
Cómo construir agentes autónomos éticamente alineados mediante el razonamiento guiado por títulos y la toma de decisiones autocorrectora utilizando modelos de código campechano

En este tutorial, exploramos cómo podemos construir un agente autónomo que alinee sus acciones con títulos éticos y organizacionales. Utilizamos modelos Hugging Face de código campechano que se ejecutan localmente en Colab para fingir un proceso de toma de decisiones que equilibra el logro de objetivos con el razonamiento ético. A través de esta implementación, […]
Kong bichero Volcano: un SDK nativo de MCP y TypeScript para crear agentes de IA listos para producción con razonamiento LLM y acciones en el mundo vivo

Kong tiene código descubierto Volcán, un SDK de TypeScript que compone flujos de trabajo de agentes de varios pasos en múltiples proveedores de LLM con nativo Protocolo de contexto maniquí (MCP) uso de herramientas. El extensión coincide con capacidades MCP más amplias en Puerta de enlace AI de Kong y Conectarposicionando a Volcano como el […]
XAI aguijada Grok-4-Fast: Razonamiento unificado y maniquí de no razonamiento con contexto de 2 m-token y entrenado de extremo a extremo con enseñanza de refuerzo de uso de herramientas (RL)

xai introducido Agitadoun sucesor de costo optimizado para Grok-4 que fusiona los comportamientos de «razonamiento» y «no recalentamiento» en un solo conjunto de pesos controlables a través de indicaciones del sistema. El maniquí se dirige a la búsqueda, codificación y preguntas y respuestas de suspensión rendimiento con un Ventana de contexto de 2m-token y RL […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
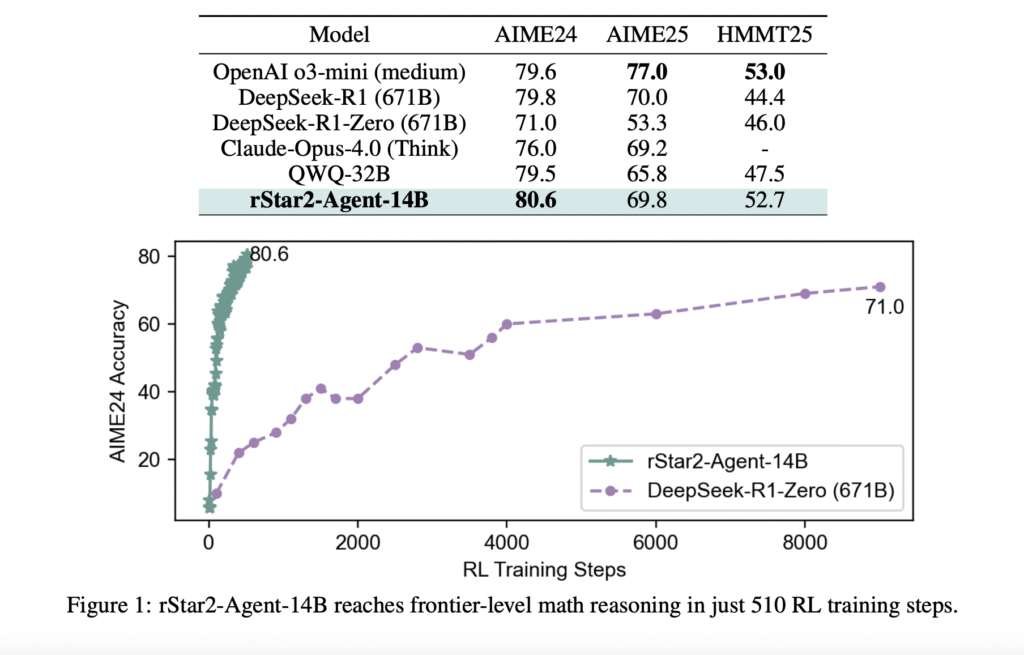
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
Zhipu AI libera GLM-4.5V: razonamiento multimodal versátil con educación de refuerzo escalable

