
En las dos décadas transcurridas desde la finalización del primer croquis del genoma humano, el panorama de la investigación biológica ha experimentado una transformación revolucionaria. El campo de la genómica se ha expandido exponencialmente, dando extensión a una revolución «ómica» más amplia, que albarca diversos tipos de datos, como la secuenciación de ARN unicelular, la proteómica y la metabolómica, por nombrar algunos.
Estas tecnologías de vanguardia están proporcionando conocimientos sin precedentes en funciones biológicas al nivel más granular, ofreciendo una comprensión más profunda de los mecanismos de las enfermedades, las adaptaciones del organismo y las interacciones con factores ambientales, incluidos medicamentos y productos químicos. Las implicaciones de esta crisis ómica son de gran magnitud y prometen revolucionar descubrimiento de drogas, medicina de precisión, agriculturay biofabricación.
Sin confiscación, la mayoría de las organizaciones de ciencias biológicas luchan por desbloquear plenamente estos conocimientos, conveniente a una variedad de desafíos planteados por la infraestructura de datos existente y las tecnologías utilizadas. Para aventajar estos desafíos, modernizar las plataformas de datos es crucial para la aplicación exitosa de las multiómicas en la investigación y el progreso.
En este blog exploramos cómo las nuevas tecnologías, como Databricks Data Intelligence Platform, pueden tocar estos problemas, allanando el camino para una gobierno de datos multiómica más eficaz y apto.
La mayoría de las organizaciones tienen dificultades para disfrutar estos datos conveniente a la inmueble heredada.
Las infraestructuras de datos heredadas luchan por tramitar las complejidades de los datos multiómicos, particularmente al proporcionar una alternativa escalable para la integración de datos y el exploración de estos conjuntos de datos masivos. Adicionalmente, carecen de soporte nativo para exploración avanzados y la creciente demanda de IA.
Problemas como la interoperabilidad, accesibilidad y reutilización de los datos son comunes, exacerbados por la error de estandarización entre plataformas ómicas aisladas. Para hacer esto aún más confuso, las organizaciones deben equilibrar la accesibilidad de los datos con la privacidad del paciente y el cumplimiento normativo en un entorno en extremo regulado.
Desafíos esencia de datos que enfrentan las organizaciones de ciencias biológicas
¿Cómo están abordando actualmente las organizaciones estos problemas? Hoy en día, la mayoría emplea una variedad de tecnologías simultáneamente para manejar datos ómicos. Esta organización, sin confiscación, presenta varios desafíos, entre ellos:
Cuerpo y complejidad de datos
Los datos ómicos son vastos y muy complejos, y requieren métodos computacionales avanzados para su exploración. Por ejemplo, con el auge de las tecnologías avanzadas Métodos de enseñanza profundo para la integración de datos multiómicos.la ingreso dimensionalidad de estos conjuntos de datos puede introducir un «ruido» significativo, lo que dificulta la elaboración de información útil. En particular, el problema de ingreso dimensión y bajo tamaño de muestra (HDLSS) es un desafío en la investigación ómica, donde el peligro de sobreajuste en los modelos de enseñanza mecánico (ML) puede compendiar la propagación de los hallazgos. Enfrentarse este problema requiere un preprocesamiento de datos sólido y técnicas computacionales avanzadas, que muchas infraestructuras de datos heredadas no están diseñadas para manejar.
Estandarización e interoperabilidad
La desaparición de estándares comunes entre las diferentes plataformas ómicas presenta desafíos importantes para asegurar la interoperabilidad y reutilización de los datos. Sin protocolos estandarizados, integrar diversos conjuntos de datos en un entorno cohesivo se convierte en una tarea ardua.
Consideraciones regulatorias
Respaldar que los datos ómicos sean accesibles manteniendo la privacidad del paciente y cumpliendo con regulaciones como HIPAA y GDPR es un acto de consistencia confuso. Este desafío se acentúa en un entorno de investigación integral donde Los datos a menudo se comparten entre diferentes jurisdicciones.. Adicionalmente, a medida que se utilizan más datos genéticos en entornos de diagnosis o para entrenamiento de modelos de enseñanza mecánico Para predecir el peligro de enfermedades (como la puntuación del peligro poligénico), la capacidad de realizar un seguimiento de todos los aspectos del proceso de capacitación, desde la adquisición de datos y el control de calidad hasta la capacitación del maniquí y la explicabilidad, se ha vuelto cada vez más crítica.
