
Implementamos 100 autos controlados por enseñanza de refuerzo (RL) en el tráfico de carreteras de la hora pico para suavizar la congestión y dominar el consumo de combustible para todos. Nuestro objetivo es enfrentarse ondas «detener y ir»esas desaceleraciones y aceleraciones frustrantes que generalmente no tienen una causa clara pero conducen a congestión y sobras de energía significativos. Para entrenar controladores eficientes de suavización de flujo, construimos simulaciones rápidas e impulsadas por datos con las que los agentes de RL interactúan, aprendiendo a maximizar la eficiencia energética mientras mantenemos el rendimiento y operan de guisa segura en torno a de los conductores humanos.
En genérico, una pequeña proporción de vehículos autónomos (AV) acertadamente controlados es suficiente para mejorar significativamente el flujo de tráfico y la eficiencia de combustible para todos los conductores en la carretera. Adicionalmente, los controladores capacitados están diseñados para ser desplegables en la mayoría de los vehículos modernos, operando de guisa descentralizada y dependiendo de los sensores de radar standard. En nuestro postrero gacetaexploramos los desafíos de implementar controladores RL en una gran escalera, desde la simulación hasta el campo, durante este investigación de 100 autos.
Los desafíos de las mermeladas fantasmas

Una ola de detener y tolerar en dirección a a espaldas a través del tráfico de carreteras.
Si conduce, seguramente ha experimentado la frustración de las ondas de parada y van, esas desaceleraciones de tráfico aparentemente inexplicables que aparecen de la nulo y de repente se aclaran. Estas ondas a menudo son causadas por pequeñas fluctuaciones en nuestro comportamiento de conducción que se amplifican a través del flujo del tráfico. Lógicamente, ajustamos nuestra velocidad en función del transporte frente a nosotros. Si se abre la brecha, aceleramos para mantenernos al día. Si frenan, además disminuimos la velocidad. Pero adecuado a nuestro tiempo de reacción dispar de cero, podríamos frenar un poco más duro que el transporte en el frente. El subsiguiente conductor detrás de nosotros hace lo mismo, y esto sigue amplificando. Con el tiempo, lo que comenzó como una desaceleración insignificante se convierte en una parada completa más a espaldas en el tráfico. Estas ondas avanzan en dirección a a espaldas a través de la corriente de tráfico, lo que lleva a caídas significativas en la eficiencia energética adecuado a las aceleraciones frecuentes, acompañadas de un aumento de CO2 emisiones y riesgos de accidentes.
¡Y este no es un engendro eventual! Estas olas son ubicuas en las carreteras ocupadas cuando la densidad de tráfico excede un puertas crítico. Entonces, ¿cómo podemos enfrentarse este problema? Los enfoques tradicionales como la medición de rampas y los límites de velocidad variables intentan cuidar el flujo de tráfico, pero a menudo requieren infraestructura costosa y coordinación centralizada. Un enfoque más escalable es usar AVS, que puede ajustar dinámicamente su comportamiento de conducción en tiempo auténtico. Sin secuestro, simplemente insertar AVS entre los conductores humanos no es suficiente: además deben conducir de una guisa más inteligente que haga que el tráfico sea mejor para todos, que es donde entra RL.
