
De los puntos ciegos a la inteligencia en tiempo verdadero: cómo los datos de ubicación de O2 Motion están transformando la toma de decisiones empresariales

Un comprador de medios gancho una campaña de vallas publicitarias digitales por valía de £50 000, solo para descubrir más tarde que la centro de las ubicaciones tuvieron un desempeño inferior; sin requisa, para entonces el presupuesto ya está viejo. Un administrador de red de transporte observa impotente cómo las multitudes se acumulan peligrosamente en […]
Una hoja de ruta técnica para la ingeniería de contexto en LLM: mecanismos, puntos de relato y desafíos abiertos
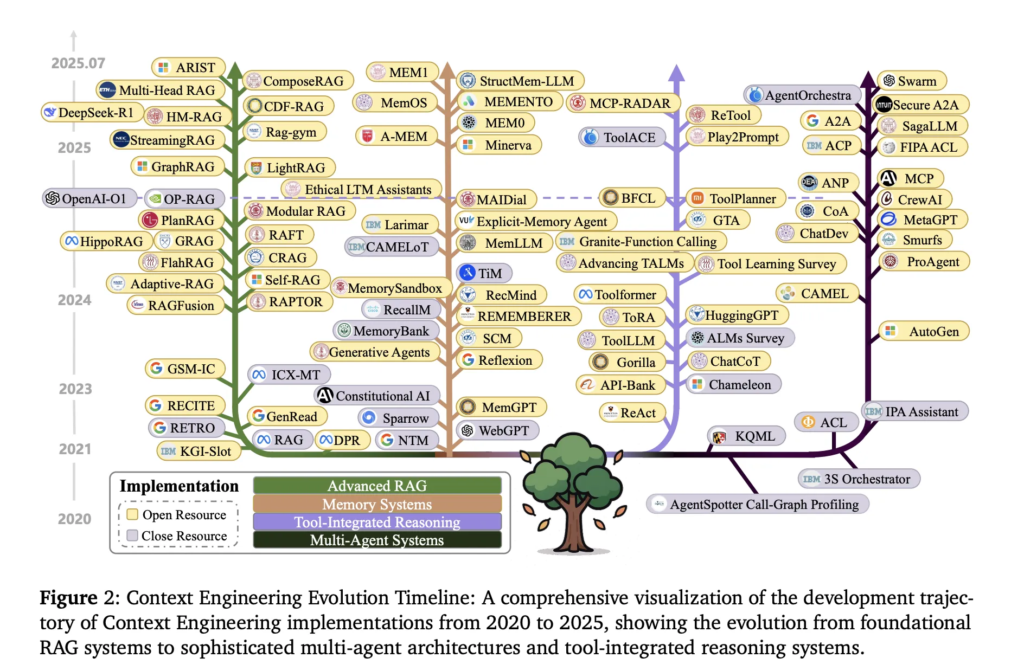
Tiempo de leída estimado: 4 minutos El papel «Una indagación de ingeniería contextual para modelos de idiomas grandes«Establece Ingeniería de contexto Como una disciplina formal que va mucho más allá de la ingeniería rápida, proporcionando un ámbito sistemático unificado para diseñar, optimizar y establecer la información que itinerario a los modelos de idiomas grandes (LLM). […]
La Finalidad Ultimate 2025 para codificar los puntos de remisión y las métricas de rendimiento

Los modelos de idiomas grandes (LLM) especializados para la codificación ahora son parte integral del progreso de software, impulsando la productividad a través de la concepción de códigos, la fijación de errores, la documentación y la refactorización. La feroz competencia entre los modelos comerciales y de código rajado ha llevado a un rápido avance, así […]
Los ecologistas encuentran puntos ciegos en los modelos de visión por computadora al recuperar imágenes de vida silvestre | Parte del MIT

Intente tomar una fotografía de cada uno de los lugares de América del Septentrión. casi nada 11.000 especies de árboles y tendrá una mera fracción de los millones de fotografías contenidas en conjuntos de datos de imágenes de la naturaleza. Estas enormes colecciones de instantáneas, que van desde mariposas a ballenas jorobadas – son una […]
Genere confianza en su espacio Genie con puntos de relato y solicite una revisión
Carácter de IA/BI es una experiencia conversacional para que los equipos de negocios puedan obtener información valiosa de sus datos a través del idioma natural. Genie aprovecha la IA generativa adaptada a los datos, los patrones de uso y los conceptos comerciales de una estructura y aprende continuamente de los comentarios de los usuarios. Esto […]
Exponiendo vulnerabilidades en los puntos de narración automáticos de LLM: la obligación de mecanismos antitrampas más sólidos

Los puntos de narración automáticos como AlpacaEval 2.0, Arena-Hard-Coche y MTBench han reses popularidad para evaluar LLM adecuado a su asequibilidad y escalabilidad en comparación con la evaluación humana. Estos puntos de narración utilizan anotadores automáticos basados en LLM, que se alinean perfectamente con las preferencias humanas, para proporcionar evaluaciones oportunas de nuevos modelos. Sin […]