Experiencia de sucesor
La industria farmacéutica se beneficia del entrada a una amplia variedad de profesionales, incluidos especialistas en TI, científicos de datos, investigadores médicos y científicos de laboratorio que realizan experimentos complejos con diversas muestras biológicas. La mayoría de las plataformas de datos existentes, construidas sobre diferentes tecnologías (que abarcan la computación de detención rendimiento (HPC), los almacenes de datos tradicionales y diferentes servicios nativos en la nimbo) requieren un mantenimiento técnico significativo para adaptarse al panorama en rápida crecimiento de los datos ómicos.
Adicionalmente, el entrada a conocimientos por parte de miembros del equipo no técnicos con conocimiento del dominio se ve obstaculizado conveniente a la complejidad de estos sistemas y la pronunciada curva de enseñanza asociada con su uso. Este desafío crea una barrera importante para la colaboración eficaz y la toma de decisiones basada en datos interiormente de las organizaciones de ciencias biológicas.
Aumento de las aplicaciones GenAI
Entrenamiento de nuevos modelos básicos utilizando datos multiómicos está revolucionando la investigación biomédica y descubrimiento de fármacos. Por ejemplo, con el auge de los datos ómicos unicelulares, modelos como scGPT y formador de genes disfrutar conjuntos de datos multiómicos a gran escalera para predecir respuestas a fármacos e identificar nuevos objetivos terapéuticos, impulsando avances en la medicina personalizada. Empresas como Escalera Evolutiva y Profulent.bio han entrenado modelos de lengua ilustre (LLM) para suscitar nuevas proteínas sintéticas basadas en datos multiómicos. Sin confiscación, poner en destreza estos modelos presenta desafíos importantes, particularmente en términos de eficiencia y rentabilidad de la capacitación. Las demandas computacionales del procesamiento de grandes conjuntos de datos requieren una infraestructura avanzadilla, que pueda manejar tanto la gobierno de datos como el entrenamiento rentable de modelos tan grandes en cantidades masivas de datos multimodales.
Presentamos la plataforma de inteligencia de datos Databricks para Omics
La plataforma Databricks Data Intelligence ofrece una colchoneta poderosa para una plataforma de datos multiómicos, que aborda de forma efectiva las complejidades que encuentran los investigadores y profesionales de TI al gobernar datos ómicos. Así es como Databricks puede ayudar a aventajar cada uno de los desafíos esencia:

Cuerpo y complejidad de datos
Databricks se sostén en una infraestructura de nimbo escalable que puede manejar los vastos y complejos conjuntos de datos típicos de la investigación ómica. Con su integración con Apache Spark y un motor informático de detención rendimiento impulsado por FotónDatabricks permite un procesamiento de datos distribuido rentable. Adicionalmente, al tener la Pila de enseñanza mecánico/IA construida sobre una potente infraestructura de gobierno de datosreduce la fricción de gobernar pilas de tecnología separadas para la gobierno de datos y el exploración innovador, al tiempo que acelera el tiempo de vivientes de valía.
El motor Databricks Photon proporciona un impulso significativo a las herramientas y canalizaciones genómicas basadas en Spark, como Resplandor del tesinaacelerando y simplificando el exploración de grandes conjuntos de datos genómicos, particularmente para la identificación de objetivos genéticos mediante estudios de asociación de todo el genoma (GWAS).
Estandarización e interoperabilidad
La inmueble de la casa del laguna de Databricks permite una interoperabilidad perfecta mediante la integración de datos estructurados, semiestructurados y no estructurados de lagos y almacenes de datos en una plataforma única y unificada basada en tecnologías de código despejado como laguna delta y Catálogo de pelotón. Este enfoque facilita la integración de diversos conjuntos de datos, admitiendo formatos e interfaces de datos abiertos para compendiar la dependencia de proveedores y simplificar la integración de datos entre diferentes sistemas.
Al disfrutar las tecnologías de código despejado y proporcionar un catálogo de datos centralizado, Catálogo de pelotónDatabricks garantiza que los datos sean fácilmente detectables, accesibles y puedan integrarse con sistemas externos de forma compatible y auditable. Esto permite a los investigadores cumplir con los Principios JUSTOS (Encontrabilidad, Accesibilidad, Interoperabilidad y Reutilización) para la gobierno de datos científicos, promoviendo la colaboración, la reproducibilidad y el conocimiento basado en datos.