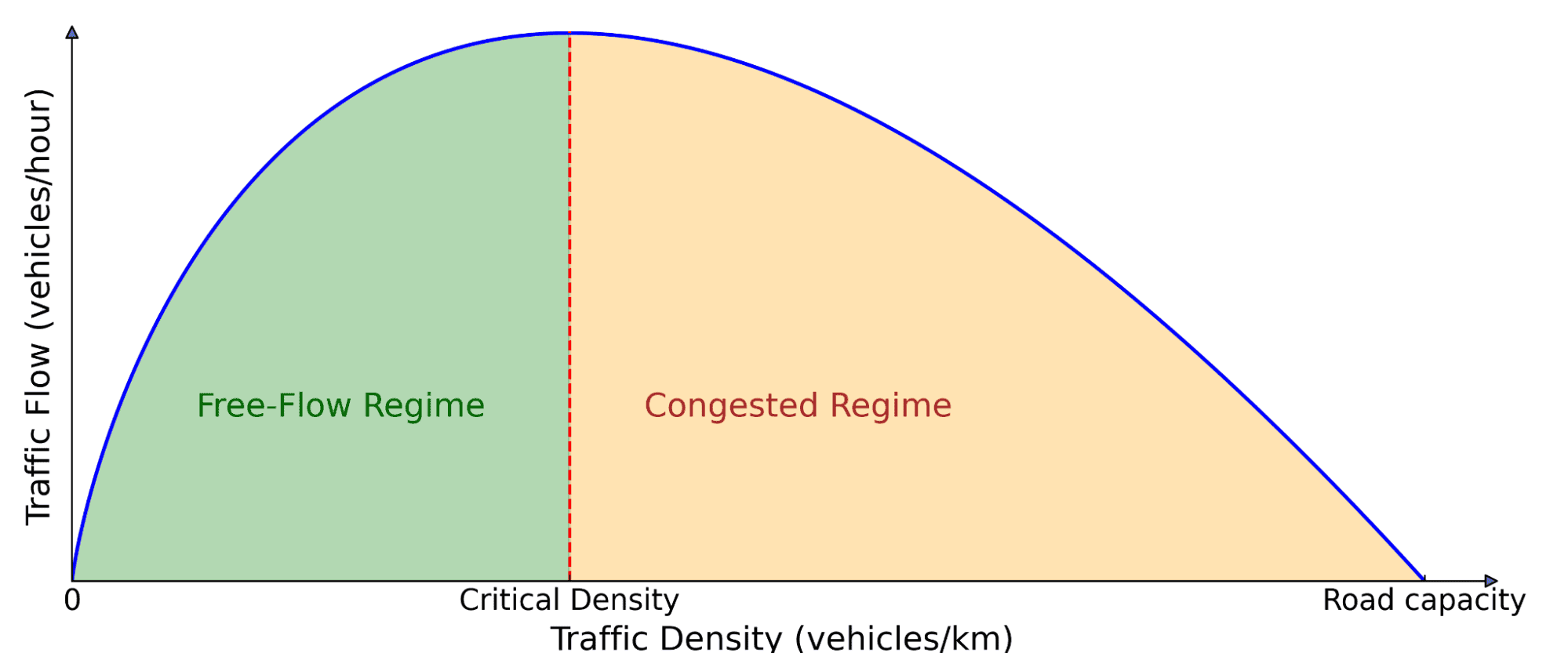
Diagrama fundamental del flujo de tráfico. El número de automóviles en la carretera (densidad) afecta cuánto tráfico avanza (flujo). A pérdida densidad, amplificar más autos aumenta el flujo porque pueden suceder más vehículos. Pero más allá de un puertas crítico, los automóviles comienzan a bloquearse entre sí, lo que lleva a la congestión, donde amplificar más autos verdaderamente ralentiza el movimiento genérico.
Enseñanza de refuerzo para AV con suavización de olas
RL es un poderoso enfoque de control donde un agente aprende a maximizar una señal de remuneración a través de interacciones con un entorno. El agente recopila experiencia a través de prueba y error, aprende de sus errores y alivio con el tiempo. En nuestro caso, el medio esfera es un proscenio de tráfico de autonomía mixta, donde los AVS aprenden estrategias de conducción para disminuir las olas de parada y van y dominar el consumo de combustible tanto para ellos como para vehículos impulsados por los humanos cercanos.
Entrenamiento de estos agentes RL requiere simulaciones rápidas con una dinámica de tráfico realista que puede replicar el comportamiento de parada y salida de la carretera. Para alcanzar esto, aprovechamos los datos experimentales recopilados en la Interestatal 24 (I-24) cerca de Nashville, Tennessee, y los usamos para construir simulaciones donde los vehículos reproducen trayectorias de carreteras, creando un tráfico inestable que los AV que conducen detrás de ellos aprenden a suavizar.
La simulación reproduce una trayectoria de la carretera que exhibe varias ondas de detención y marcha.
Diseñamos los AV con el despliegue en mente, asegurando que puedan actuar utilizando solo información básica del sensor sobre ellos y el transporte en el frente. Las observaciones consisten en la velocidad del AV, la velocidad del transporte líder y la brecha espacial entre ellas. Dadas estas entradas, el agente RL prescribe una apresuramiento instantánea o una velocidad deseada para el AV. La superioridad esencia de usar solo estas mediciones locales es que los controladores RL se pueden implementar en la mayoría de los vehículos modernos de guisa descentralizada, sin requerir infraestructura adicional.
Diseño de recompensas
La parte más desafiante es diseñar una función de remuneración que, cuando se maximice, se alinee con los diferentes objetivos que deseamos que logre los AV:
- Suavizado de ondas: Reduzca las oscilaciones de detener y tolerar.
