
El poder de RLVR: capacitar a un maniquí de razonamiento SQL líder en Databricks
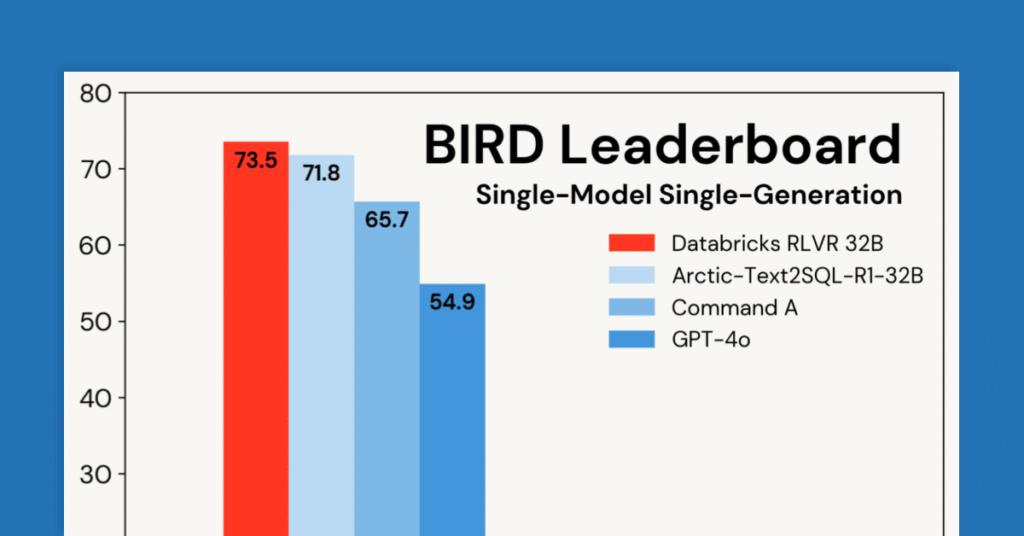
En Databricks, utilizamos Refplyiendo Learning (RL) para desarrollar modelos de razonamiento para problemas que enfrentan nuestros clientes, así como para nuestros productos, como el Asistente de Databricks y Ai/bi temperamento. Estas tareas incluyen producir código, analizar datos, integrar el conocimiento organizacional, la evaluación específica del dominio y Procedencia de información (es asegurar) de documentos. Tareas […]
Cortex AISQL: reinventar SQL en el idioma de consulta AI para datos multimodales

Hoy, estamos entusiasmados de anunciar la corteza de cocaína Cortex AISQL en una panorámica previa pública, trayendo poderosas capacidades de IA directamente al motor SQL de Snowflake. Cortex AISQL permite a los clientes construir tuberías de IA escalables a través de datos empresariales multimodales con comandos SQL familiares. Texto de proceso (panorámica previa pública), imágenes […]
Cree mejores tuberías de datos con SQL y Python en Snowflake
SnowPark ahora ofrece capacidades mejoradas para sufrir el código a los datos de forma segura y apto entre idiomas, con un soporte ampliado a través de la integración de datos, la diligencia de paquetes y la conectividad segura. Las actualizaciones incluyen: Integración de datos: Con el soporte de Python DB-API (aspecto previa privada), […]
Preámbulo de SQL Scripting Support en Databricks, Parte 1
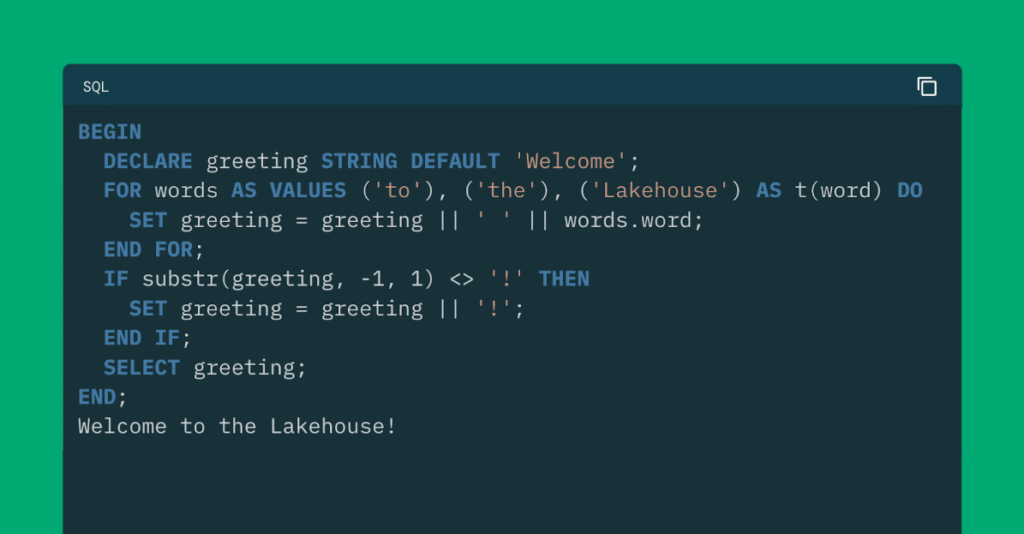
Hoy, Databricks anuncia soporte para el ANSI SQL/PSM lengua de secuencias de comandos! SQL Scripting ahora está apto en Databricks, trayendo dialéctica de procedimiento como onda y flujo de control directamente al SQL que ya conoce. Scripting en Databricks se podio en estándares abiertos y es totalmente compatible con Apache Spark ™. Para los usuarios […]
Implementación de un almacén de datos dimensional con Databricks SQL: Parte 2
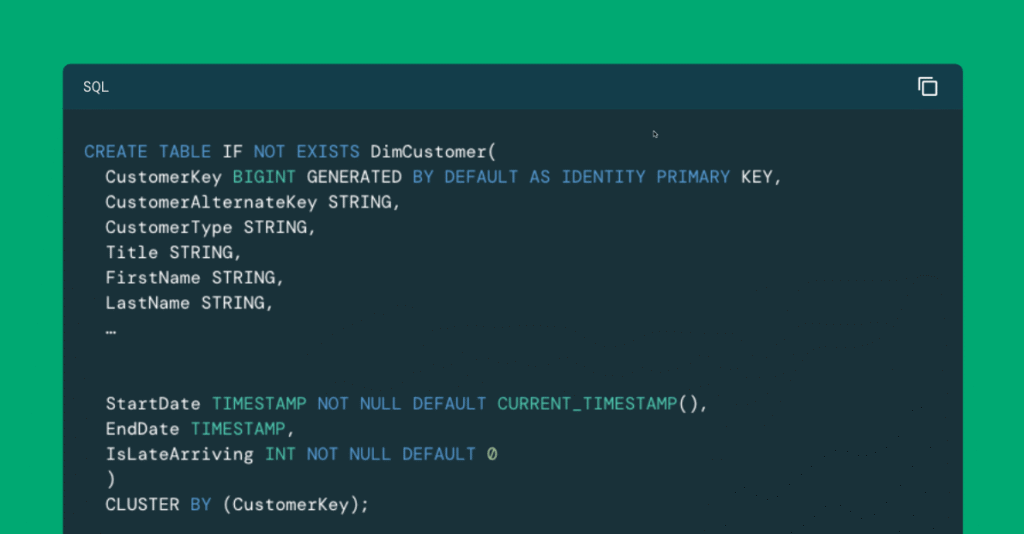
A medida que las organizaciones consolidan las cargas de trabajo de descomposición a Databricks, a menudo necesitan adaptar técnicas tradicionales de almacén de datos. Esta serie explora cómo implementar el modelado dimensional, específicamente, esquemas de estrellas, en Databricks. El primer blog se centró en el diseño de esquemas. Este blog camina a través de tuberías […]
Anuncio de la disponibilidad caudillo de vistas materializadas y tablas de transmisión para Databricks SQL

