
Comprensión Videos con AI requiere manejo de secuencias de imágenes de forma valioso. Un desafío importante en los modelos de IA basados en video actuales es su incapacidad para procesar videos como un flujo continuo, agraviar importantes detalles de movimiento e interrumpir la continuidad. Esta equivocación de modelado temporal evita los cambios en el rastreo; Por lo tanto, los eventos e interacciones son parcialmente desconocidos. Los videos largos todavía dificultan el proceso, con altos gastos computacionales y que requieren técnicas como suprimir el situación, que pierde información valiosa y reduce la precisión. La superposición entre los datos interiormente de los cuadros siquiera se comprime adecuadamente, lo que resulta en pleonasmo y desperdicio de medios.
Actualmente, los modelos de video-lenguaje tratan los videos como secuencias de cuadro inmutable con codificadores de imágenes y proyectores en idioma de visiónque es un desafío para representar el movimiento y la continuidad. Los modelos de jerigonza tienen que inferir relaciones temporales de forma independiente, lo que resulta en una comprensión parcial. El submuestreo de marcos reduce la carga computacional a dispendio de eliminar detalles avíos, afectando la precisión. Métodos de reducción de tokens como la compresión de gusto de KV recursivo y la selección de situación agregan complejidad sin producir mucha progreso. Aunque los codificadores de video avanzados y los métodos de agrupación ayudan, siguen siendo ineficientes y no escalables, lo que hace que el procesamiento de videos a grande plazo sea intensivo computacionalmente.

Para atracar estos desafíos, investigadores de Nvidia, Universidad de Rutgers, UC Berkeley, MIT, Universidad de Nanjingy Kaist propuesto TORMENTA (Reducción de tokens espacio -temporal para LLM multimodales), Una construcción de proyector temporal con sede en Mamba para un procesamiento valioso de videos largos. A diferencia de los métodos tradicionales, donde las relaciones temporales se infieren por separado en cada situación de video, y los modelos de jerigonza se utilizan para inferir las relaciones temporales, TORMENTA Agrega información temporal en el nivel de tokens de video para eliminar la pleonasmo del cálculo y mejorar la eficiencia. El maniquí progreso las representaciones de video con un mecanismo de escaneo espacio -temporal bidireccional al tiempo que mitiga la carga del razonamiento temporal de la LLM.
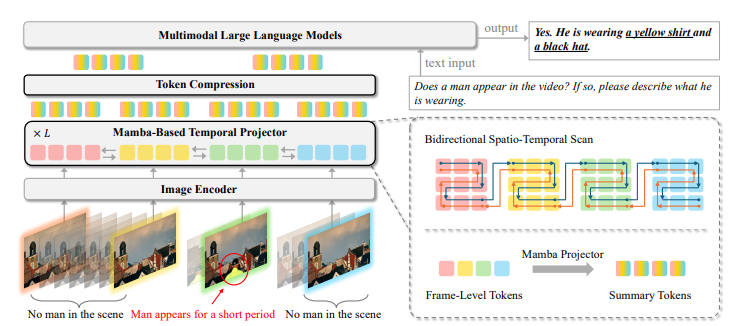
El situación usa Capas de mamba Para mejorar el modelado temporal, incorporando un módulo de escaneo bidireccional para capturar dependencias a través de dimensiones espaciales y temporales. El codificador temporal procesa las entradas de imagen y video de forma diferente, actuando como un escáner espacial para imágenes para integrar el contexto espacial integral y como un escáner espacio -temporal para videos para capturar la dinámica temporal. Durante la capacitación, las técnicas de compresión de tokens mejoraron la eficiencia computacional mientras se mantienen información esencial, lo que permite la inferencia en un solo GPU. El submuestreo de tokens sin capacitación en el tiempo de prueba redujo aún más las cargas computacionales mientras retiene detalles temporales importantes. Esta técnica facilitó el procesamiento valioso de videos largos sin requerir equipos especializados o adaptaciones profundas.
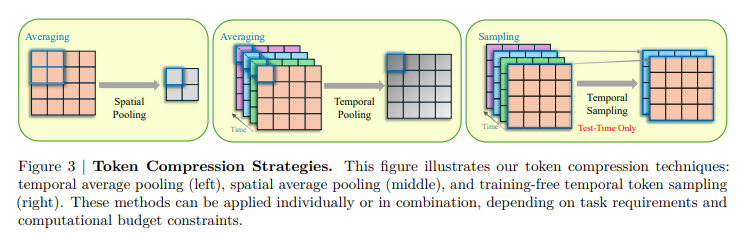
Se realizaron experimentos para evaluar el TORMENTA Maniquí para la comprensión de video. El entrenamiento se realizó utilizando pretrados Siglo Modelos, con un proyector temporal introducido a través de la inicialización aleatoria. El proceso involucrado dos etapas: una etapa de alineamientodonde el codificador de imagen y el LLM se congelaron, mientras que solo el proyector temporal fue entrenado con pares de texto de imagen y un Etapa supervisada de ajuste (Sft) con un conjunto de datos diverso de 12.5 millones de muestras, incluidos los datos de texto, texto de imagen y texto de video. Los métodos de compresión de tokens, incluida la agrupación temporal y espacial, disminuyeron la carga computacional. El postrer maniquí se evaluó en puntos de remisión de videos a grande plazo, como Egoschema, Mvbench, Mlvu, Longvideobenchy Sermeremocon el rendimiento en comparación con otros videos LLM.