- Eficiencia energética: Un consumo de combustible más bajo para todos los vehículos, no solo los AV.
- Seguridad: Asegure las siguientes distancias razonables y evite el frenado montañoso.
- Comodidad de conducción: Evite aceleraciones y desaceleraciones agresivas.
- Adhesión a las normas de conducción humana: Asegúrese de que un comportamiento de conducción «común» que no se incomoda a los conductores circundantes.
Equilibrar estos objetivos juntos es difícil, ya que se deben encontrar coeficientes adecuados para cada término. Por ejemplo, si minimizar el consumo de combustible domina la remuneración, RL AVS aprende a detenerse en el medio de la carretera porque eso es magnífico. Para evitar esto, introdujimos los umbrales de brecha insignificante y mayor dinámicos para avalar un comportamiento seguro y bastante al tiempo que optimizamos la eficiencia del combustible. Incluso penalizamos el consumo de combustible de vehículos impulsados por humanos detrás del AV para desalentarlo de ilustrarse un comportamiento egoísta que optimiza el economía de energía para el AV a costas del tráfico circundante. En genérico, nuestro objetivo es alcanzar un invariabilidad entre el economía de energía y tener un comportamiento de conducción bastante y seguro.
Resultados de simulación
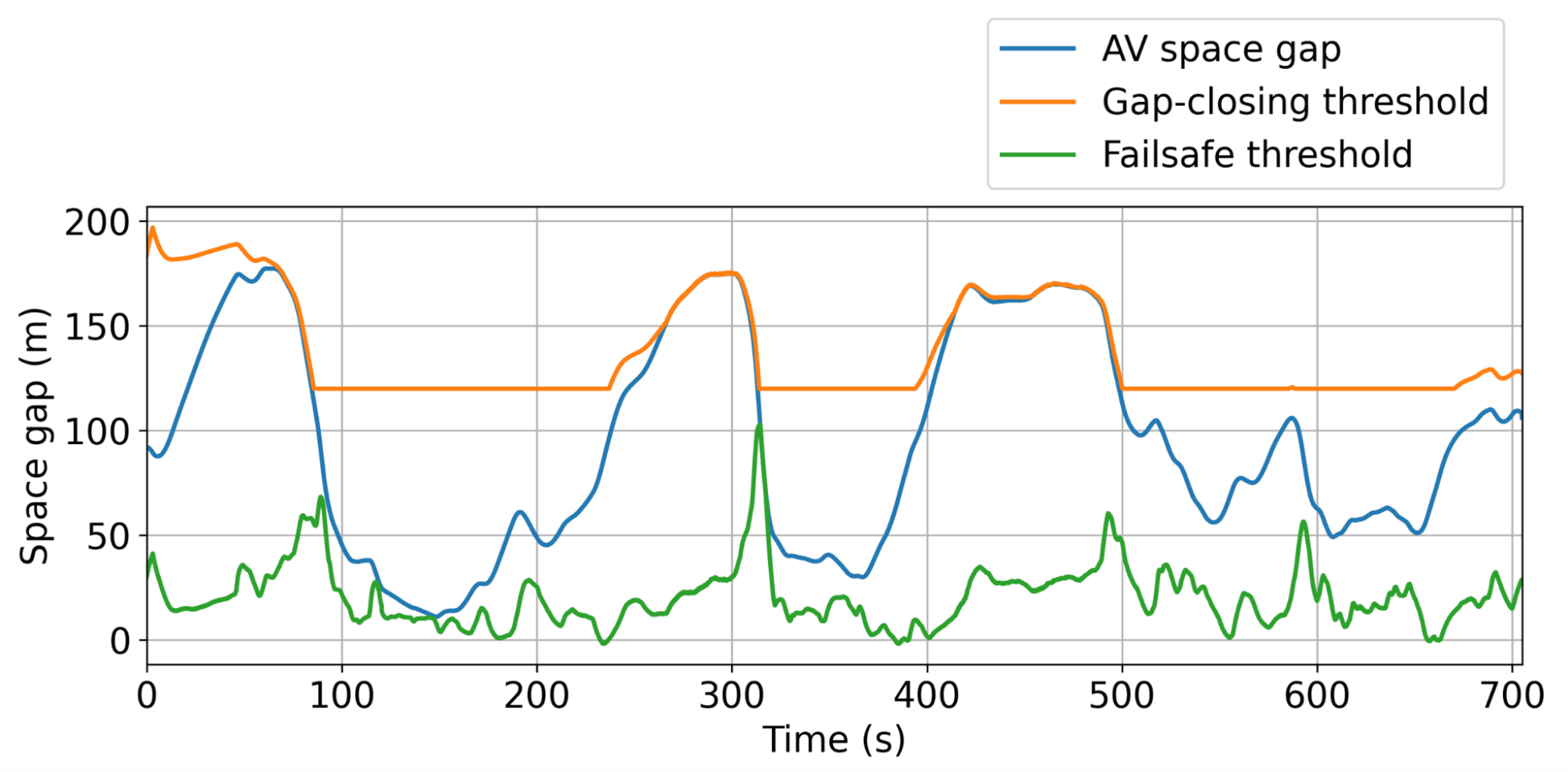
Ilustración de los umbrales de brecha insignificante dinámico y mayor, interiormente de los cuales el AV puede actuar autónomamente para suavizar el tráfico de la guisa más capaz posible.
