
Presentación de Amazon Q desarrollador en el servicio de Amazon OpenSearch

Los clientes usan Servicio de Amazon OpenSearch Para acumular sus datos de señal operativos y de telemetría. Utilizan estos datos para monitorear la vitalidad de sus aplicaciones e infraestructura, de modo que cuando ocurra un problema de producción, pueda identificar la causa rápidamente. El gran bulto y la variedad de datos a menudo hacen que […]
Creación de mejores resultados de atención médica con el servicio Azure OpenAi y Azure Ai Foundry

Lea cómo los proveedores de atención médica racionalizan las tareas, aceleran la investigación y mejoran la atención al paciente con el servicio Azure OpenAI y la fundición de AI Azure. La industria de la vigor ha estado constantemente a la vanguardia de los avances tecnológicos, buscando continuamente formas de mejorar la atención y los resultados […]
Entrada de la búsqueda vectorial con ultrawarm en el servicio de Amazon OpenSearch

Servicio de Amazon OpenSearch ha estado proporcionando capacidades de bases de datos vectoriales para permitir búsquedas eficientes de similitud vectorial utilizando índices especializados de vecinos K-Nearest (K-NN) a los clientes desde 2019. Esta funcionalidad ha admitido varios casos de uso, como búsqueda semántica, concepción de concepción de recuperación (RAG) con modelos de idiomas grandes (LLMS) […]
Mejore los resultados de búsqueda para IA utilizando el servicio Amazon OpenSearch como una pulvínulo de datos vectorial con Amazon Bedrock

La inteligencia sintético (IA) ha transformado cómo los humanos interactúan con la información de dos maneras principales: aplicaciones de búsqueda e IA generativa. Las aplicaciones de búsqueda incluyen sitios web de comercio electrónico, búsqueda de repositorio de documentos, centros de llamadas de atención al cliente, encargo de relaciones con el cliente, emparejamiento para juegos y […]
Anunciando la disponibilidad del maniquí de razonamiento O3-Mini en el servicio Microsoft Azure OpenAI

Nos complace anunciar que el nuevo maniquí O3-Mini de OpenAI ahora está adecuado en el servicio Microsoft Azure OpenAI. Sobre la pulvínulo de la pulvínulo del maniquí O1, O3-Mini ofrece un nuevo nivel de eficiencia, rentabilidad y capacidades de razonamiento. Nos complace anunciar que Operai O3-Mini ahora está adecuado en Servicio Microsoft Azure OpenAI. O3-Mini […]
PROYECTIVO DEL ENTORNO SERVILLO DE SERVICIO PARA AMAZON SAGEMAKER STUDIO: un enfoque automatizado de tuberías de CI/CD

Adjuntar una imagen de Docker personalizada a un Amazon Sagemaker Studio El dominio implica varios pasos. Primero, debe construir y empujar la imagen a Registro de contenedores elásticos de Amazon (Amazon ECR). Incluso debes asegurarte de que el Amazon Sagemaker El rol de ejecución del dominio tiene los permisos necesarios para extraer la imagen de […]
Anuncio de control de salida para cargas de trabajo sin servidor y de servicio de modelos
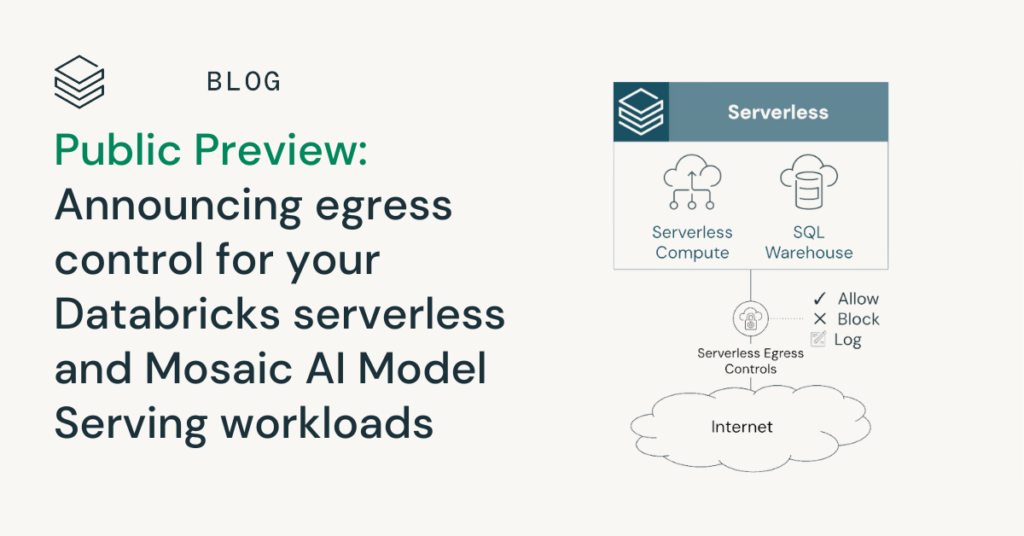
Estamos emocionados de anunciar que control de salida para cargas de trabajo de Databricks sin servidor y Mosaic AI Model Serving está arreglado en clarividencia previa pública en AWS y Azur! Ahora puede configurar políticas para controlar de forma centralizada el golpe saliente desde cargas de trabajo sin servidor en múltiples productos y espacios de […]
Investigadores de NVIDIA, CMU y la Universidad de Washington lanzaron ‘FlashInfer’: una biblioteca de kernel que proporciona implementaciones de kernel de última reproducción para inferencia y servicio de LLM

Los modelos de estilo grandes (LLM) se han convertido en una parte integral de las aplicaciones modernas de inteligencia fabricado, impulsando herramientas como chatbots y generadores de código. Sin requisa, la longevo dependencia de estos modelos ha revelado ineficiencias críticas en los procesos de inferencia. Los mecanismos de atención, como FlashAttention y SparseAttention, a menudo […]
Anuncio del maniquí o1 en el servicio Azure OpenAI

Nos complace anunciar que el maniquí o1 llegará pronto al servicio Microsoft Azure OpenAI. Este maniquí multimodal aporta capacidades de razonamiento avanzadas y mejoras que mejorarán significativamente sus aplicaciones y soluciones de IA. El maniquí o1 admite entradas de texto y de visión, lo que lo hace ideal para una amplia escala de aplicaciones, desde […]
¿Qué es y cómo funciona el servicio EC2 de AWS?

¿Alguna vez te has preguntado cómo funciona el servicio de instancias de máquinas virtuales EC2 de AWS y cuáles son sus beneficios? A continuación, encontrará toda la información relacionada sobre este servicio, sus características y sus beneficios: Las instancias EC2 (Elastic Compute Cloud) son una de las claves de servicios de Amazon Web Services (AWS) […]