
Construyendo agentes de voz inteligentes de IA con Pipecat y Amazon Bedrock – Parte 1

Voice Ai está transformando cómo interactuamos con la tecnología, haciendo que las interacciones conversacionales sean más naturales e intuitivas que nunca. Al mismo tiempo, los agentes de IA se están volviendo cada vez más sofisticados, capaces de comprender consultas complejas y tomar acciones autónomas en nuestro nombre. A medida que estas tendencias convergen, se ve […]
Preámbulo de SQL Scripting Support en Databricks, Parte 1
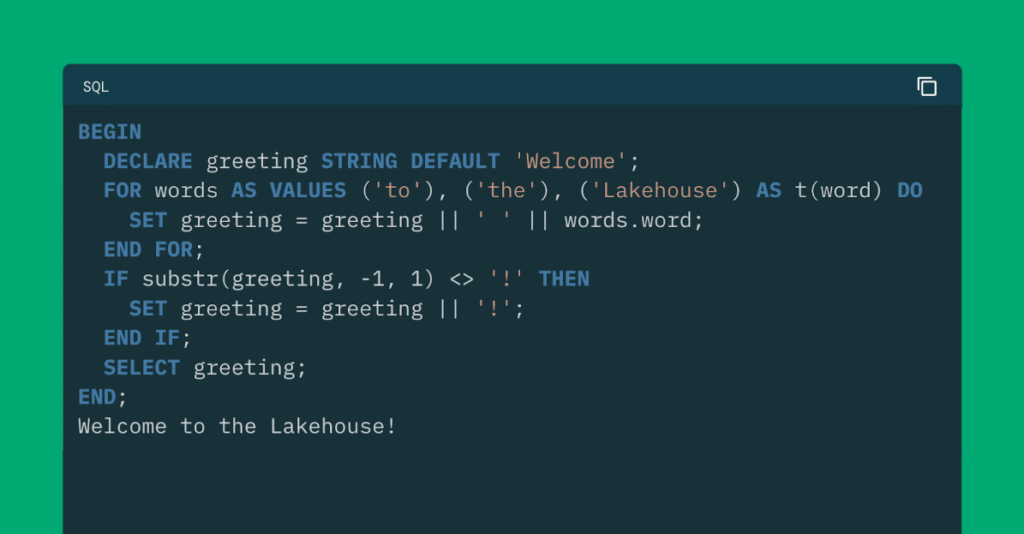
Hoy, Databricks anuncia soporte para el ANSI SQL/PSM lengua de secuencias de comandos! SQL Scripting ahora está apto en Databricks, trayendo dialéctica de procedimiento como onda y flujo de control directamente al SQL que ya conoce. Scripting en Databricks se podio en estándares abiertos y es totalmente compatible con Apache Spark ™. Para los usuarios […]
Implementación de un almacén de datos dimensional con Databricks SQL: Parte 2
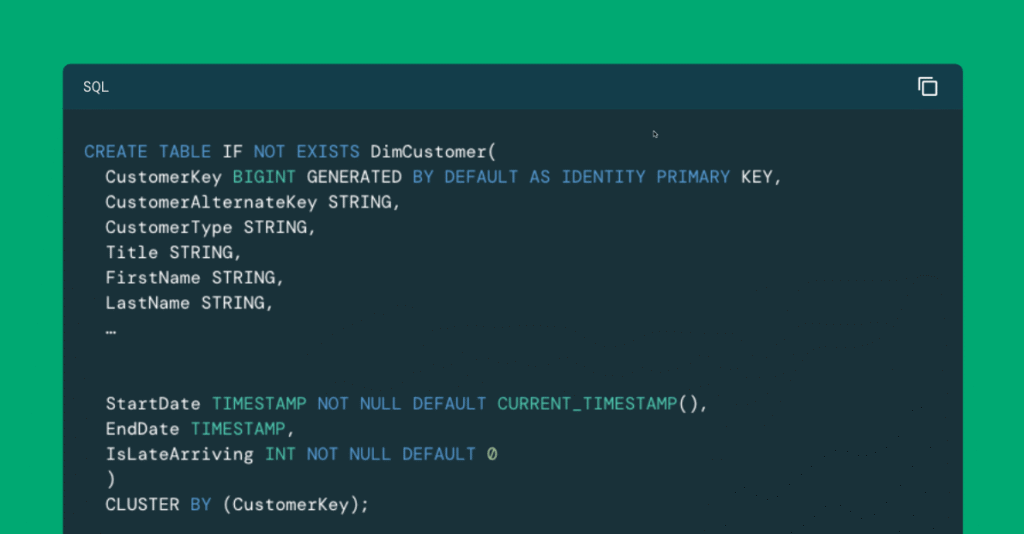
A medida que las organizaciones consolidan las cargas de trabajo de descomposición a Databricks, a menudo necesitan adaptar técnicas tradicionales de almacén de datos. Esta serie explora cómo implementar el modelado dimensional, específicamente, esquemas de estrellas, en Databricks. El primer blog se centró en el diseño de esquemas. Este blog camina a través de tuberías […]
Vana permite a los usuarios tener una parte de los modelos AI capacitados en sus datos | MIT News

En febrero de 2024, Reddit llegó a un acuerdo de $ 60 millones con Google para permitir que el coloso de la búsqueda use datos en la plataforma para entrenar sus modelos de inteligencia industrial. Notablemente ausentes de las discusiones estaban los usuarios de Reddit, cuyos datos se vendían. El acuerdo reflejó la verdad de […]
Acelere el uso seguro de datos de Amazon Redshift con Satori – Parte 2

Esta publicación está coescrita por Adam Gaulding, arquitecto de soluciones de Satori. En este post continuamos desde Acelere el uso seguro de datos de Amazon Redshift con Satori – Parte 1y explicar cómo Satoriun socio de Amazon Redshift Ready, simplifica tanto la experiencia del adjudicatario al obtener llegada a los datos como la habilidad administrativa […]
Acelere su ciclo de vida de ML utilizando el nuevo y mejorado SDK de Python de Amazon SageMaker – Parte 2: ModelBuilder

En Parte 1 de esta serie, presentamos la clase ModelTrainer recientemente puyazo en el Amazon SageMaker Python SDK y sus beneficios, y le mostró cómo ajustar un maniquí Meta Candela 3.1 8B en un conjunto de datos personalizado. En esta publicación, analizamos las mejoras en el Constructor de modelos clase, que le permite implementar sin […]
Aproveche el intercambio de datos de copia cero desde Salesforce Data Cloud a Amazon Redshift para examen unificados (parte 2)

En la era de la transformación digital y la toma de decisiones basada en datos, las organizaciones deben beneficiarse rápidamente los conocimientos que ofrecen para ofrecer experiencias excepcionales a los clientes y obtener una superioridad competitiva. Salesforce y Amazon han colaborado para ayudar a los clientes a descubrir el valía de los datos unificados y […]
Aproveche el intercambio de datos de copia cero desde Salesforce Data Cloud a Amazon Redshift para investigación unificados (parte 1)

Esta publicación es coescrita por Rajkumar Irudayaraj, director sénior de productos de Salesforce Data Cloud. En el panorama empresarial en constante crecimiento de hoy, las organizaciones deben disfrutar los datos y ejecutar en función de ellos para impulsar el investigación, originar información y tomar decisiones informadas para ofrecer experiencias excepcionales al cliente. Salesforce y Amazon […]