El comportamiento distintivo aprendido por los AVS es permanecer brechas levemente más grandes que los conductores humanos, lo que les permite absorber la próxima desaceleración del tráfico, posiblemente abrupta, de guisa más efectiva. En la simulación, este enfoque resultó en un economía significativo de combustible de hasta el 20% en todos los usuarios de la carretera en los escenarios más congestionados, con menos del 5% de los AV en la carretera. ¡Y estos AV no tienen que ser vehículos especiales! Simplemente pueden ser autos de consumo standard equipados con un control de crucero adaptativo inteligente (ACC), que es lo que probamos a escalera.
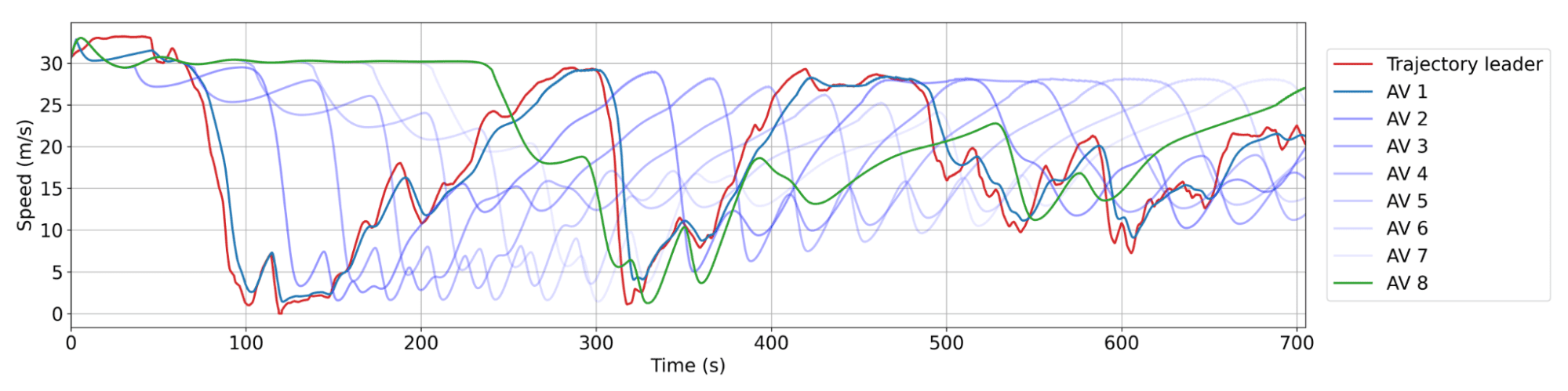
Comportamiento de suavizado de RL AV. Rojo: una trayectoria humana del conjunto de datos. Celeste: AV sucesivos en el pelotón, donde AV 1 es el más cercano detrás de la trayectoria humana. Típicamente hay entre 20 y 25 vehículos humanos entre AV. Cada AV no se ralentiza tanto o se acelera tan rápido como su líder, lo que lleva a disminuir la amplitud de las olas con el tiempo y, por lo tanto, ahorros de energía.
100 prueba de campo AV: implementar RL a escalera


Nuestros 100 autos estacionados en nuestro centro activo durante la semana del investigación.
Dados los prometedores resultados de la simulación, el subsiguiente paso natural fue cerrar la brecha de la simulación a la carretera. Tomamos los controladores RL capacitados y los desplegamos en 100 vehículos en el I-24 durante las horas pico de tráfico durante varios días. Este investigación a gran escalera, que llamamos Megavandertest, es el investigación de suavización de tráfico de autonomía mixta más espacioso nones realizado.