Consideraciones regulatorias
Databricks Unity Catalog permite a las organizaciones cumplir con requisitos normativos estrictos, como HIPAA y GDPR, al tiempo que mejoramiento la capacidad de búsqueda y accesibilidad de los datos. Con su repositorio centralizado de metadatos y potentes capacidades de búsqueda semánticalos usuarios pueden encontrar rápidamente activos de datos relevantes según el contexto y el significado. la plataforma controles de entrada detallados, convenio de identidady completo registro de auditoría asegurar la seguridad y el cumplimiento de los datos.
Adicionalmente, Unity Catalog proporciona gobierno avanzadilla de metadatos, etiquetado y seguimiento del clase de datos para mejorar la capacidad de descubrimiento y reproducibilidad de los experimentos. Para asegurar aún más el cumplimiento normativo, Databricks ofrece una sólida criptográfico de datos y funciones de gobierno secreta. La plataforma asimismo integra tecnologías de código despejado, como la Protocolo de intercambio deltaque permite compartir datos de forma segura entre las partes. Salas limpias de ladrillos de datos facilita la colaboración segura entre investigadores de diferentes organizaciones y al mismo tiempo cumple con los requisitos de residencia de datos.
En conjunto, estas capacidades permiten a las organizaciones sustentar estrictos estándares de protección de datos y, al mismo tiempo, permiten a los usuarios autorizados descubrir, conseguir y compartir de forma apto los datos necesarios para el exploración y la investigación en un entorno seguro y compatible, incluso a través de los límites organizacionales.
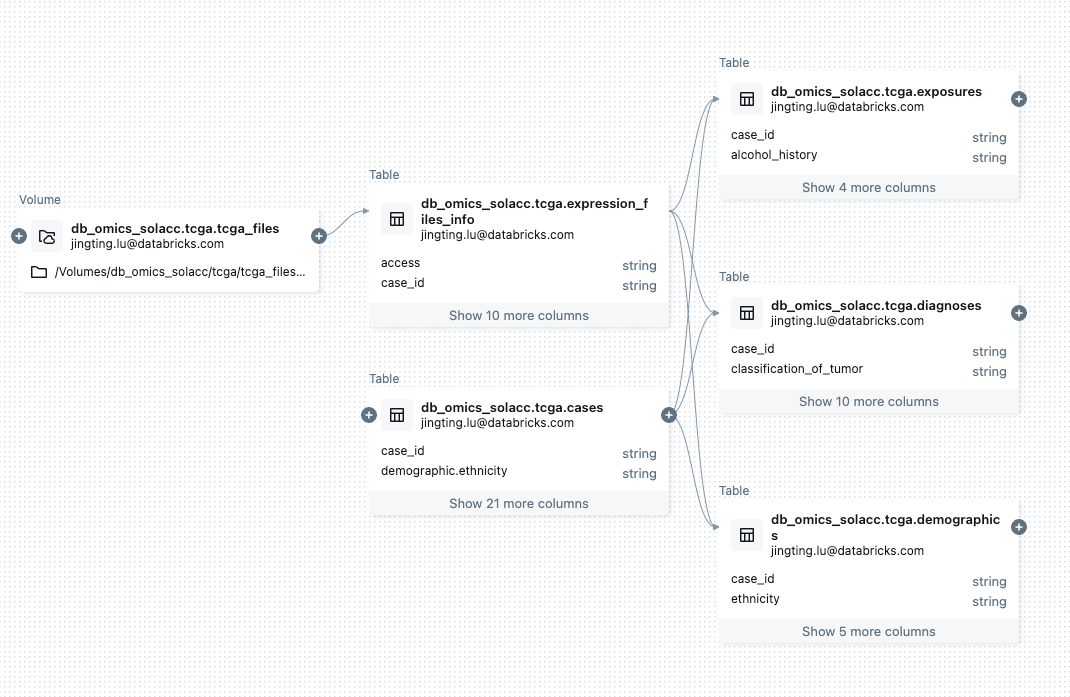
Experiencia de sucesor
Databricks ofrece una plataforma de datos integral de hipermercado que simplifica la oficina de la infraestructura e integra varios tipos de datos. Sus interfaces fáciles de usar, que incluyen consulta en lengua natural y subsidio basada en IA sensible al contextopermiten un entrada y exploración de datos sencillos. Este enfoque desmitifica las interacciones de datos, haciendo que la plataforma sea accesible no solo para usuarios técnicos sino asimismo para expertos en el dominio sin experiencia técnica.
