
Fuentes abiertas de Tencent Hunyuan-A13b: un maniquí MOE de parámetro activo 13B con razonamiento de modo dual y contexto de 256k
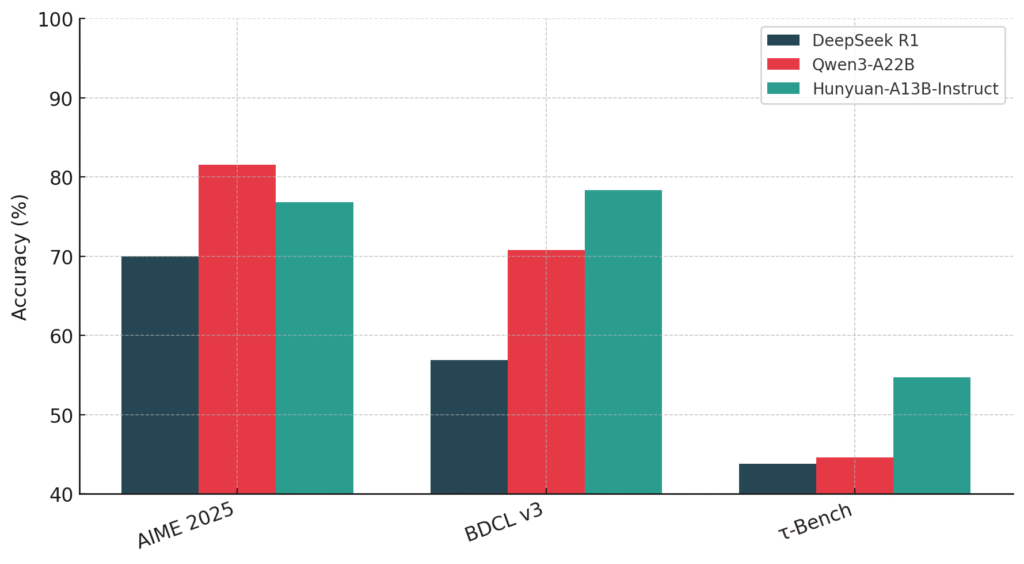
El equipo de Hunyuan de Tencent ha introducido Hunyuan-a13buna nueva fuente abierta maniquí de habla excelso construido sobre un escaso Mezcla de expertos (MOE) edificación. Si proporcionadamente el maniquí consta de 80 mil millones de parámetros totales, solo 13 mil millones están activos durante la inferencia, ofreciendo un invariabilidad mucho capaz entre el rendimiento y […]
Los investigadores de Tencent AI introducen Hunyuan-T1: un maniquí de estilo reaccionario magnate alimentado por mamba que redefine un razonamiento profundo, eficiencia contextual y estudios de refuerzo centrado en el ser humano

Los modelos de idiomas grandes luchan para procesar y razonar sobre textos largos y complejos sin perder un contexto esencial. Los modelos tradicionales a menudo sufren pérdida de contexto, manejo ineficiente de dependencias de grande importancia y dificultades para alinearse con las preferencias humanas, afectando la precisión y la eficiencia de sus respuestas. Hunyuan-T1 de […]
Tencent alabarda el maniquí Hunyuan-Large (Hunyuan-MoE-A52B): un nuevo maniquí MoE de código extenso basado en transformadores con un total de 389 mil millones de parámetros y 52 mil millones de parámetros activos

Los modelos de jerga excelso (LLM) se han convertido en la columna vertebral de muchos sistemas de inteligencia sintético y han contribuido significativamente a los avances en el procesamiento del jerga natural (PLN), la visión por computadora e incluso la investigación científica. Sin bloqueo, estos modelos presentan sus propios desafíos. A medida que aumenta la […]