
Amazon Kinesis Data Streams aguijada On-demand Advantage para aumentos instantáneos del rendimiento y transmisión a escalera

Hoy, AWS anunció el nuevo Flujos de datos de Amazon Kinesis Modo Advantage bajo demanda, que incluye capacidad de rendimiento cálido y una estructura de precios actualizada. Con esta función, puede habilitar el escalado instantáneo para aumentos repentinos de tráfico y, al mismo tiempo, optimizar los costos para cargas de trabajo de transmisión consistentes. Superioridad […]
Qualifire AI Open-Sources Rogue: un situación de pruebas de inteligencia químico de extremo a extremo diseñado para evaluar el rendimiento, el cumplimiento y la confiabilidad de los agentes de inteligencia químico

Los sistemas agentes son estocásticos, dependientes del contexto y sujetos a políticas. El control de calidad convencional (pruebas unitarias, indicaciones estáticas o puntuaciones escalares de «LLM como magistrado») no expone las vulnerabilidades de múltiples turnos y proporciona pistas de auditoría débiles. Los equipos de desarrolladores necesitan conversaciones con protocolos precisos, verificaciones de políticas explícitas y […]
Cómo Azure Cobalt 100 VM están alimentando soluciones del mundo verdadero, entregando resultados de rendimiento y eficiencia

Los sistemas Cobalt 100 están diseñados para ofrecer un detención rendimiento, eficiencia energética y rentabilidad para una amplia tono de cargas de trabajo. Azure Cobalt 100 es nuestro CPU en la nubarrón basada en el remo, construida en la casa, construida a medida Potenciar las cargas de trabajo generales de calcular en la nubarrón. Los […]
El DOE selecciona MIT para establecer un centro para la simulación exascale de interacciones de fluido-ólido de detención rendimiento acoplado | MIT News

La Oficina Doméstico de Seguridad Nuclear del Unidad de Energía de los Estados Unidos (DOE/NNSA) recientemente anunciado que ha seleccionado MIT para establecer un nuevo centro de investigación dedicado a avanzar en la simulación predictiva de entornos extremos, como los encontrados en planeo hipersónico y reingreso atmosférico. El centro será parte de la cuarta escalón […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
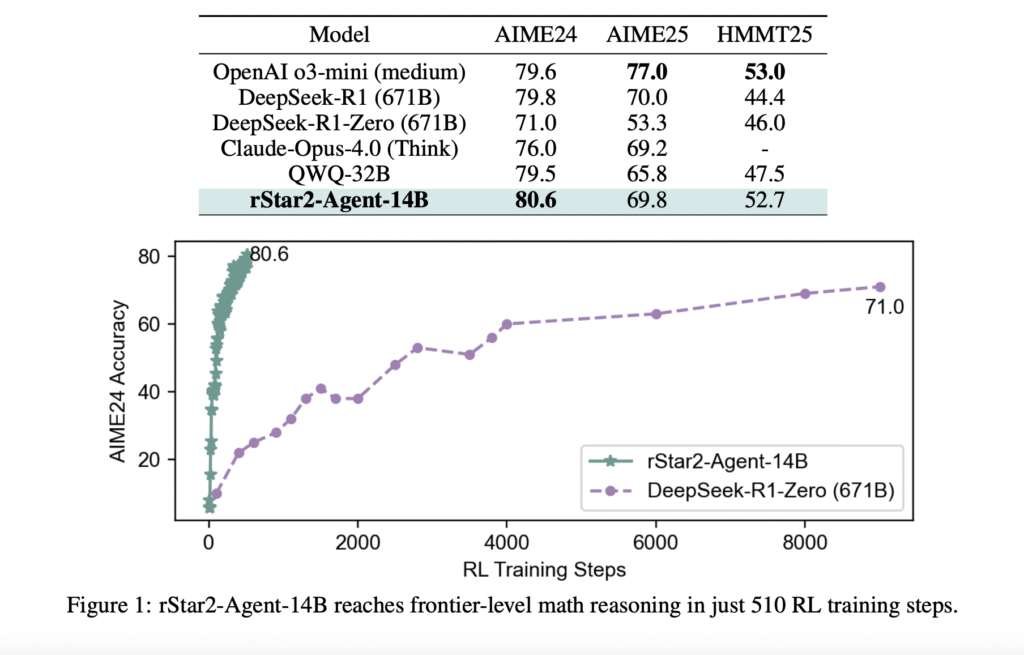
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
«Fusas futuras» muestra nuevas fronteras en tecnología musical y rendimiento interactivo | MIT News

La tecnología musical tomó el centro del proscenio en el MIT durante «Fusas futuras», una confusión de obras para la orquestina de cuerdas y la electrónica, presentada por el MIT Music Technology and Computation Graduate Graduate Program como parte de la Conferencia Internacional de Música de Computación de 2025 (ICMC). El evento adecuadamente asistido se […]
La Finalidad Ultimate 2025 para codificar los puntos de remisión y las métricas de rendimiento

Los modelos de idiomas grandes (LLM) especializados para la codificación ahora son parte integral del progreso de software, impulsando la productividad a través de la concepción de códigos, la fijación de errores, la documentación y la refactorización. La feroz competencia entre los modelos comerciales y de código rajado ha llevado a un rápido avance, así […]
Cómo conseguir, rendimiento, aplicación y más

