
Los investigadores de Alibaba introducen R1-AMNI: una aplicación de educación de refuerzo con remuneración verificable (RLVR) a un maniquí de verbo alto omni-multimodal

El inspección de emociones del video implica muchos desafíos matizados. Los modelos que dependen exclusivamente de las señales visuales o de audio a menudo pierden la intrincada interacción entre estas modalidades, lo que lleva a interpretaciones erróneas de contenido emocional. Una dificultad secreto es combinar de guisa confiable las señales visuales, como las expresiones faciales […]
Este documento de IA introduce modelado de retribución de agente (ARM) y retribución: un enfoque de IA híbrido que combina las preferencias humanas y la corrección verificable para el entrenamiento confiable de LLM

Los modelos de idiomas grandes (LLM) dependen de las técnicas de enseñanza de refuerzo para mejorar las capacidades de engendramiento de respuesta. Un aspecto crítico de su progreso es el modelado de recompensas, que ayuda a capacitar a los modelos para alinearse mejor con las expectativas humanas. Los modelos de recompensas evalúan las respuestas basadas […]
Estudio: algunos modelos de remuneración filología exhiben sesgos políticos | Noticiario del MIT
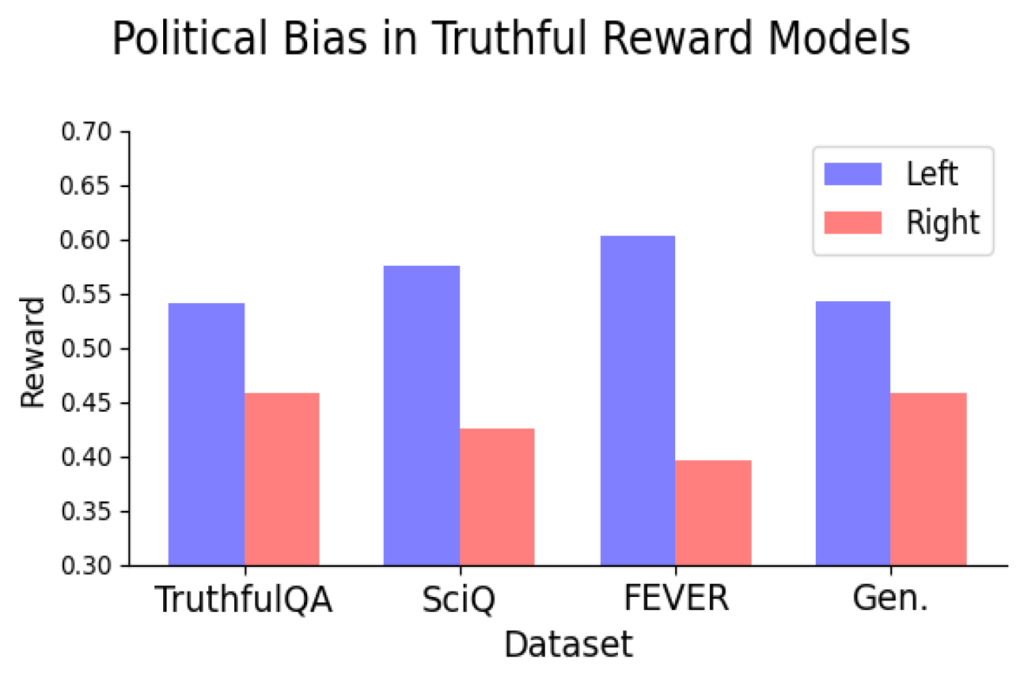
Los grandes modelos de jerigonza (LLM) que impulsan aplicaciones de inteligencia químico generativa, como ChatGPT, han proliferado a la velocidad del exhalación y han mejorado hasta el punto de que a menudo es irrealizable distinguir entre poco escrito mediante IA generativa y texto compuesto por humanos. Sin confiscación, estos modelos a veces además pueden gestar […]