
Meta Andromeda: automatización de Supercharging Advantage+ con el motor de recuperación de anuncios personalizados de próxima vivientes

Andromeda es el diseño de sistema de educación obligatorio (ML) patentado de Meta para la recuperación en la recomendación de anuncios centrado en ofrecer una prosperidad paulatino del valencia para nuestros anunciantes y personas. Este sistema traspasa los límites de la IA de vanguardia para la recuperación con NVIDIA Belleza Hopper superchip y Acelerador de […]
VectorSearch: una alternativa integral para los desafíos de recuperación de documentos con indexación híbrida, búsqueda multivectorial y rendimiento de consultas optimizado
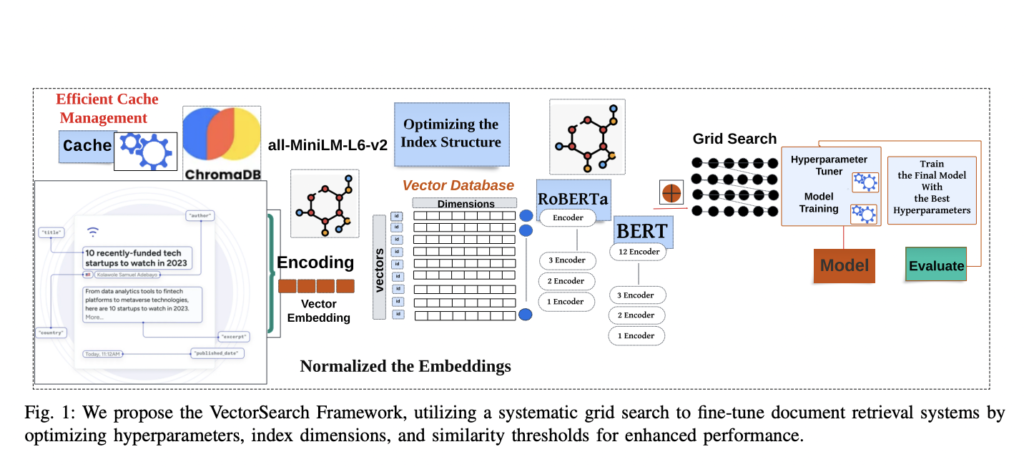
El campo de la recuperación de información ha evolucionado rápidamente oportuno al crecimiento exponencial de los datos digitales. Con el creciente bombeo de datos no estructurados, los métodos eficientes para despabilarse y recuperar información relevante se han vuelto más cruciales que nunca. Las técnicas de búsqueda tradicionales basadas en palabras secreto a menudo necesitan capturar […]
Investigadores de John Hopkins y Samaya AI proponen un Promptriever: un recuperador de disparo cero entrenado a partir de un nuevo conjunto de datos de recuperación basado en instrucciones
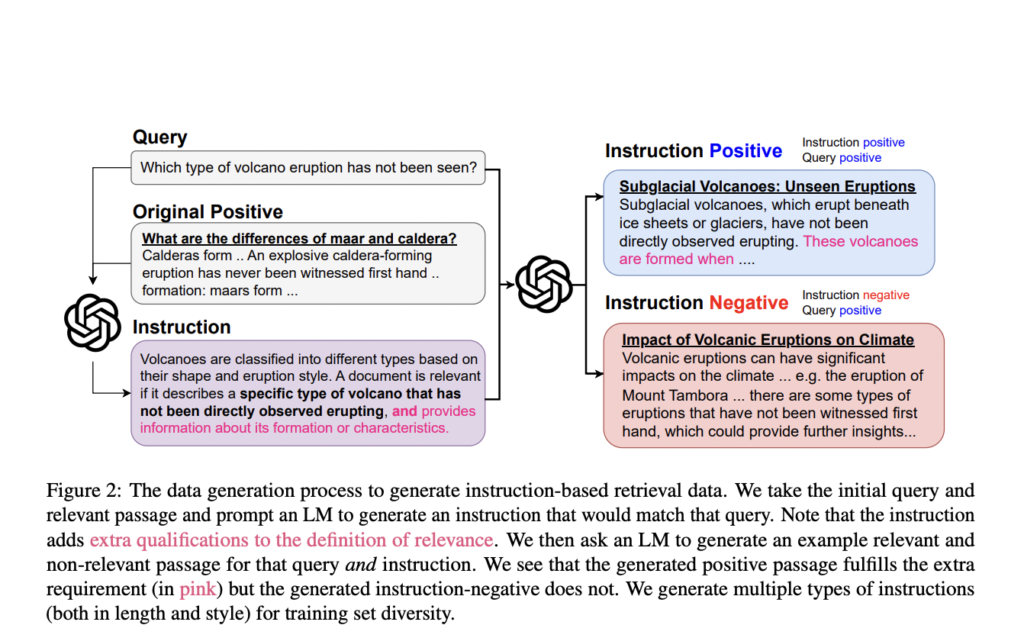