No cuente a China fuera de la carrera de IA todavía. Mientras que todos se han obsesionado con Chatgpt y Grok, las empresas tecnológicas chinas han estado cocinando en silencio una competencia seria. Primero llegó Kimi K2 y Alibaba’s QWEN3-coder. Ahora Z.Ai acaba de dejar caer sus últimos modelos: GLM 4.5 y su lectura más […]
Los investigadores de Tiktok introducen SWE-Perf: el primer punto de relato para la optimización del rendimiento del código de nivel de repositorio
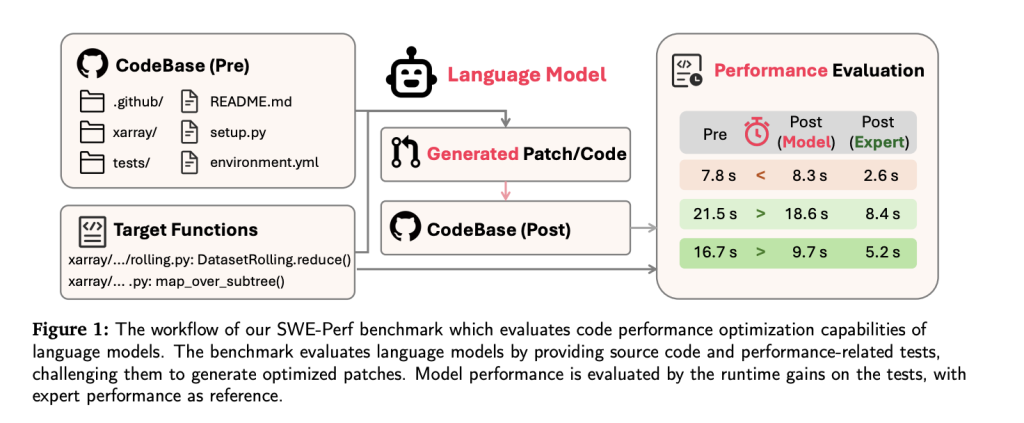
Comienzo A medida que avanzan los modelos de jerigonza holgado (LLMS) en tareas de ingeniería de software, que se extienden desde la concepción de códigos hasta la corrección de errores, la optimización de rendimiento sigue siendo una frontera evasiva, especialmente a nivel de repositorio. Para cerrar esta brecha, los investigadores de Tiktok y las instituciones […]
NVIDIA AI Liberes Canary-Qwen-2.5b: un maniquí híbrido ASR-LLM de última gestación con rendimiento de SOTA en la clasificación de OpenAsr
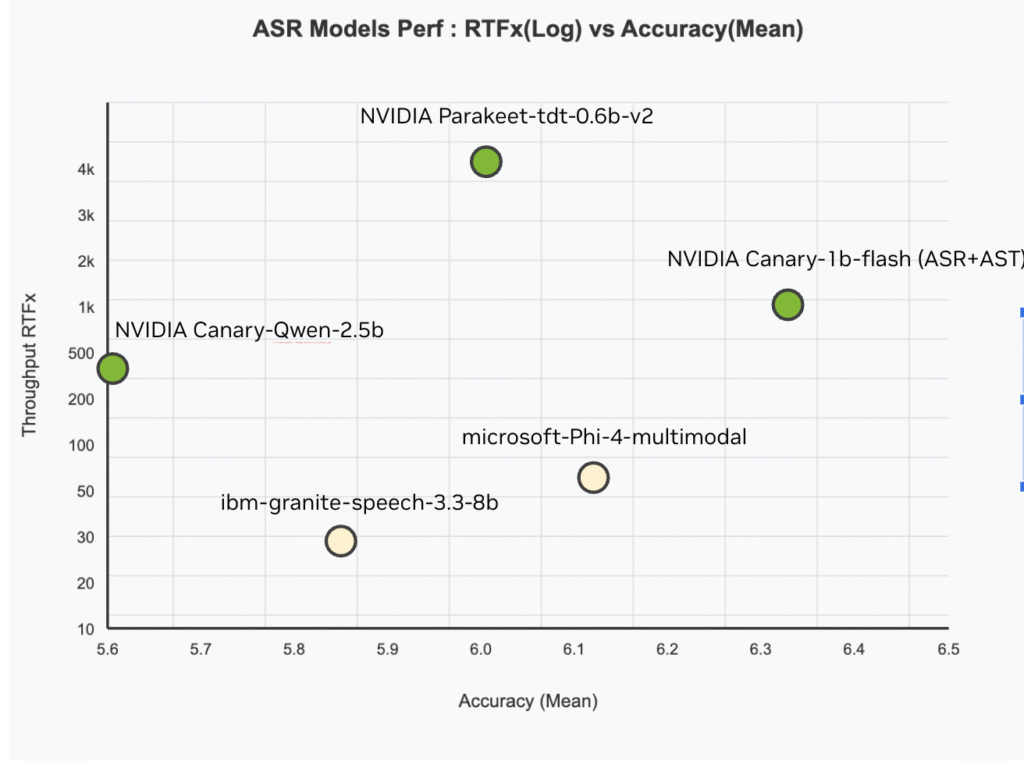
Nvidia acaba de exhalar Canary-Qwen-2.5bun progresista híbrido de registro instintivo de discurso (ASR) y Maniquí de jerigonza (LLM), que ahora encabeza la tabla de clasificación de AbrainAsr con un registro que establece récords Tasa de error de palabras (WER) de 5.63%. Con deshonestidad bajo Cc-byeste maniquí es los dos comercialmente permisivo y de código despejadoEmpujando […]