
Black Forest Labs alabarda FLUX.2: un transformador de amoldamiento de flujo 32B para tuberías de imágenes de producción

Black Forest Labs ha enérgico FLUX.2, su sistema de tiraje y coexistentes de imágenes de segunda coexistentes. FLUX.2 se dirige a flujos de trabajo creativos del mundo actual, como activos de marketing, fotografías de productos, diseños e infografías complejas, con soporte de tiraje de hasta 4 megapíxeles y un cachas control sobre el diseño, los […]
ByteDance Research presenta FLUX de 1,58 bits: un nuevo enfoque de IA que cuantifica el 99,5% de los parámetros del transformador a 1,58 bits

Los Vision Transformers (ViT) se han convertido en la piedra angular de la visión por computadora y ofrecen un gran rendimiento y adaptabilidad. Sin secuestro, su gran tamaño y sus demandas computacionales crean desafíos, particularmente para la implementación en dispositivos con posibles limitados. Modelos como FLUX Vision Transformers, con miles de millones de parámetros, requieren […]
Present-o: un modelo de IA unificado que unifica la comprensión y la generación multimodal utilizando un único transformador
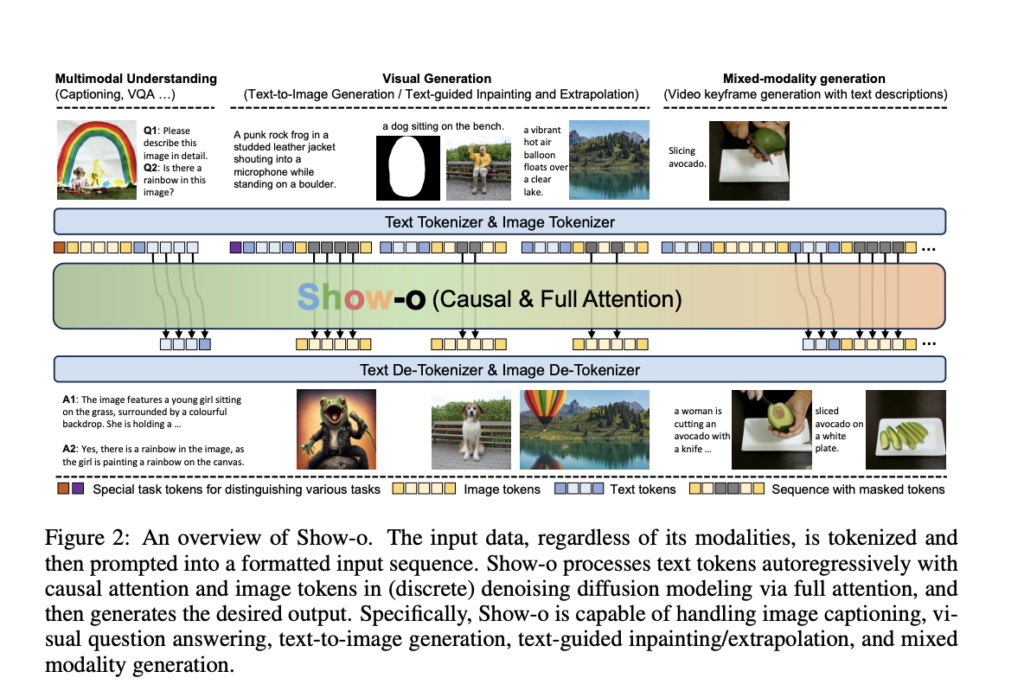
Este artículo presenta Present-o, un modelo de transformador unificado que integra capacidades de comprensión y generación multimodal dentro de una única arquitectura. A medida que avanza la inteligencia synthetic, ha habido un progreso significativo en la comprensión multimodal (por ejemplo, la respuesta a preguntas visuales) y la generación (por ejemplo, la síntesis de texto a […]