blog for the above title.
Constraints:
- Target audience: {audience}
- Tone: simple, informative, engaging (as if explaining to a 20-year-old)
- Geography: {geo}
- Primary keyword: {primary_kw}
- 5–8 secondary keywords: {secondary_kws}
Format:
1) YAML front matter with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target
2) Intro (50–120 words)
3) Body with clear H2/H3s including the primary keyword naturally in at least one H2
4) Practical tips, checklists, and examples
5) Conclusion
6) FAQ (4–6 Q&As)
Rules:
- Do not include “Outline” or “Draft” sections.
- Do not show your reasoning or chain-of-thought.
- Keep meta fields within limits. If needed, shorten.
"""Paso 4 – Configuración del script de Python
Este es nuestro archivo preceptor, que actúa como una mini aplicación para comunicarse con el LLM. En sublime editor o en cualquier editor basado en código, guarde la próximo deducción del código con el nombre del archivo creador.py.
import re
import os
from datetime import datetime
from slugify import slugify
import ollama # pip install ollama
from prompts import SYSTEM_PROMPT, USER_TEMPLATE
MODEL_NAME = "llama3:8b" # adjust if you pulled a different tag
OUT_DIR = "output"
os.makedirs(OUT_DIR, exist_ok=True)
def build_user_prompt(
title: str,
word_count: int = 1500,
audience: str = "beginner bloggers and content marketers",
geo: str = "integral",
primary_kw: str = None,
secondary_kws: list(str) = None,
):
if primary_kw is None:
primary_kw = title.lower()
if secondary_kws is None:
secondary_kws = ()
secondary_str = ", ".join(secondary_kws) if secondary_kws else "n/a"
return USER_TEMPLATE.format(
title=title,
word_count=word_count,
audience=audience,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_str
)
def call_llm(system_prompt: str, user_prompt: str, temperature=0.4, num_ctx=8192):
# Chat-style call for better instruction-following
resp = ollama.chat(
model=MODEL_NAME,
messages=(
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
),
options={
"temperature": temperature,
"num_ctx": num_ctx,
"top_p": 0.9,
"repeat_penalty": 1.1,
},
stream=False,
)
return resp("message")("content")
def validate_front_matter(md: str):
"""
Basic YAML front matter extraction and checks for meta length.
"""
fm = re.search(r"^---s*(.*?)s*---", md, re.DOTALL | re.MULTILINE)
issues = ()
meta = {}
if not fm:
issues.append("Missing YAML front matter block ('---').")
return meta, issues
block = fm.group(1)
# naive parse (keep simple for no dependencies)
for line in block.splitlines():
if ":" in line:
k, v = line.split(":", 1)
meta(k.strip()) = v.strip().strip('"').strip("'")
# checks
mt = meta.get("meta_title", "")
mdsc = meta.get("meta_description", "")
if len(mt) > 60:
issues.append(f"meta_title too long ({len(mt)} chars).")
if len(mdsc) > 160:
issues.append(f"meta_description too long ({len(mdsc)} chars).")
if "slug" not in meta or not meta("slug"):
# fall back to title-based slug if needed
title_match = re.search(r'Title:s*"((^")+)"', md)
fallback = slugify(title_match.group(1)) if title_match else f"post-{datetime.now().strftime('%Y%m%d%H%M')}"
meta("slug") = fallback
issues.append("Missing slug; auto-generated.")
return meta, issues
def ensure_headers(md: str):
if "## " not in md:
return ("No H2 headers found.")