Al simplificar el entrada a los datos y compendiar los gastos generales de TI y al mismo tiempo mejorar la colaboración entre diferentes equipos, Databricks acelera la toma de decisiones y la innovación en el descubrimiento y progreso de fármacos.
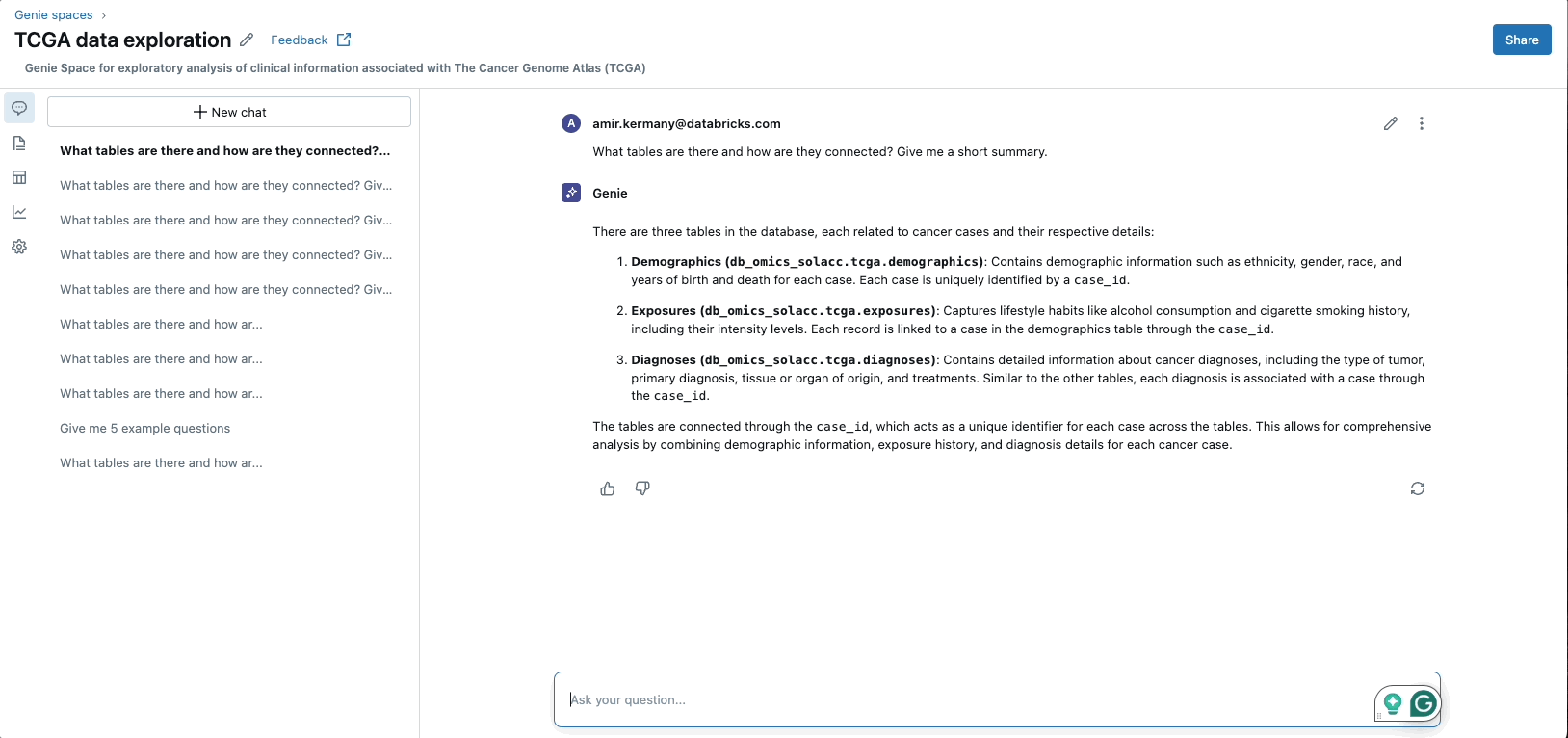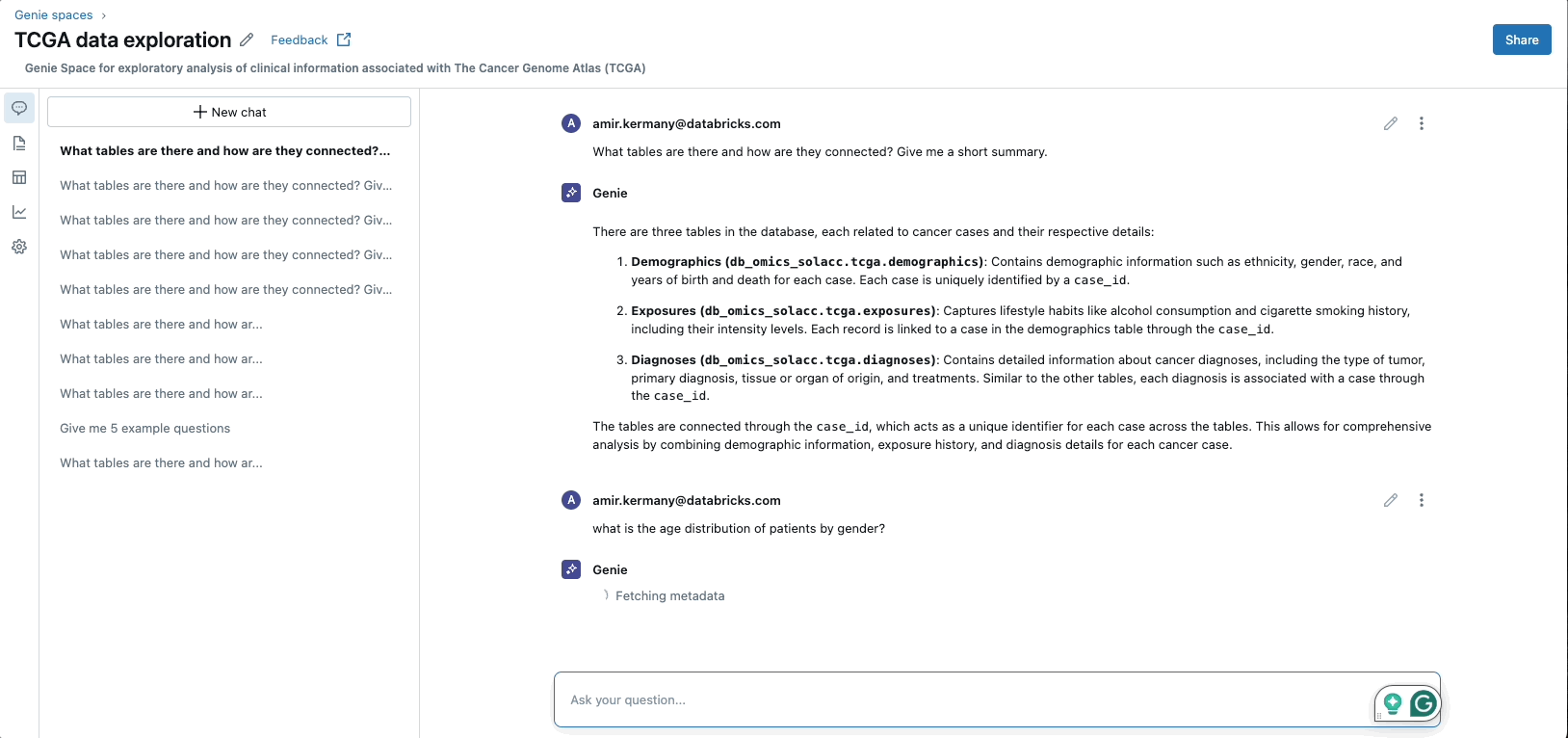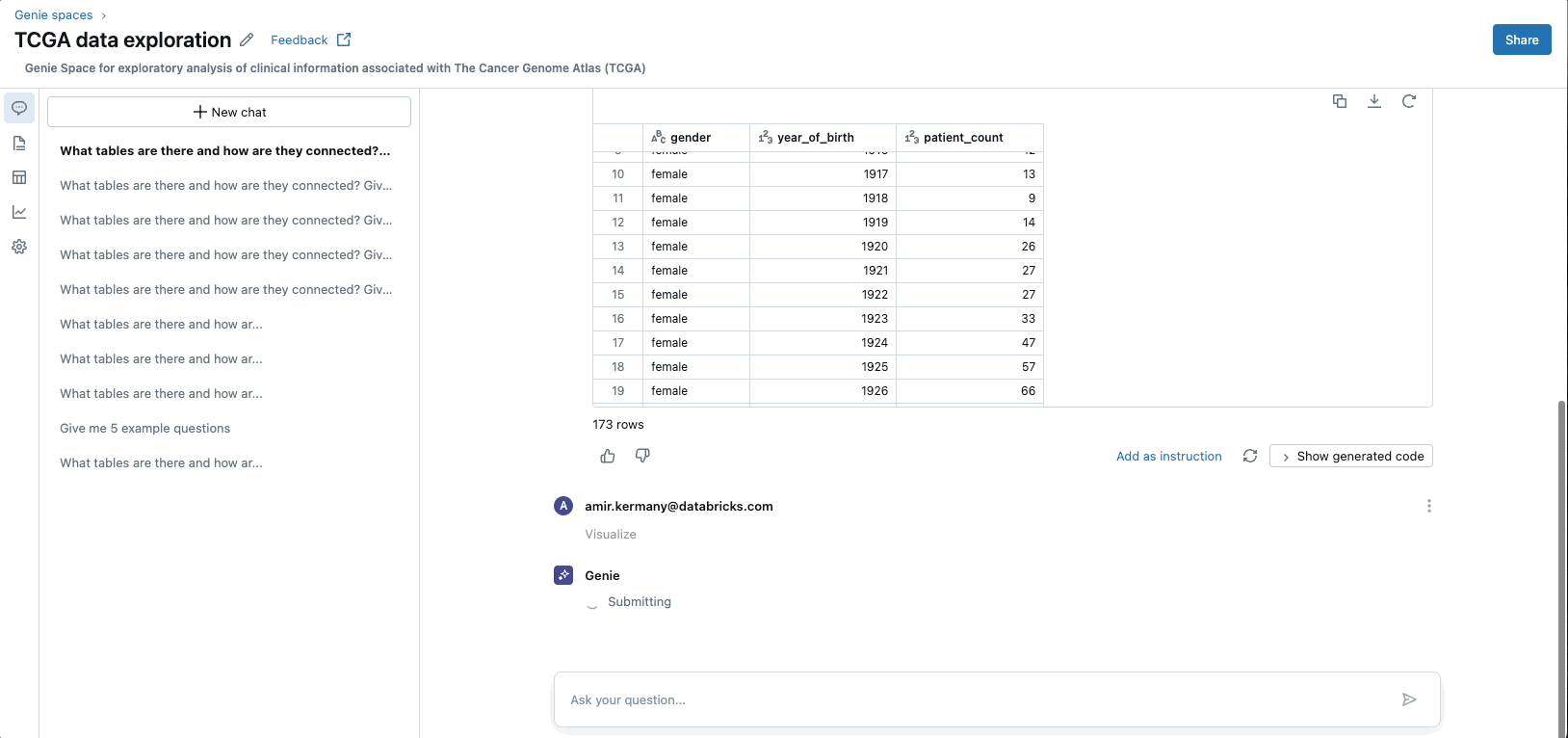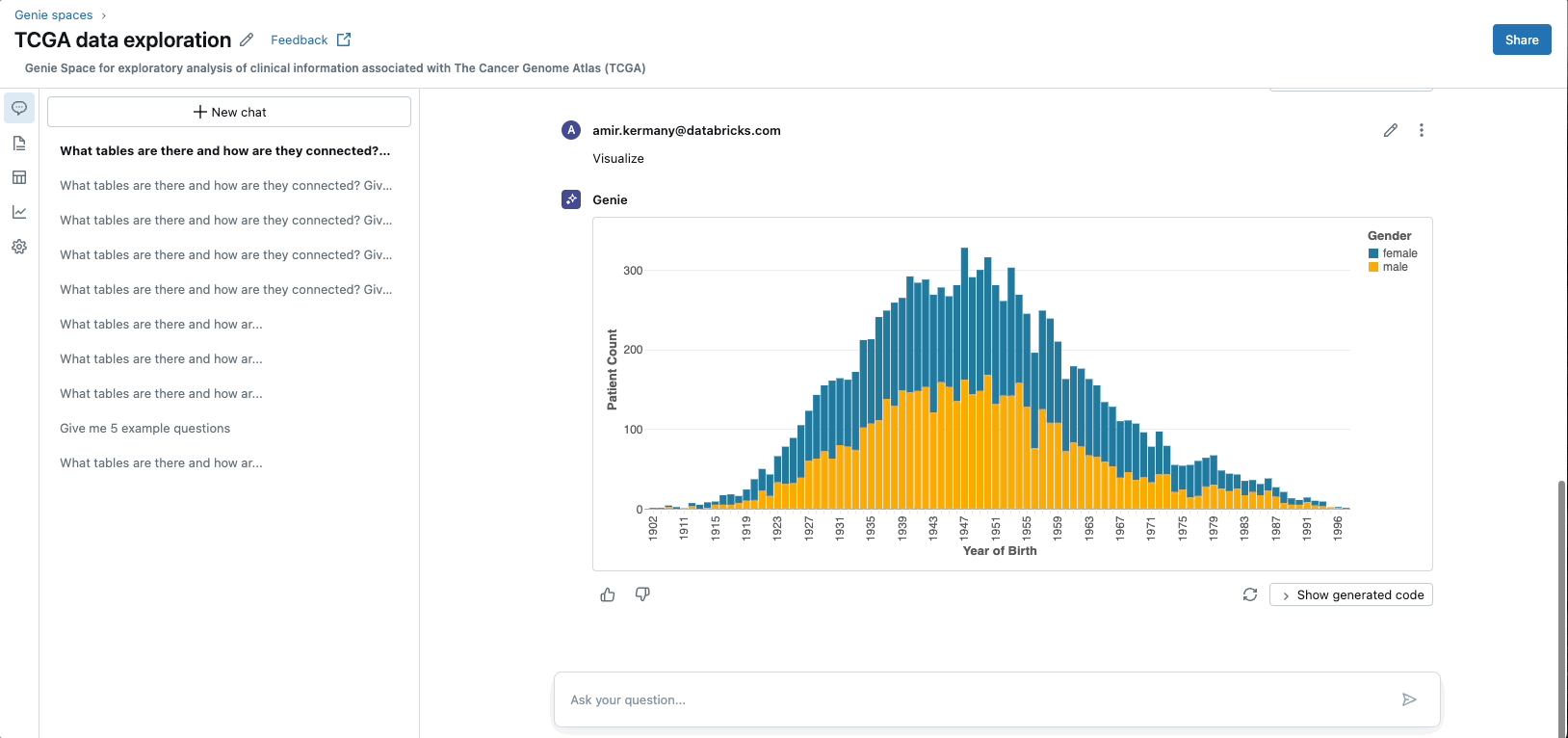
Aumento de las aplicaciones GenAI
Ladrillos de datos MosaicoAI La plataforma permite el entrenamiento previo, el ajuste y la implementación de modelos de IA