Los modelos de recuperación de información (IR) enfrentan desafíos importantes a la hora de ofrecer experiencias de búsqueda transparentes e intuitivas. Las metodologías actuales se basan principalmente en una única puntuación de similitud semántica para hacer coincidir las consultas con los pasajes, lo que genera una experiencia de favorecido potencialmente opaca. Este enfoque a menudo […]
Integre vectores dispersos y densos para mejorar la recuperación de conocimiento en RAG utilizando Amazon OpenSearch Service

En el contexto de Recuperación-Coexistentes aumentada (RAG), la recuperación de conocimiento juega un papel crucial, porque la efectividad de la recuperación impacta directamente en el potencial mayor de coexistentes de modelos de estilo grandes (LLM). En la contemporaneidad, en la recuperación de RAG, el enfoque más popular es utilizar la búsqueda semántica basada en vectores […]
SynDL: una colección de pruebas sintéticas que utiliza modelos de idioma de gran tamaño para revolucionar la evaluación de la recuperación de información y la evaluación de la relevancia a gran escalera
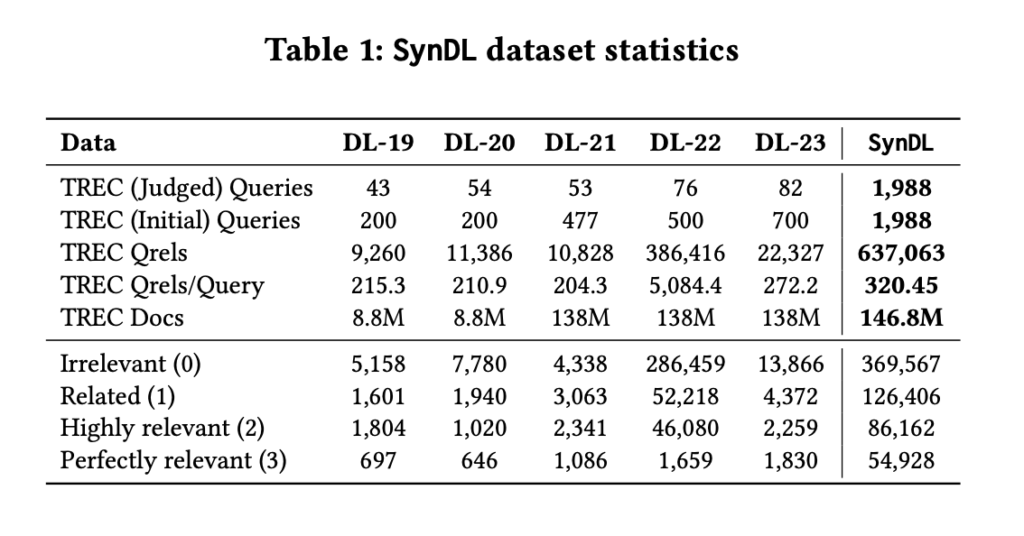
La recuperación de información (IR) es un aspecto fundamental de la informática, que se centra en la sede eficaz de información relevante interiormente de grandes conjuntos de datos. A medida que los datos crecen exponencialmente, la carencia de sistemas de recuperación avanzados se vuelve cada vez más crítica. Estos sistemas utilizan algoritmos sofisticados para hacer […]