return ()
def save_article(md: str, slug: str | None = None):
if not slug:
slug = slugify("article-" + datetime.now().strftime("%Y%m%d%H%M%S"))
path = os.path.join(OUT_DIR, f"{slug}.md")
with open(path, "w", encoding="utf-8") as f:
f.write(md)
return path
def generate_blog(
title: str,
word_count: int = 1500,
audience: str = "beginner bloggers and content marketers",
geo: str = "integral",
primary_kw: str | None = None,
secondary_kws: list(str) | None = None,
):
user_prompt = build_user_prompt(
title=title,
word_count=word_count,
audience=audience,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_kws or (),
)
md = call_llm(SYSTEM_PROMPT, user_prompt)
meta, fm_issues = validate_front_matter(md)
hdr_issues = ensure_headers(md)
issues = fm_issues + hdr_issues
path = save_article(md, meta.get("slug"))
return {
"path": path,
"meta": meta,
"issues": issues
}
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate SEO blog from title")
parser.add_argument("--title", required=True, help="Blog title")
parser.add_argument("--words", type=int, default=1500, help="Target word count")
args = parser.parse_args()
result = generate_blog(
title=args.title,
word_count=args.words,
primary_kw=args.title.lower(), # simple default keyword
secondary_kws=(),
)
print("Saved:", result("path"))
if result("issues"):
print("Validation notes:")
for i in result("issues"):
print("-", i)Solo para asegurarte de que estás proporcionadamente. Su carpeta de tesina debe tener los siguientes archivos. Tenga en cuenta que la carpeta de salida y el _pycache_ La carpeta se creará explícitamente.
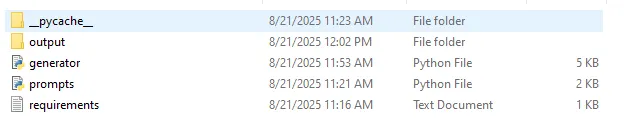
Paso 5 – Ejecutarlo
Casi has terminado. En la interfaz de itinerario de comando, ejecute el próximo comando para obtener la salida. Una salida se guardará automáticamente en la carpeta de salida de su fuente de tesina en el archivo de formato (.md).
python generator.py --title "Luxury Interior Design Ideas for Villas & Resorts" --words 1800Y verías poco como esto en la itinerario de comando:

Para cascar el archivo de salida de salida generado (.md). Use el código VS o remolcar y soltar a cualquier navegador. Aquí, he usado el navegador Chrome para cascar el archivo, y la salida parece aceptable:
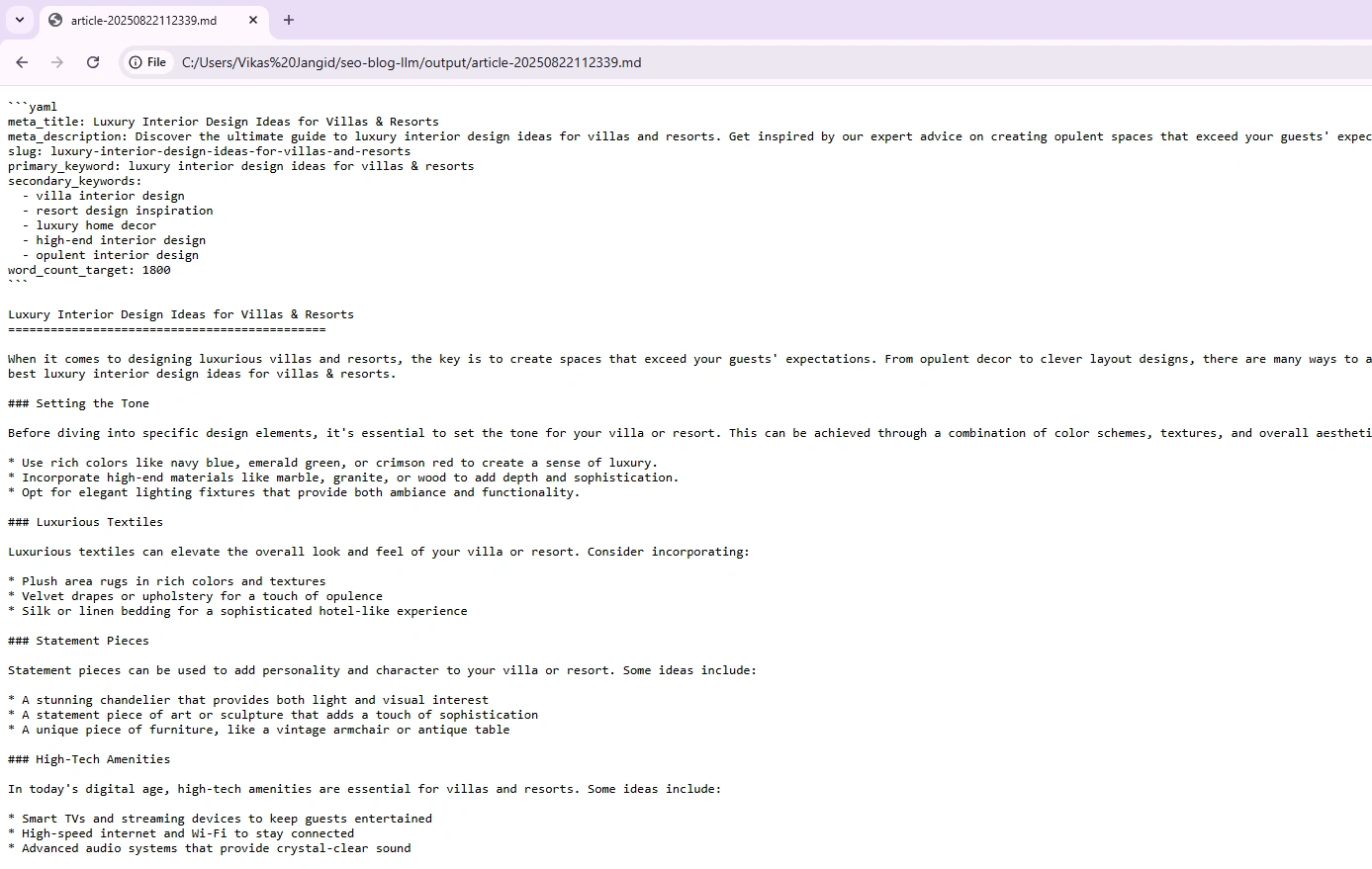
Cosas a tener en cuenta
Aquí hay algunas cosas a tener en cuenta al usar el código inicial:
- Ejecutar la configuración con solo 8 GB de RAM condujo a respuestas lentas. Para una experiencia más suave, recomiendo 12–16 GB RAM al ejecutar Fuego 3 localmente.