generativa al proporcionar una infraestructura computacional escalable y segura. Con MosaicAI, Databricks ofrece soluciones diseñadas específicamente para la capacitación rentable de modelos básicos en conjuntos de datos propietarios de una estructura. Adicionalmente, MosaicAI ofrece ingreso escalabilidad búsqueda vectorial y un Entorno del agente de IA para la construcción sistemas compuestos de IAadyacente con LLMOps/MLOps capacidades para tramitar todo el ciclo de vida de los modelos de IA.
Esto garantiza que se pongan en funcionamiento de forma efectiva, apto y a escalera, lo que permite a las organizaciones desbloquear todo el potencial de la IA generativa e impulsar el valía empresarial de sus inversiones en IA.
Mirando en torno a delante
En los próximos blogs técnicos, exploraremos el uso de tecnologías Databricks para multiómicas. Esto incluirá la ejecución de estudios de asociación de todo el genoma y el entrenamiento previo del maniquí elemental Geneformer con MosaicAI.
En recopilación, Databricks ofrece una plataforma integral que aborda los diversos desafíos de la gobierno de datos ómicos. Con su infraestructura escalable, compatibilidad con la interoperabilidad, sólidas funciones de seguridad y capacidades avanzadas de inteligencia sintético, Databricks permite a las empresas farmacéuticas extraer información destreza de conjuntos de datos ómicos complejos. Al utilizar Databricks, las organizaciones pueden acelerar sus esfuerzos de investigación y progreso (I+D), lo que genera innovación y mejores resultados para los pacientes.
Más información sobre nuestras soluciones de datos e inteligencia sintético para la atención médica y las ciencias biológicas.