Ayer de implementar controladores RL en el campo, los entrenamos y evaluamos ampliamente en simulación y los validamos en el hardware. En genérico, los pasos en dirección a el despliegue involucrado:
- Capacitación en simulaciones basadas en datos: Utilizamos datos de tráfico de carreteras de la I-24 para crear un entorno de capacitación con dinámica de olas realista, luego validar el rendimiento y la robustez del agente capacitado en una variedad de nuevos escenarios de tráfico.
- Implementación en hardware: Luego de ser validado en el software de robótica, el compensador capacitado se carga en el automóvil y puede controlar la velocidad establecida del transporte. Operamos a través del control de crucero a borde del transporte, que actúa como un compensador de seguridad de nivel inferior.
- Ámbito de control modular: Un desafío esencia durante la prueba fue no tener ataque a los principales sensores de información del transporte. Para exceder esto, el compensador RL se integró en un sistema jerárquico, el Megacontroller, que combina una vademécum de planificador de velocidad que explica las condiciones de tráfico posterior, con el compensador RL como el tomador de decisiones final.
- Firmeza en hardware: Los agentes de RL fueron diseñados para actuar en un entorno donde la mayoría de los vehículos fueron impulsados por los humanos, lo que requería políticas sólidas que se adapten al comportamiento impredecible. Verificamos esto conduciendo los vehículos controlados por RL en la carretera bajo una cuidadosa supervisión humana, haciendo cambios en el control basado en la feedback.

Cada uno de los 100 autos está conectado a una Raspberry Pi, en la que se implementa el compensador RL (una pequeña red neuronal).
El compensador RL controla directamente el sistema de control de crucero adaptativo (ACC) a borde, estableciendo su velocidad y deseada posteriormente de la distancia.
Una vez validados, los controladores RL se desplegaron en 100 autos y conducían en la I-24 durante la hora pico de la mañana. El tráfico circundante desconocía el investigación, asegurando el comportamiento imparcial del conductor. Los datos se recopilaron durante el investigación de docenas de cámaras superiores colocadas a lo dispendioso de la carretera, lo que condujo a la linaje de millones de trayectorias de vehículos individuales a través de una tubería de visión por computadora. Las métricas calculadas en estas trayectorias indican una tendencia de un consumo de combustible corto en torno a de los AV, como se esperaba de los resultados de la simulación y las implementaciones de acometividad más pequeñas anteriores. Por ejemplo, podemos observar que cuanto más cercanas conducen detrás de nuestros AV, menos combustible parecen consumir en promedio (que se calcula utilizando un maniquí de energía calibrado):
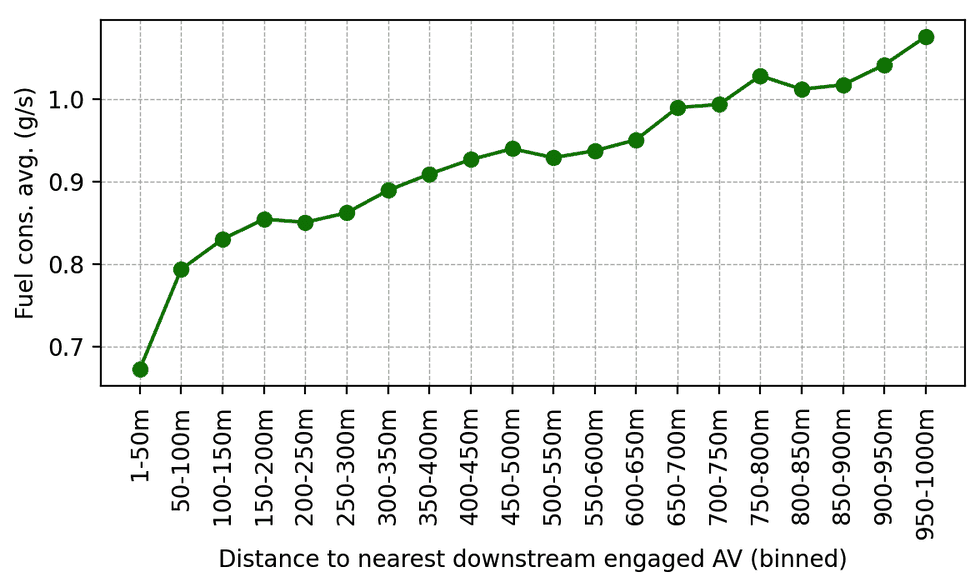
Consumo promedio de combustible en función de la distancia detrás del AV controlado por RL comprometido más cercano en el tráfico posterior. A medida que los conductores humanos se alejan más detrás de los AV, su consumo promedio de combustible aumenta.