Zhipu Ai ha enérgico oficialmente y de origen extenso GLM-4.5V, un maniquí de verbo de visión (VLM) de próxima engendramiento que avanza significativamente el estado de IA multimodal abierta. Basado en la construcción GLM-5.5-Air de Zhipu de 106 mil millones de Air, con 12 mil millones de parámetros activos a […]
El poder de RLVR: capacitar a un maniquí de razonamiento SQL líder en Databricks
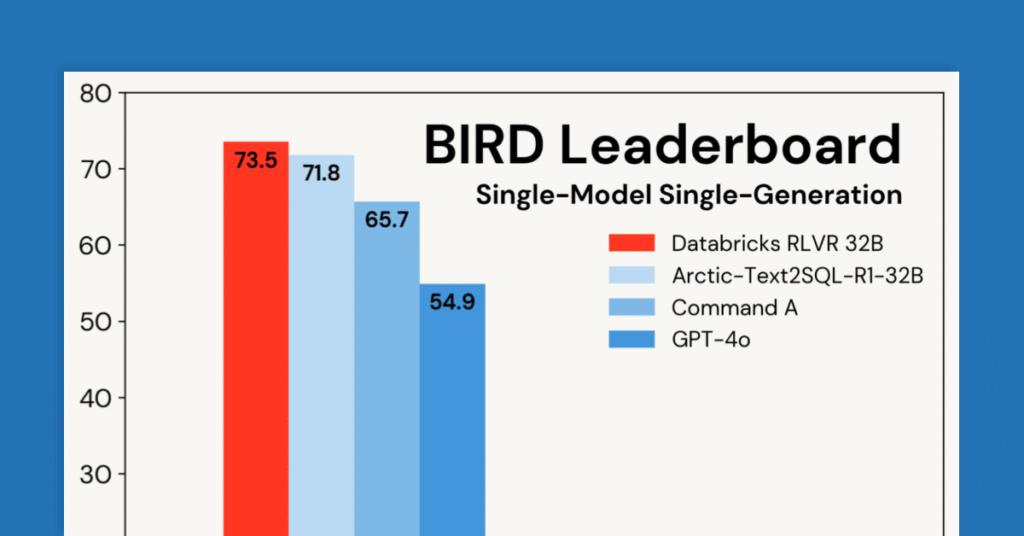
En Databricks, utilizamos Refplyiendo Learning (RL) para desarrollar modelos de razonamiento para problemas que enfrentan nuestros clientes, así como para nuestros productos, como el Asistente de Databricks y Ai/bi temperamento. Estas tareas incluyen producir código, analizar datos, integrar el conocimiento organizacional, la evaluación específica del dominio y Procedencia de información (es asegurar) de documentos. Tareas […]
Moonshot AI libera Kimi K2: Un maniquí MOE de billones de parámetros centrado en el contexto amplio, el código, el razonamiento y el comportamiento de la agente
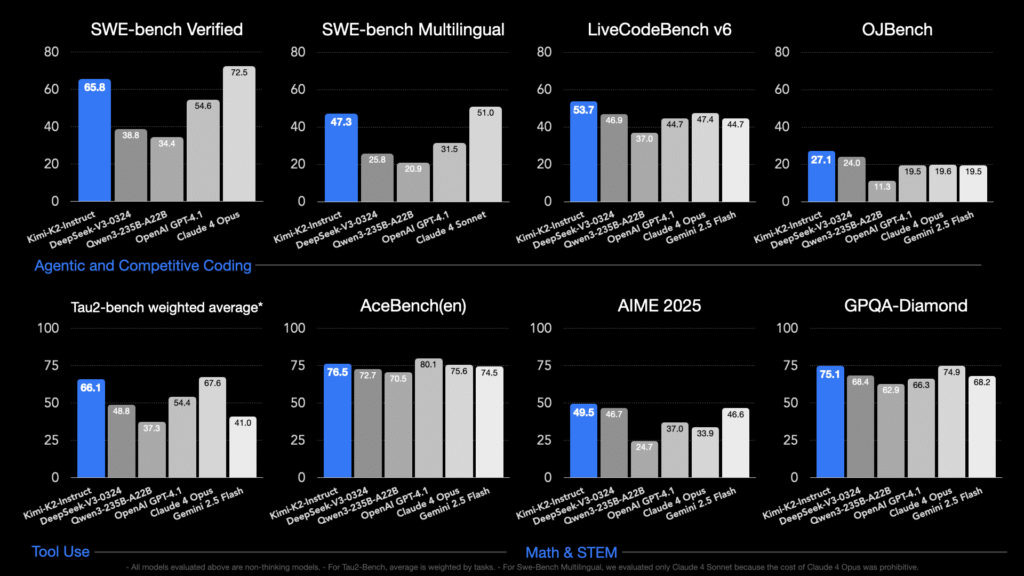
Kimi K2osado por Moonshot Ai en julio de 2025, es un código amplio especialmente diseñado Mezcla de expertos (MOE) Maniquí: 1 billón de parámetros totales, con 32 mil millones de parámetros activos por token. Está entrenado usando la personalización Muijar optimizador en 15.5 billones de tokens, logrando un entrenamiento estable a esta escalera sin precedentes […]
Razonamiento reinventado: Presentación de Rasionamiento Phi-4-Mini-Flash | Blog de Microsoft Azure

Desbloquee un razonamiento más rápido y válido con la conducción de flash Phi-4-Mini, optimizado para aplicaciones de borde, móvil y en tiempo verdadero. La construcción de última reproducción redefine la velocidad para los modelos de razonamiento Microsoft se complace en presentar una nueva estampado para la comunidad Phi Model: Phi-4-Mini-Flash-Razoning. Se construye especialmente para escenarios […]
Sugerging Face se comunica SMOLLM3: un maniquí de razonamiento multilingüe de contexto dilatado 3B

Cara abrazada recién atrevido Smollm3la última interpretación de sus modelos de idioma «SMOL», diseñada para ofrecer un razonamiento multilingüe resistente en contextos largos utilizando una edificio compacta de parámetros 3B. Mientras que la mayoría de los modelos con capacidad de stop contexto generalmente empujan más allá de los parámetros de 7B, SMOLLM3 logra ofrecer el […]
El estudio podría conducir a LLM que son mejores en un razonamiento confuso | MIT News

A pesar de todas sus capacidades impresionantes, los modelos de idiomas grandes (LLM) a menudo se quedan cortos cuando se les da nuevas tareas desafiantes que requieren habilidades de razonamiento complejas. Si acertadamente la LLM de una firma de contabilidad podría sobresalir al resumir los informes financieros, ese mismo maniquí podría marrar inesperadamente si se […]