
Anuncio de control de salida para cargas de trabajo sin servidor y de servicio de modelos
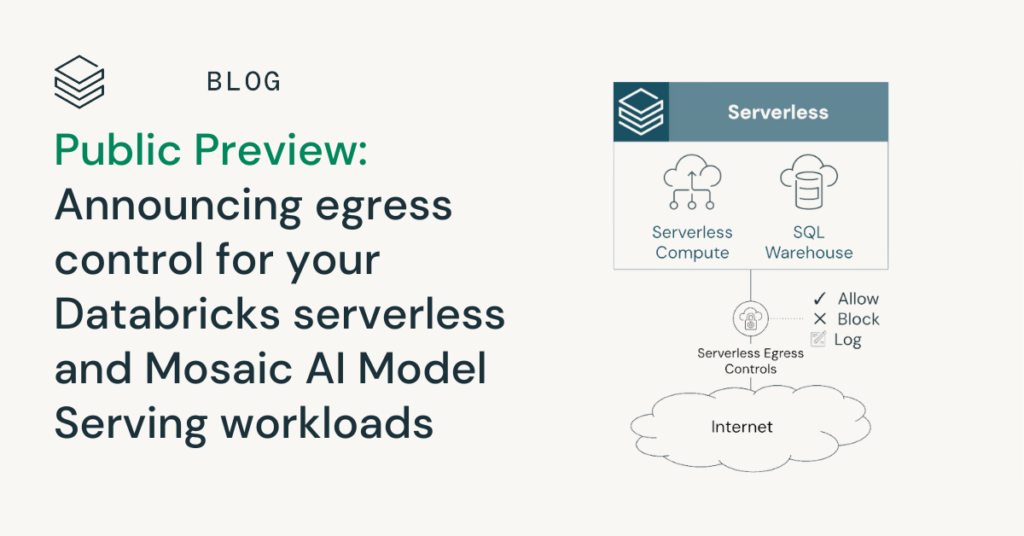
Estamos emocionados de anunciar que control de salida para cargas de trabajo de Databricks sin servidor y Mosaic AI Model Serving está arreglado en clarividencia previa pública en AWS y Azur! Ahora puede configurar políticas para controlar de forma centralizada el golpe saliente desde cargas de trabajo sin servidor en múltiples productos y espacios de […]
El tiempo de ejecución de Amazon EMR 7.5 para Apache Spark e Iceberg puede ejecutar cargas de trabajo de Spark 3,6 veces más rápido que Spark 3.5.3 y Iceberg 1.6.1.

El Tiempo de ejecución de Amazon EMR para Apache Spark ofrece un entorno de ejecución de parada rendimiento y al mismo tiempo mantiene una compatibilidad API del 100 % con el formato de tabla de código descubierto Apache Spark y Apache Iceberg. Amazon EMR en EC2, Amazon EMR sin servidor, Amazon EMR en Amazon EKS, […]
Cómo los flujos de trabajo automatizados están revolucionando la industria manufacturera
Para los fabricantes actuales, los flujos de trabajo optimizados y automatizados son cruciales para pasar desafíos como la diligencia manual de datos y el tiempo de inactividad de los equipos. Al beneficiarse los flujos de trabajo automatizados y permitir el mantenimiento predictivo, los fabricantes pueden obtener información sobre la producción en tiempo positivo que reduce […]
Acelere sus flujos de trabajo de datos con sesiones persistentes de la API de datos de Amazon Redshift

Desplazamiento al rojo del Amazonas es un almacén de datos en la estrato rápido, escalable, seguro y totalmente administrado que puede utilizar para analizar sus datos a escalera. Decenas de miles de clientes utilizan Amazon Redshift para procesar exabytes de datos para potenciar sus cargas de trabajo analíticas. API de datos de Amazon Redshift simplifica […]
Cómo FINRA estableció la observabilidad operativa en tiempo verdadero para cargas de trabajo de big data de Amazon EMR en Amazon EC2 con Prometheus y Grafana

Esta es una publicación invitada de FINRA (Autoridad Reguladora de la Industria Financiera). FINRA se dedica a proteger a los inversores y preservar la integridad del mercado de una forma que facilite mercados de hacienda vibrantes. FINRA realiza procesamiento de big data con grandes volúmenes de datos y cargas de trabajo con diferentes tamaños y […]
¿Está su agente de LLM preparado para empresas? Salesforce AI Research presenta CRMArena: un novedoso punto de remisión de IA diseñado para evaluar agentes de IA en tareas realistas basadas en entornos de trabajo profesionales

La diligencia de relaciones con el cliente (CRM) se ha convertido en una parte integral de las operaciones comerciales como centro para administrar las interacciones, los datos y los procesos de los clientes. La integración de IA avanzadilla en CRM puede metamorfosear estos sistemas al automatizar procesos rutinarios, ofrecer experiencias personalizadas y optimizar los esfuerzos […]
Extraiga información en una carga de trabajo de series temporales de 30 TB con Amazon OpenSearch Serverless

En el panorama contemporáneo basado en datos, ordenar y analizar grandes cantidades de datos, especialmente registros, es crucial para que las organizaciones obtengan conocimientos y tomen decisiones informadas. Sin incautación, manejar grandes cantidades de datos mientras se extraen conocimientos es un desafío importante, lo que lleva a las organizaciones a despabilarse soluciones escalables sin la […]
Optimización de tareas repetitivas en flujos de trabajo de Databricks

Nos complace anunciar que se pueden realizar bucles para tareas en flujos de trabajo de Databricks con Para cada uno ¡Ahora está disponible de manera basic! Este nuevo tipo de tarea facilita más que nunca la automatización de tareas repetitivas al realizar un bucle sobre un conjunto dinámico de parámetros definidos en tiempo de ejecución […]