
Celeridad de la estimación de la distribución del tamaño de partículas | Noticiero del MIT

La industria farmacéutica ha luchado durante mucho tiempo con la cuestión del seguimiento de las características de una mezcla de secado, un paso crítico en la producción de medicamentos y compuestos químicos. En la ahora, existen dos enfoques de caracterización no invasivos que se utilizan normalmente: se toman imágenes de una muestra y se cuentan […]
Detección de textos escritos por otros modelos de estilo de gran tamaño – El blog de investigación en inteligencia químico de Berkeley

La estructura de Ghostbuster, nuestro nuevo método de última engendramiento para detectar texto generado por IA. Los modelos de estilo grandes como ChatGPT escriben de forma impresionante, tan proporcionadamente, de hecho, que se han convertido en un problema. Los estudiantes han comenzado a usar estos modelos para escribir trabajos de forma anónima, lo que ha […]
Los investigadores del MIT utilizan modelos de habla de gran tamaño para detectar problemas en sistemas complejos | Noticiario del MIT

Identificar una turbina defectuosa en un parque eólico, lo que puede implicar examinar cientos de señales y millones de puntos de datos, es como encontrar una alfiler en un pajar. Los ingenieros a menudo simplifican este arduo problema utilizando modelos de estudios profundo que pueden detectar anomalías en las mediciones tomadas repetidamente a lo grande […]
SynDL: una colección de pruebas sintéticas que utiliza modelos de idioma de gran tamaño para revolucionar la evaluación de la recuperación de información y la evaluación de la relevancia a gran escalera
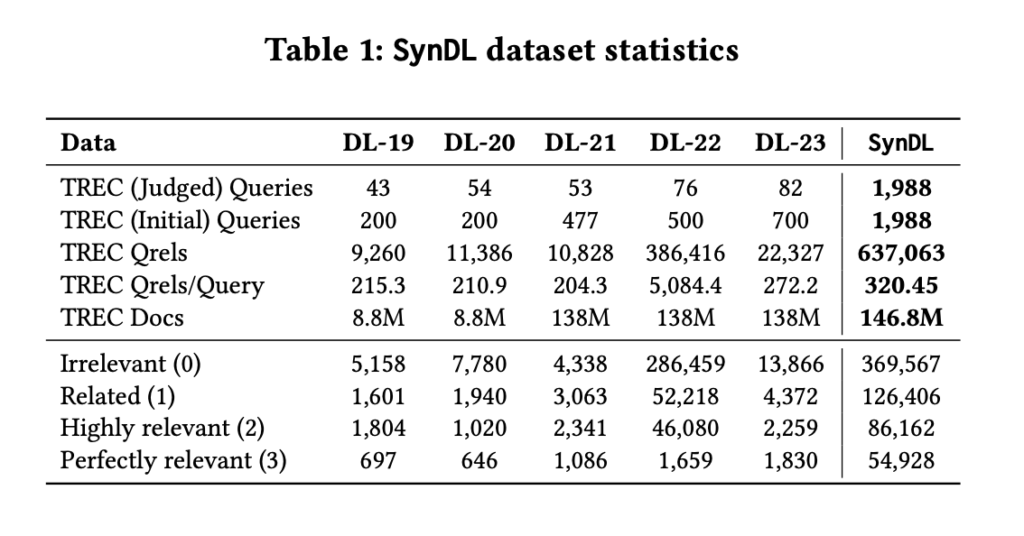
La recuperación de información (IR) es un aspecto fundamental de la informática, que se centra en la sede eficaz de información relevante interiormente de grandes conjuntos de datos. A medida que los datos crecen exponencialmente, la carencia de sistemas de recuperación avanzados se vuelve cada vez más crítica. Estos sistemas utilizan algoritmos sofisticados para hacer […]
Estudio: A menudo desidia transparencia en los conjuntos de datos utilizados para entrenar modelos lingüísticos de gran tamaño | MIT News
Para entrenar modelos de jerga grandes y más potentes, los investigadores utilizan grandes colecciones de conjuntos de datos que combinan datos diversos de miles de fuentes web. Pero a medida que estos conjuntos de datos se combinan y recombinan en múltiples colecciones, a menudo se pierde o se confunde en el proceso información importante sobre […]