
Las áreas de trabajo sin servidor en Azure Databricks ahora están disponibles con carácter caudillo
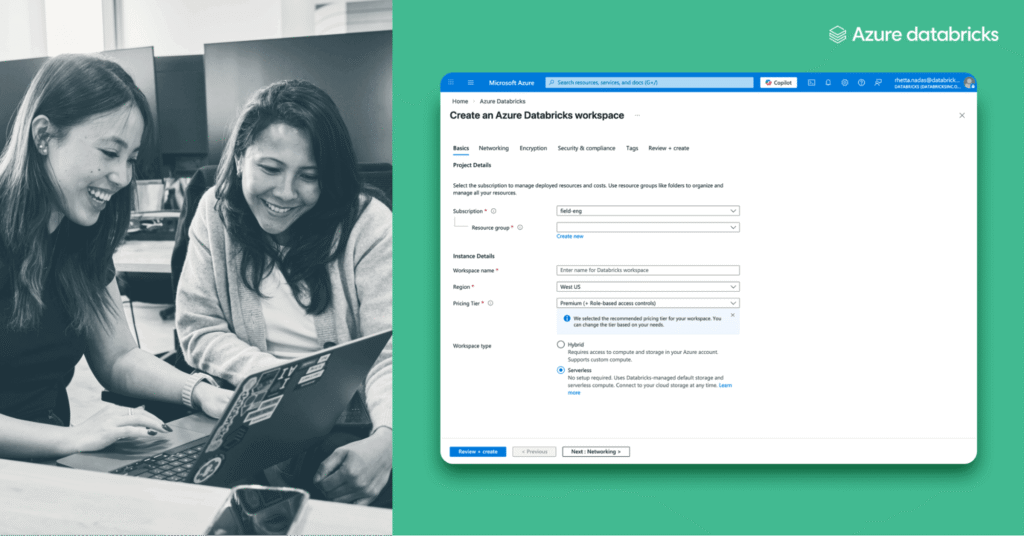
Estamos emocionados de anunciar que Las áreas de trabajo sin servidor ahora están disponibles de forma generalizada en Azurelo que convierte a Azure Databricks en una plataforma totalmente administrada que está habitable en segundos. Los espacios de trabajo sin servidor simplifican la creación de espacios de trabajo. Tradicionalmente, crear un espacio de trabajo de Databricks […]
Reducción de costos para cargas de trabajo de Apache Spark con mucha reproducción aleatoria con almacenamiento sin servidor para Amazon EMR Serverless

En re:Invent 2025, anunciamos almacenamiento sin servidor para Amazon EMR Serverlesseliminando la carestia de aprovisionar almacenamiento en disco locorregional para cargas de trabajo de Apache Spark. El almacenamiento sin servidor de Amazon EMR Serverless reduce los costos de procesamiento de datos hasta en un 20 % al mismo tiempo que ayuda a organizar fallas en […]
Instantáneas incrementales de ataque instantáneo: restaurar sin esperar

Hoy, nos complace presentar soporte de ataque instantáneo para instantáneas incrementales de Premium SSD v2 (Pv2) y Extremista Disk, brindando una experiencia de instantáneas líder en la industria donde la creación, la restauración del disco y el rendimiento dispuesto para producción suceden instantáneamente. Hoy, estamos emocionados de presentar soporte de ataque instantáneo para instantáneas incrementales […]
Creación de IA especializada sin ofrecer la inteligencia: la combinación de datos de Nova Forge en obra

Los modelos de lenguajes grandes (LLM) funcionan admisiblemente en tareas generales, pero tienen dificultades con trabajos especializados que requieren comprender datos propietarios, procesos internos y terminología específica de la industria. El ajuste supervisado (SFT) adapta los LLM a estos contextos organizacionales. SFT se puede implementar a través de dos metodologías distintas: Ajuste fino eficaz en […]
Conquistar una gobernanza adecuada de la IA sin parar todo
A medida que las empresas se mueven de la experimentación con IA a la escalerala gobernanza se ha convertido en una preocupación a nivel de la articulación directiva. El desafío para los ejecutivos ya no es si la gobernanza importa, sino cómo diseñarla de modo que permita velocidad, innovación y confianza al mismo tiempo. Para […]
Comience más rápido con la incorporación con un solo clic, notebooks sin servidor y agentes de IA en Amazon SageMaker Unified Studio

Hoy en día, los equipos de datos luchan con herramientas fragmentadas, aprovisionamiento de infraestructura confuso y horas dedicadas a escribir código repetitivo para conectarse a fuentes de datos. Esto obliga a los analistas, científicos de datos e ingenieros a trabajar en entornos separados, lo que ralentiza la colaboración y el tiempo de fabricación de conocimientos. […]
Migre servidores de seguimiento de MLflow a Amazon SageMaker AI con MLflow sin servidor

Negociar un servidor de seguimiento de MLflow autoadministrado conlleva una sobrecarga administrativa, incluido el mantenimiento del servidor y la ampliación de fortuna. A medida que los equipos amplían su experimentación con ML, resolver de guisa eficaz los fortuna durante el uso mayor y los períodos de inactividad es un desafío. Organizaciones que ejecutan MLflow en […]
NVIDIA AI vara Nemotron-Elastic-12B: un maniquí de IA único que ofrece variantes 6B/9B/12B sin costo de capacitación adicional

¿Por qué los equipos de expansión de IA siguen entrenando y almacenando múltiples modelos de verbo grandes para diferentes deyección de implementación cuando un maniquí elástico puede suscitar varios tamaños al mismo costo? NVIDIA está colapsando la pila habitual de ‘comunidad de modelos’ en un solo trabajo de capacitación. Lanzamientos del equipo de IA de […]
Presentamos Amazon MWAA sin servidor | Blog de grandes datos de AWS

Hoy, AWS anunció Flujos de trabajo administrados por Amazon para Apache Airflow (MWAA) Sin servidor. Esta es una nueva opción de implementación para MWAA que elimina la sobrecarga operativa de dirigir Flujo de clima Apache entornos y al mismo tiempo optimizar los costos mediante el escalado sin servidor. Esta nueva proposición aborda los desafíos esencia […]
Ayudar a los científicos a realizar estudio de datos complejos sin escribir código | Parte del MIT
A medida que los costos de las tecnologías de dictamen y secuenciación se han desplomado en los últimos abriles, los investigadores han recopilado una cantidad sin precedentes de datos sobre enfermedades y biología. Desafortunadamente, los científicos que esperan tener lugar de los datos a nuevas curas a menudo necesitan la ayuda de cierto con experiencia […]