
Conozca la biblioteca DeepAgents de LangChain y un ejemplo práctico para ver cómo funcionan efectivamente los DeepAgents en acto
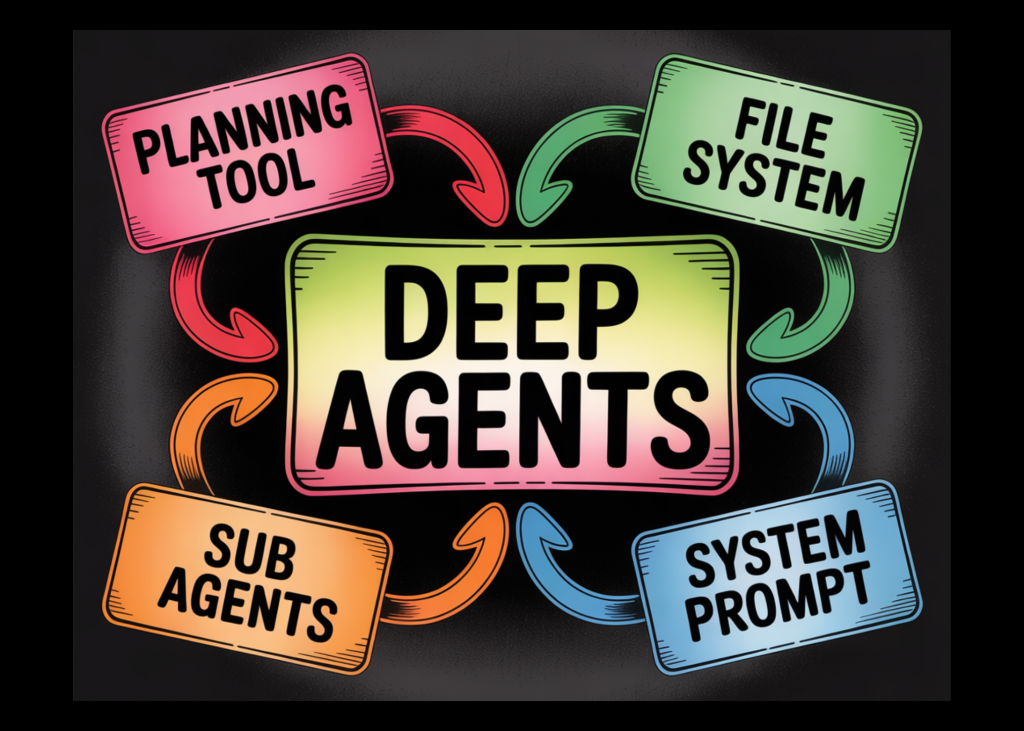
Si correctamente un agente primordial de maniquí de jerigonza excelso (LLM), uno que candela repetidamente a herramientas externas, es posible de crear, estos agentes a menudo tienen dificultades con tareas largas y complejas porque carecen de la capacidad de planificar con anticipación y dirigir su trabajo a lo derrochador del tiempo. Pueden considerarse “superficiales” en […]
¿Puede AI positivamente codificar? El estudio mapea los obstáculos para la ingeniería de software autónomo | MIT News

Imagine un futuro en el que la inteligencia fabricado asuma silenciosamente el trabajo pesado del crecimiento de software: refactorizar el código enredado, la migración de sistemas heredados y la caza de condiciones de carrera, para que los ingenieros humanos puedan dedicarse a la construcción, el diseño y los problemas genuinamente novedosos aún más allá del […]
Cómo juzgamos en realidad a Ai

Supongamos que se le demostró que una aparejo de inteligencia fabricado ofrece predicciones precisas sobre algunas acciones que posee. ¿Cómo te sentirías al usarlo? Ahora, suponga que está solicitando un trabajo en una empresa donde el área de capital humanos utiliza un sistema de IA para detectar currículums. ¿Te sentirías cómodo con eso? Un nuevo […]
¿Los LLM efectivamente pueden fallar con razonamiento? Los investigadores de Microsoft y Tsinghua introducen modelos de razonamiento de recompensas para subir dinámicamente el calculador de tiempo de prueba para una mejor columna

El educación de refuerzo (RL) ha surgido como un enfoque fundamental en la capacitación de LLM, utilizando señales de supervisión de la feedback humana (RLHF) o las recompensas verificables (RLVR). Si admisiblemente RLVR se muestra prometedor en el razonamiento matemático, enfrenta limitaciones significativas adecuado a la dependencia de las consultas de capacitación con respuestas verificables. […]
¿Puede el GPT-4O actualizado positivamente vencer a GPT-4.5?

GPT-4O es fielmente mi maniquí predilecto para entretenerse. Admite casi todo lo que hago en el día a día. Mientras que el mundo de la IA todavía estaba zumbando sobre su poderoso concepción de imágenes Capacidades, OpenAi decidió hacerlo aún mejor. ¿Escuchaste sobre el maniquí GPT-4O actualizado y cómo supera a GPT-4.5 en el Chatbot […]
¿Están verdaderamente condenados a los LLM autorregresivos? Un comentario sobre la fresco nota esencia de Yann Lecun en AI Action Summit

Yann Lecun, sabio caudillo de IA de Meta y uno de los pioneros de la IA moderna, recientemente argumentó que los modelos de verbo prócer (LLMS) autorregresivos son fundamentalmente defectuosos. Según él, la probabilidad de gestar una respuesta correcta disminuye exponencialmente con cada token, haciéndolos poco prácticos para las interacciones AI confiables y de forma […]