- El maniquí LLAMA3: 8B a menudo devolvió menos que las palabras solicitadas. La salida generada es de menos de 800 palabras.
- Agregue parámetros de paso como
geo,toneytarget audienceen el comando Ejecutar para originar una salida más especificada.
Para aguantar
Acaba de construir una aplicación personalizada con motor LLM en su propia máquina. Lo que hicimos fue usar la Fuego 3 Raw y dar forma a su comportamiento con la ingeniería rápida.
Aquí hay un síntesis rápido:
- Ollama instalado que le permite ejecutar Fuego 3 localmente.
- Tiró el maniquí LLAMA 3 8B para que no confíe en las API externas.
- Escribió indic.py Eso define cómo instruir al maniquí.
- Escribió creador.py Eso actúa como tu mini aplicación.
Al final, ha aprendido un concepto rápido de ingeniería con sus técnicas y experiencia experiencia en el crecimiento de una aplicación alimentada por LLM.
Percibir más:
Preguntas frecuentes
A. LLMS no puede originar la salida explícitamente y, por lo tanto, requiere un indicador que los guíe a comprender qué tarea o información producir.
A. Ingeniería rápida instruye a LLM a comportarse de guisa deducción y efectiva antiguamente de producir la salida. Significa elaborar instrucciones específicas y proporcionadamente definidas para gobernar el LLM en la procreación de la salida deseada.
R. Los cuatro pilares de la ingeniería rápida son la simplicidad (clara y realizable), la especificidad (concisa y específica), la estructura (formato sensato) y la sensibilidad (certamen e imparcial).
R. Sí, la ingeniería rápida es una astucia y de moda. Requiere un pensamiento profundo en la elaboración de indicaciones efectivas que guíen los LLM cerca de los resultados deseados.
R. Los ingenieros de inmediato son profesionales calificados para comprender la entrada (indicaciones) y sobresalir en la creación de indicaciones confiables y robustas, especialmente para modelos de idiomas grandes, para optimizar su rendimiento y asegurar que generen resultados en extremo precisos y creativos.
Soy Bharat Kumar, editor de contenido de la próxima tecnología con más de 3 abriles de experiencia en escritura y tiraje de contenido tecnológico. Actualmente, explorando la IA generativa (Genai) a través de Analytics Vidhya y compartiendo mis aprendizajes escribiendo artículos atractivos e impulsados por la historia sobre inteligencia fabricado, motores generativos y estudios inconsciente.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.