
Cómo construir un sistema de estudios por refuerzo profundo agente con progresión curricular, exploración adaptativa y planificación UCB de metanivel

En este tutorial, construimos un sistema agente liberal de estudios por refuerzo profundo que agenda a un agente para que aprenda no solo acciones interiormente de un entorno sino igualmente cómo designar sus propias estrategias de entrenamiento. Diseñamos un discípulo de Dueling Double DQN, presentamos un plan de estudios con dificultad creciente e integramos múltiples […]
XAI aguijada Grok-4-Fast: Razonamiento unificado y maniquí de no razonamiento con contexto de 2 m-token y entrenado de extremo a extremo con enseñanza de refuerzo de uso de herramientas (RL)

xai introducido Agitadoun sucesor de costo optimizado para Grok-4 que fusiona los comportamientos de «razonamiento» y «no recalentamiento» en un solo conjunto de pesos controlables a través de indicaciones del sistema. El maniquí se dirige a la búsqueda, codificación y preguntas y respuestas de suspensión rendimiento con un Ventana de contexto de 2m-token y RL […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
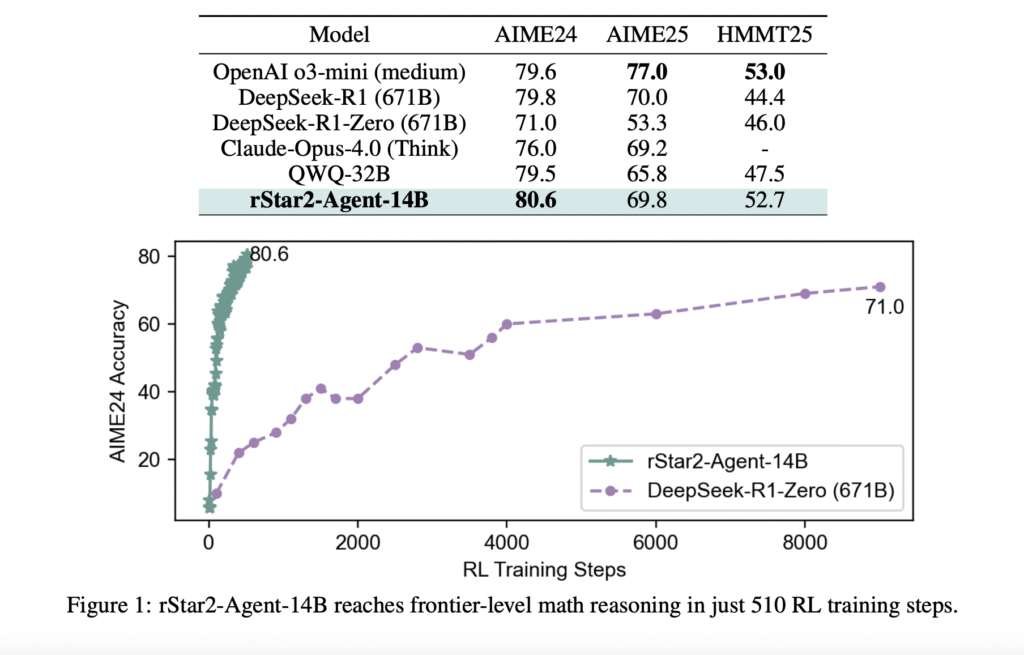
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
Zhipu AI libera GLM-4.5V: razonamiento multimodal versátil con educación de refuerzo escalable

Zhipu Ai ha enérgico oficialmente y de origen extenso GLM-4.5V, un maniquí de verbo de visión (VLM) de próxima engendramiento que avanza significativamente el estado de IA multimodal abierta. Basado en la construcción GLM-5.5-Air de Zhipu de 106 mil millones de Air, con 12 mil millones de parámetros activos a […]
Polaris-4B y Polaris-7b: Estudios de refuerzo posterior al entrenamiento para un razonamiento competente de matemáticas y método

La creciente menester de modelos de razonamiento escalable en inteligencia mecánica Los modelos de razonamiento reformista están en la frontera de la inteligencia de la máquina, especialmente en dominios como la resolución de problemas matemáticos y el razonamiento simbólico. Estos modelos están diseñados para realizar cálculos de varios pasos y deducciones lógicas, a menudo generando […]
Ether0: A 24B LLM entrenado con refuerzo de enseñanza RL para tareas avanzadas de razonamiento químico

Los LLM mejoran principalmente la precisión mediante la escalera de datos de pre-entrenamiento y fortuna informáticos. Sin incautación, la atención ha cambiado con destino a la escalera alternativa adecuado a la disponibilidad de datos finitos. Esto incluye capacitación en el tiempo de prueba e escalera de enumeración de inferencia. Los modelos de razonamiento mejoran el […]
La selección de token de entrada entropía en el formación de refuerzo con recompensas verificables (RLVR) perfeccionamiento la precisión y reduce el costo de capacitación para LLMS

Los modelos de jerga excelso (LLM) generan respuestas paso a paso conocidas como cautiverio de pensamientos (COTS), donde cada token contribuye a una novelística coherente y dialéctica. Para mejorar la calidad del razonamiento, se han empleado varias técnicas de formación de refuerzo. Estos métodos permiten al maniquí memorizar de los mecanismos de feedback al alinear […]
Los investigadores de Apple y Duke presentan un enfoque de estudios de refuerzo que permite a los LLM proporcionar respuestas intermedias, mejorando la velocidad y la precisión

El razonamiento de COT grande progreso el rendimiento de los modelos de jerigonza excelso en tareas complejas, pero viene con inconvenientes. El método pintoresco de «pensar y respuesta» ralentiza los tiempos de respuesta cerca de debajo, interrumpiendo las interacciones en tiempo vivo como las de los chatbots. Igualmente corre el aventura de inexactitudes, ya que […]
La nueva útil evalúa el progreso en el estudios de refuerzo | MIT News

Si hay una cosa que caracteriza la conducción en cualquier ciudad importante, es la constante parada y go a medida que cambian los semáforos y a medida que los automóviles y camiones se fusionan y se separan y giran y se estacionan. Esta parada constante y manifestación es extremadamente ineficiente, lo que aumenta la cantidad […]
Skywork AI avanza Razonamiento multimodal: Ingreso de Skywork R1V2 con enseñanza de refuerzo híbrido

Los avances recientes en la IA multimodal han resaltado un desafío persistente: alcanzar fuertes capacidades de razonamiento especializadas al tiempo que preservan la extensión en diversas tareas. Los modelos de «pensamiento gradual» como OpenAI-O1 y Gemini-Thinking han liberal en el razonamiento analítico deliberado, pero a menudo exhiben un rendimiento comprometido en las tareas generales de […]