Otra forma de calibrar el impacto es calibrar la varianza de las velocidades y aceleraciones: cuanto pequeño sea la varianza, menos amplitud deben tener las ondas, que es lo que observamos a los datos de la prueba de campo. En genérico, aunque obtener mediciones precisas de una gran cantidad de datos de video de la cámara es complicada, observamos una tendencia del 15 al 20% de los ahorros de energía en torno a de nuestros automóviles controlados.
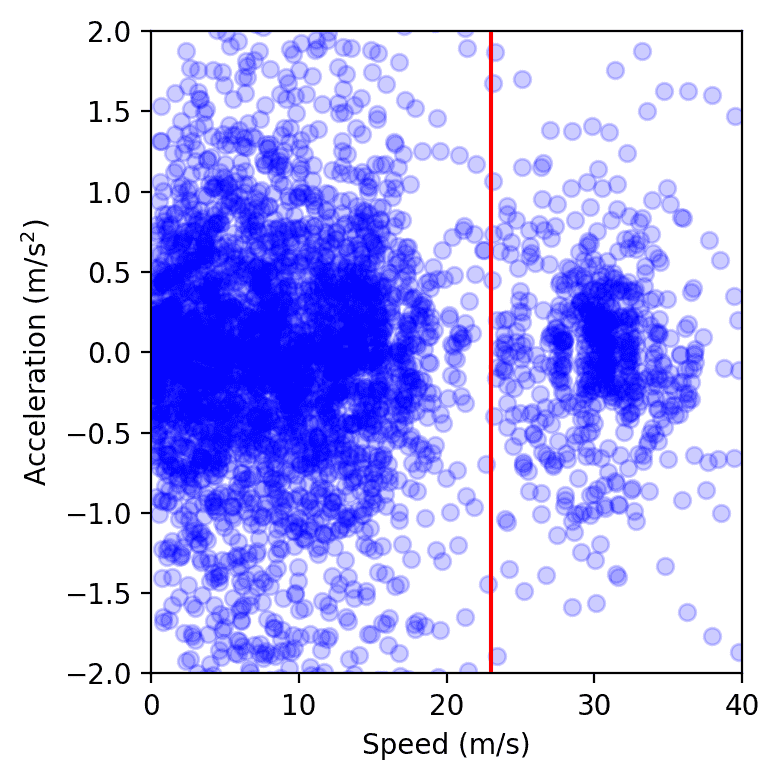
Puntos de datos de todos los vehículos en la carretera durante un solo día del investigación, trazado en el espacio de apresuramiento de velocidad. El clúster a la izquierda de la secante roja representa la congestión, mientras que el de la derecha corresponde al flujo franco. Observamos que el clúster de congestión es más pequeño cuando están presentes los AV, según lo medido calculando el radio de una cubierta convexa suave o ajustando un núcleo gaussiano.
Pensamientos finales
La prueba operativa de campo de 100 autos fue descentralizada, sin cooperación o comunicación explícita entre los AV, un reflexiva del despliegue de autonomía contemporáneo y nos acercó un paso más cerca de carreteras más suaves y eficientes en energía. Sin secuestro, todavía existe un gran potencial de alivio. La ampliación de las simulaciones para ser más rápidas y más precisas con mejores modelos de conducción humana es crucial para cerrar la brecha de simulación a verdad. Equipar AVS con datos de tráfico adicionales, ya sea a través de sensores avanzados o planificación centralizada, podría mejorar aún más el rendimiento de los controladores. Por ejemplo, si acertadamente RL de múltiples agentes es prometedor para mejorar las estrategias de control cooperativo, sigue siendo una pregunta abierta cómo habilitar la comunicación explícita entre las AVS a través de las redes 5G podría mejorar aún más la estabilidad y mitigar aún más las ondas de detención y marcha. De guisa crucial, nuestros controladores se integran perfectamente con los sistemas de control de crucero adaptativo (ACC) existentes, lo que hace que la implementación de campo sea factible a escalera. Cuantos más vehículos equipados con control inteligente de suavización de tráfico, ¡menos olas veremos en nuestras carreteras, lo que significa menos contaminación y economía de combustible para todos!
¡Muchos contribuyentes participaron en hacer que el Megavandertest suceda! La repertorio completa está acondicionado en el Plan de círculos página, anejo con más detalles sobre el esquema.
Repasar más: (papel)