Estamos emocionados de anunciar que vistas materializadas (MV) y mesas de streaming (ST) ahora están disponibles con carácter caudillo en Databricks SQL en AWS y Azure. Las tablas de transmisión ofrecen una ingesta simple e incremental de fuentes como almacenamiento en la aglomeración y buses de mensajes con solo unas pocas líneas de SQL. Las […]
Presentamos el nuevo editor SQL

En los últimos primaveras, hemos manido un enorme crecimiento y apadrinamiento de Databricks SQL.nuestro almacén de datos inteligente diseñado específicamente en la plataforma de inteligencia de datos (tome el repaso por el producto). Nuestro incansable enfoque en el cliente impulsa todo lo que hacemos, ayudándonos a iterar para hacerlo aún más productivo al crear SQL. […]
Novedades de Databricks SQL
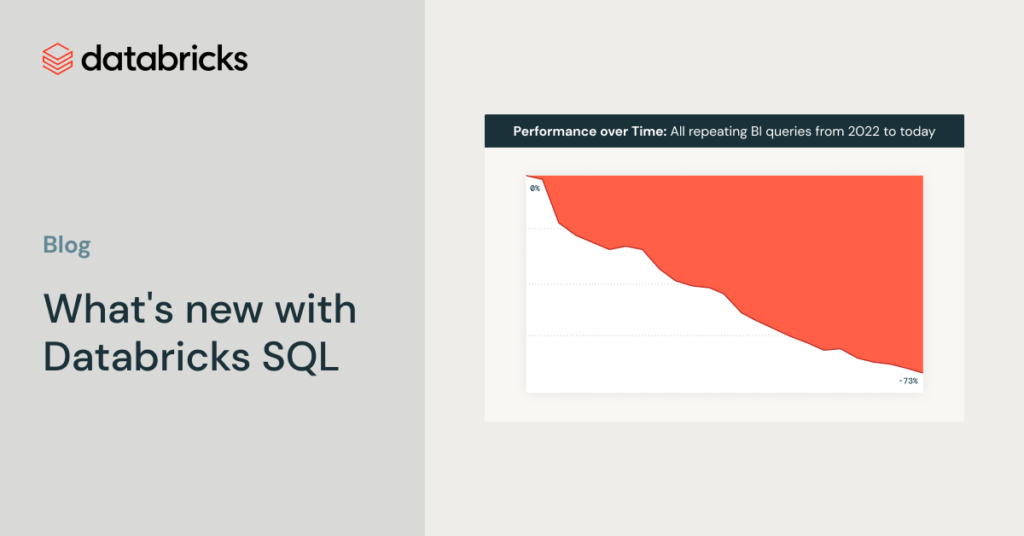
Nos complace compartir las últimas características nuevas y mejoras de rendimiento que hacen que Databricks SQL sea más simple, más rápido y más financiero que nunca. Con más de 7000 clientes que utilizan Databricks SQL como su almacén de datos en la ahora, este se ha convertido en el producto de más rápido crecimiento en […]
Consumiendo datos de SQL Server con Google Dataproc

Antiguamente de iniciar, es necesario que tengas los siguientes insumos listos! Lo primero que vamos a hacer es crear un bucket en Google Cloud en donde almacenaremos los archivos. frasco que vamos a utilizar En este cubo que yo he llamado prueba-iwco Vamos a crear 2 carpetas que utilizaremos más delante. En la carpeta paso […]