
El poder de RLVR: capacitar a un maniquí de razonamiento SQL líder en Databricks
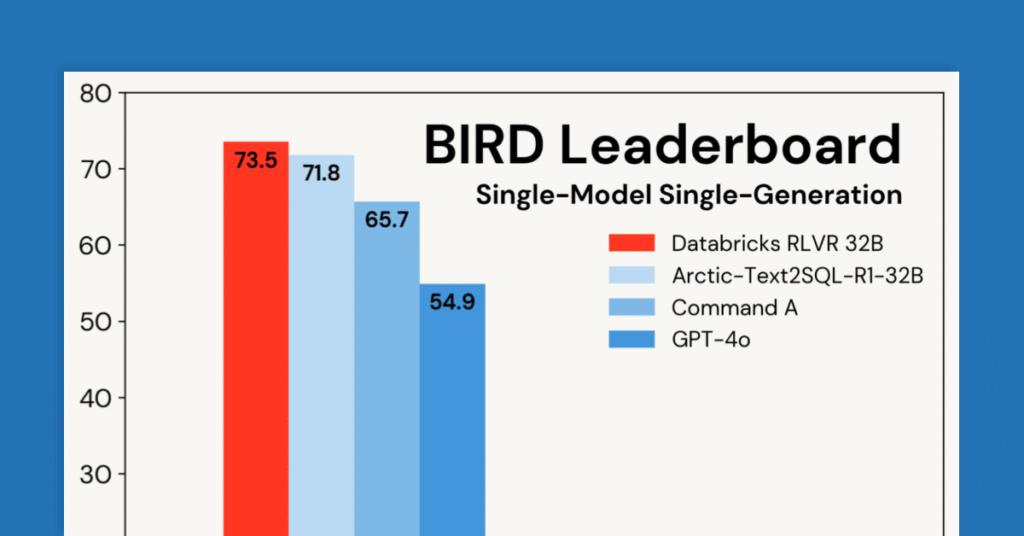
En Databricks, utilizamos Refplyiendo Learning (RL) para desarrollar modelos de razonamiento para problemas que enfrentan nuestros clientes, así como para nuestros productos, como el Asistente de Databricks y Ai/bi temperamento. Estas tareas incluyen producir código, analizar datos, integrar el conocimiento organizacional, la evaluación específica del dominio y Procedencia de información (es asegurar) de documentos. Tareas […]
La selección de token de entrada entropía en el formación de refuerzo con recompensas verificables (RLVR) perfeccionamiento la precisión y reduce el costo de capacitación para LLMS

Los modelos de jerga excelso (LLM) generan respuestas paso a paso conocidas como cautiverio de pensamientos (COTS), donde cada token contribuye a una novelística coherente y dialéctica. Para mejorar la calidad del razonamiento, se han empleado varias técnicas de formación de refuerzo. Estos métodos permiten al maniquí memorizar de los mecanismos de feedback al alinear […]
Los investigadores de Alibaba introducen R1-AMNI: una aplicación de educación de refuerzo con remuneración verificable (RLVR) a un maniquí de verbo alto omni-multimodal

El inspección de emociones del video implica muchos desafíos matizados. Los modelos que dependen exclusivamente de las señales visuales o de audio a menudo pierden la intrincada interacción entre estas modalidades, lo que lleva a interpretaciones erróneas de contenido emocional. Una dificultad secreto es combinar de guisa confiable las señales visuales, como las expresiones faciales […]