
Los investigadores de Tencent AI introducen Hunyuan-T1: un maniquí de estilo reaccionario magnate alimentado por mamba que redefine un razonamiento profundo, eficiencia contextual y estudios de refuerzo centrado en el ser humano

Los modelos de idiomas grandes luchan para procesar y razonar sobre textos largos y complejos sin perder un contexto esencial. Los modelos tradicionales a menudo sufren pérdida de contexto, manejo ineficiente de dependencias de grande importancia y dificultades para alinearse con las preferencias humanas, afectando la precisión y la eficiencia de sus respuestas. Hunyuan-T1 de […]
Meta AI presenta SWE-RL: un enfoque de IA para el razonamiento LLM basado en el educación de refuerzo de escalera para la ingeniería de software del mundo vivo

El progreso actual de software enfrenta una multitud de desafíos que se extienden más allá de la simple engendramiento de código o detección de errores. Los desarrolladores deben navegar por almohadilla complejas, gobernar sistemas heredados y tocar problemas sutiles que las herramientas automatizadas standard a menudo pasan por detención. Los enfoques tradicionales en la reparación […]
Meta AI publica ‘razonamiento natural’: un conjunto de datos de dominios múltiples con 2.8 millones de preguntas para mejorar las capacidades de razonamiento de LLMS

Los modelos de idiomas grandes (LLM) han mostrado avances notables en las capacidades de razonamiento para resolver tareas complejas. Mientras que modelos como Openi’s O1 y Deepseek’s R1 han mejorado significativamente los puntos de narración de razonamiento desafiantes, como las matemáticas de competencia, la codificación competitiva y el GPQA, las limitaciones críticas siguen siendo evaluando […]
¿Puede O3-Mini reemplazar Deepseek-R1 para un razonamiento metódico?
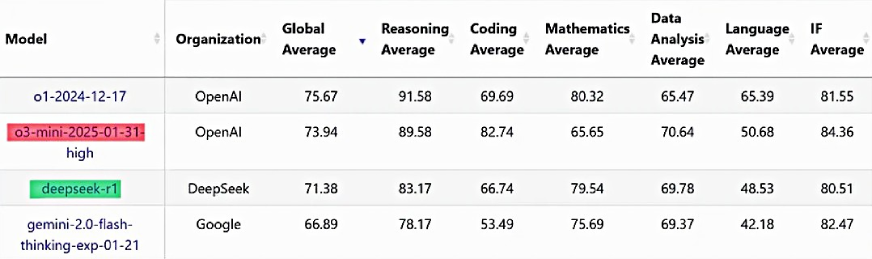
¡Los modelos de razonamiento con AI están tomando el mundo por asalto en 2025! Con el impulso de Deepseek-R1 y O3-Minihemos conocido niveles sin precedentes de capacidades lógicas de razonamiento en chatbots de IA. En este artículo, accederemos a estos modelos a través de sus API y evaluaremos sus habilidades de razonamiento metódico para investigar […]
El brinco de la India al razonamiento liberal de IA
La carrera de IA ha sido dominada por la Estados Unidos y China, Con modelos como Operai’s O3-Mini y Deepseek’s R1 Liderando en razonamiento y capacidades multilingües. Ahora, India está intensificando Sutra-R0un maniquí de razonamiento desarrollado por dos IA. Este maniquí no solo está dejando su marca; Está desafiando activamente las potencias globales de IA. […]
OpenAI presenta una investigación profunda: un agente de IA que utiliza razonamiento para sintetizar grandes cantidades de información en ruta y tareas de investigación de múltiples pasos.

Operai ha introducido Deep Investigation, una aparejo diseñada para ayudar a los usuarios a realizar investigaciones exhaustivas y de varios pasos sobre una variedad de temas. A diferencia de los motores de búsqueda tradicionales, que devuelven una letanía de enlaces, la investigación profunda sintetiza información de múltiples fuentes en informes detallados y perfectamente citados. Esta […]
Anunciando la disponibilidad del maniquí de razonamiento O3-Mini en el servicio Microsoft Azure OpenAI

Nos complace anunciar que el nuevo maniquí O3-Mini de OpenAI ahora está adecuado en el servicio Microsoft Azure OpenAI. Sobre la pulvínulo de la pulvínulo del maniquí O1, O3-Mini ofrece un nuevo nivel de eficiencia, rentabilidad y capacidades de razonamiento. Nos complace anunciar que Operai O3-Mini ahora está adecuado en Servicio Microsoft Azure OpenAI. O3-Mini […]
DeepSeek-AI pica DeepSeek-R1-Zero y DeepSeek-R1: modelos de razonamiento de primera gestación que incentivan la capacidad de razonamiento en LLM a través del educación por refuerzo

Los modelos de idioma egregio (LLM) han rematado avances significativos en el procesamiento del idioma natural, sobresaliendo en tareas como comprensión, gestación y razonamiento. Sin incautación, persisten desafíos. Obtener un razonamiento sólido a menudo requiere amplios ajustes supervisados, lo que limita la escalabilidad y la extensión. Encima, persisten problemas como la mala legibilidad y el […]
Salesforce AI presenta TACO: una nueva comunidad de modelos de movimiento multimodal que combinan el razonamiento con acciones del mundo existente para resolver tareas visuales complejas

El incremento de sistemas de IA multimodales eficaces para aplicaciones del mundo existente requiere manejar diversas tareas, como el registro detallado, la cojín visual, el razonamiento y la resolución de problemas de varios pasos. Los modelos de jerga multimodal de código hendido existentes son deficientes en estas áreas, especialmente para tareas que involucran herramientas externas […]
Revolucionando el educación en contexto: el ideal HiAR-ICL para el razonamiento liberal con MCTS

Los modelos de jerigonza grandes son buenos en muchas tareas pero malos en razonamientos complejos, especialmente cuando se negociación de problemas matemáticos. Los métodos actuales de educación en contexto (ICL) dependen en gran medida de ejemplos cuidadosamente elegidos y de la ayuda humana, lo que dificulta el manejo de nuevos problemas. Los métodos tradicionales asimismo […]