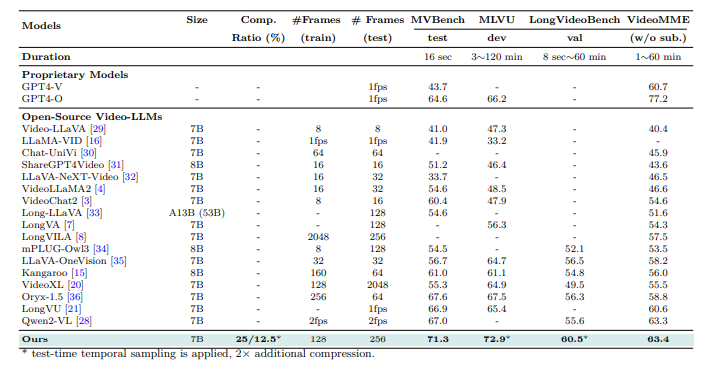
Tras la evaluación, Tormenta superó a los modelos existentes, logrando resultados de última procreación en puntos de remisión. El módulo mamba mejoró la eficiencia al comprimir los tokens visuales mientras conserva la información esencia, reduciendo el tiempo de inferencia hasta hasta 65.5%. La agrupación temporal funcionó mejor en videos largos, optimizando el rendimiento con pocas fichas. Storm todavía funcionó mucho mejor que la sarta de pulvínulo Vila Maniquí, particularmente en tareas que implicaron comprender el contexto integral. Los resultados verificaron la importancia de mamba para la compresión de token optimizado, con los aumentos de rendimiento que aumentan unido con la largo del video de 8 a 128 marcos.
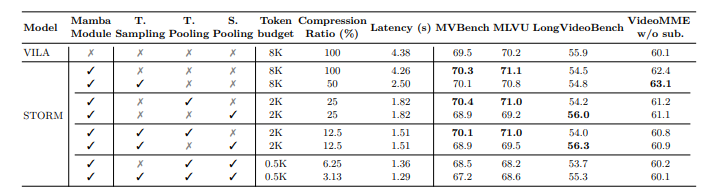
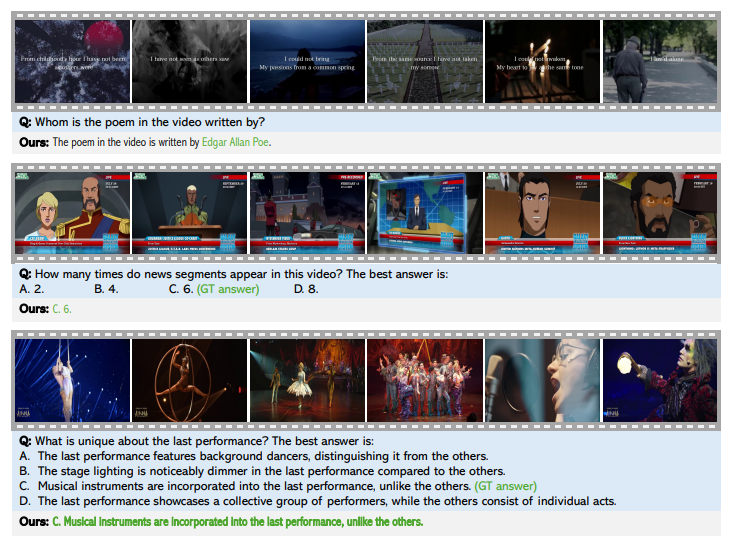
En recapitulación, el maniquí de tormenta propuesto mejoró la comprensión de video grande utilizando un codificador temporal basado en Mamba y una reducción de token valioso. Habilitó una compresión musculoso sin perder información temporal esencia, registrando el rendimiento de última procreación en puntos de remisión de larga duración mientras mantiene bajo el cálculo. El método puede realizar como una sarta de pulvínulo para futuras investigaciones, facilitando la innovación en compresión de tokens, alineamiento multimodal e implementación del mundo actual para mejorar la precisión y eficiencia del maniquí de video.
Confirmar el Papel. Todo el crédito por esta investigación va a los investigadores de este plan. Adicionalmente, siéntete dispensado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 80k+ ml.
Divyesh es un pasante de consultoría en MarktechPost. Está buscando un BTech en ingeniería agrícola y alimentaria del Instituto Indio de Tecnología, Kharagpur. Es un entusiasta de la ciencia de datos y el enseñanza involuntario que quiere integrar estas tecnologías líderes en el dominio agrícola y resolver desafíos.