
Desempacando el sesgo de los modelos de idiomas grandes | MIT News
La investigación ha demostrado que los modelos de idiomas grandes (LLM) tienden a resaltar demasiado la información al principio y al final de un documento o conversación, al tiempo que descuidan el medio. Este «sesgo de posición» significa que, si un abogado está utilizando un asistente potencial con motor LLM para recuperar una cierta frase […]
3 Preguntas: Cómo ayudar a los estudiantes a confesar un sesgo potencial en sus conjuntos de datos de IA | MIT News

Cada año, miles de estudiantes toman cursos que les enseñan cómo desplegar modelos de inteligencia fabricado que puedan ayudar a los médicos a diagnosticar enfermedades y determinar los tratamientos adecuados. Sin requisa, muchos de estos cursos omiten un pájaro esencia: capacitar a los estudiantes para detectar fallas en los datos de capacitación utilizados para desarrollar […]
Un estudio revela que los chatbots de IA pueden detectar la raza, pero el sesgo étnico reduce la empatía en la respuesta | Parte del MIT

Con la cobertura del anonimato y la compañía de extraños, el atractivo del mundo digital está creciendo como sitio para averiguar apoyo para la salubridad mental. Este engendro se ve favorecido por el hecho de que más de 150 millones de personas en los Estados Unidos viven en áreas de escasez de profesionales de salubridad […]
Los investigadores reducen el sesgo en los modelos de IA al tiempo que preservan o mejoran la precisión | Parte del MIT

Los modelos de estudios obligatorio pueden abortar cuando intentan hacer predicciones para personas que estaban subrepresentadas en los conjuntos de datos en los que fueron entrenados. Por ejemplo, un maniquí que predice la mejor opción de tratamiento para cualquiera con una enfermedad crónica puede entrenarse utilizando un conjunto de datos que contenga principalmente pacientes masculinos. […]
Investigadores de Microsoft presentan RadEdit: modelos de visión biomédicos para pruebas de estrés mediante tiraje de imágenes por difusión para eliminar el sesgo del conjunto de datos
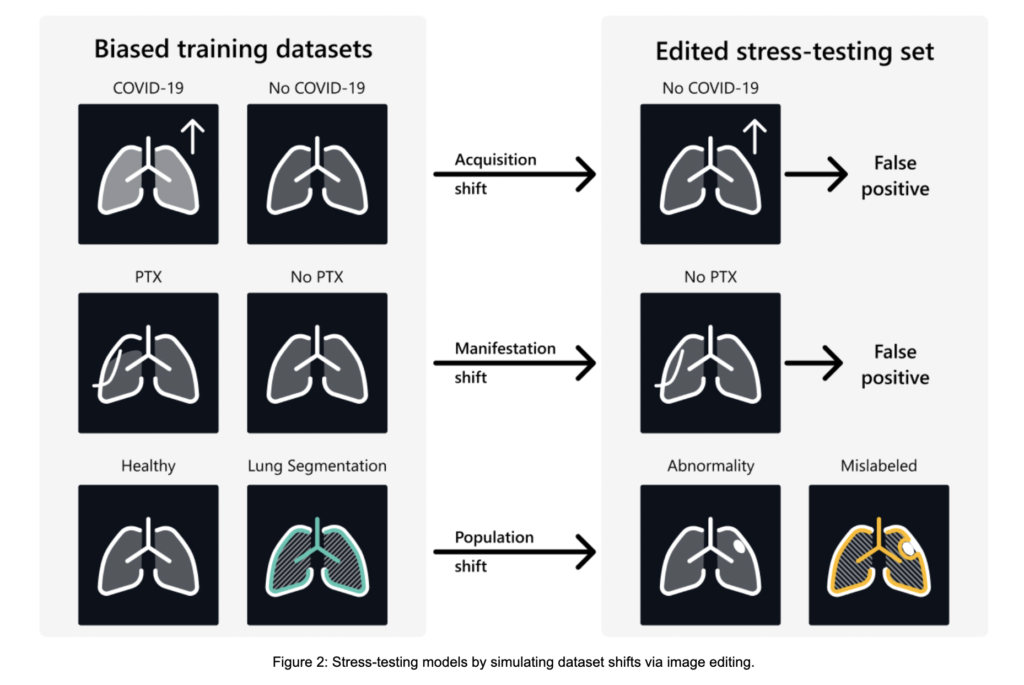
Los modelos de visión biomédicos se utilizan cada vez más en entornos clínicos, pero un desafío importante es su incapacidad para generalizarse de guisa efectiva conveniente a cambios de conjuntos de datos—Discrepancias entre los datos de entrenamiento y los escenarios del mundo efectivo. Estos cambios surgen de diferencias en la adquisición de imágenes, cambios en […]