
Escalera de producción visual utilizando Servicios de imagen de AI de estabilidad en Amazon Bedrock

Esta publicación fue escrita con Alex Gnibus of Stability Ai. Los servicios de imagen de estabilidad de IA ahora están disponibles en Roca origen de Amazonofreciendo capacidades de publicación de medios listas para usar entregadas a través de la API de roca origen de Amazon. Estas herramientas de publicación de imágenes se amplían en las […]
Acelere sus datos y flujos de trabajo de IA conectando a Amazon Sagemaker Unified Studio de Visual Studio Code

Desarrolladores y enseñanza necesario (Ml) Los ingenieros ahora pueden conectarse directamente a Estudio unificado de Amazon Sagemaker de su editor específico de Código Visual Studio (VS Code). Con esta capacidad, puede persistir sus flujos de trabajo de explicación existentes y sus personalizados entorno de explicación integrado (IDE) Configuraciones al consentir Servicios web de Amazon (AWS) […]
Una manual visual para construir agentes de IA

¿Alguna vez le ha resultado frustrante construir agentes de IA que realicen múltiples tareas? Langgraph Studio está aquí para resolver este problema ofreciendo una forma visual e interactiva de diseñar, gobernar y depurar agentes. Construido en el ámbito Langgraph, esta utensilio de escritorio le permite crear flujos de trabajo de agentes utilizando una interfaz simple […]
Acelerar la creación de la tubería de datos con la nueva interfaz visual en Amazon OpenSearch Ingestión

Ingestión de Amazon OpenSearch es una tubería sin servidor totalmente administrada que le permite ingerir, filtrar, trocar, enriquecer y enrutar datos a un Servicio de Amazon OpenSearch dominio o Amazon OpenSearch Servidor sin ser compendio. La ingestión de OpenSearch es capaz de ingerir datos de una amplia variedad de fuentes y tiene un rico ecosistema […]
MaVEn: An Efficient Multi-granularity Hybrid Visible Encoding Framework for Multimodal Giant Language Fashions (MLLMs)
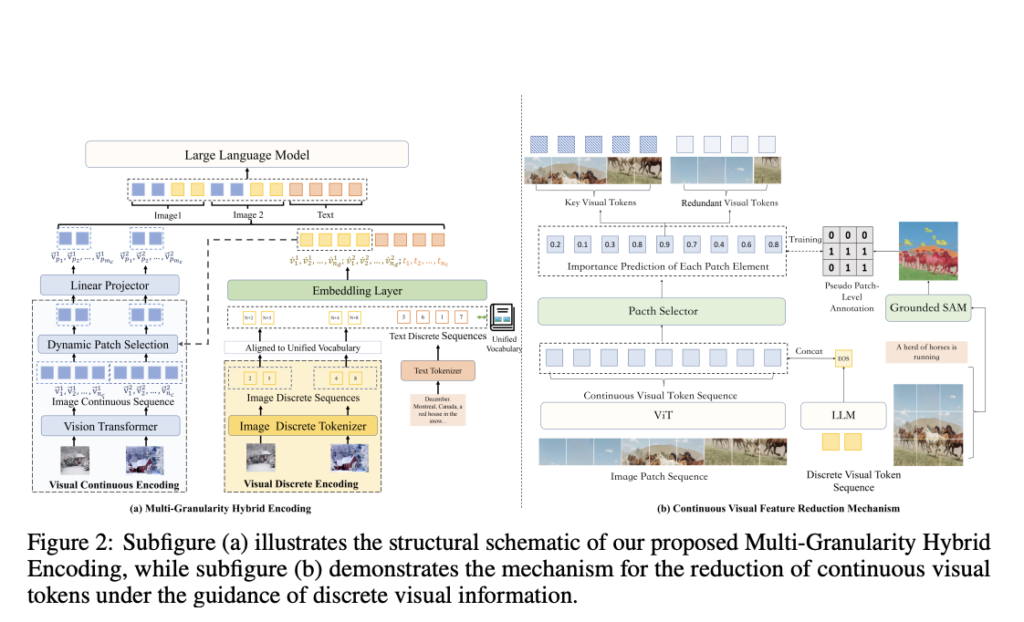
The primary focus of current Multimodal Giant Language Fashions (MLLMs) is on particular person picture interpretation, which restricts their means to sort out duties involving many pictures. These challenges demand fashions to grasp and combine info throughout a number of pictures, together with Data-Primarily based Visible Query Answering (VQA), Visible Relation Inference, and Multi-image Reasoning. […]