
Potenciando el estudios necesario en Snowflake con las bibliotecas NVIDIA CUDA-X para Scikit-learn y Pandas

Ya sea prediciendo la pérdida de clientes, detectando anomalías en los datos de transacciones o explorando patrones de aglomeración en incorporaciones de IA, las empresas están incorporando modelos generativos de IA y ML para utilizar conjuntos de datos más grandes que nunca. A medida que crecen los conjuntos de datos, la rapidez de la GPU […]
Tutorial para crear un agente de ciencias de datos: una implementación de código que utiliza el maniquí Gemini-2.0-Flash-Lite a través de Google API, Google.Generativeai, Pandas e Ipython.Splay para prospección de datos interactivos

En este tutorial, demostramos la integración del robusto pandas de la biblioteca de manipulación de datos de Python con las capacidades generativas avanzadas de Google Cloud a través del paquete Google.Generativeai y el maniquí Gemini Pro. Al configurar el entorno con las bibliotecas necesarias, configurar la secreto de la API de Google Cloud y servirse […]
Diferencias entre Pandas y PySpark

Dos de las librerías más utilizadas en el mundo de Python para el procesamiento de datos son Pandas y Pyspark (papelería de Python para spark) con características muy similares entre ellas incluyendo los nombres de algunos métodos o funciones. Generalmente la forma más global para tratar datos provenientes de archivos Excel, CSV, Parquet o Json […]
Ejecute pandas en datos empresariales de más de 1 TB directamente en Snowflake
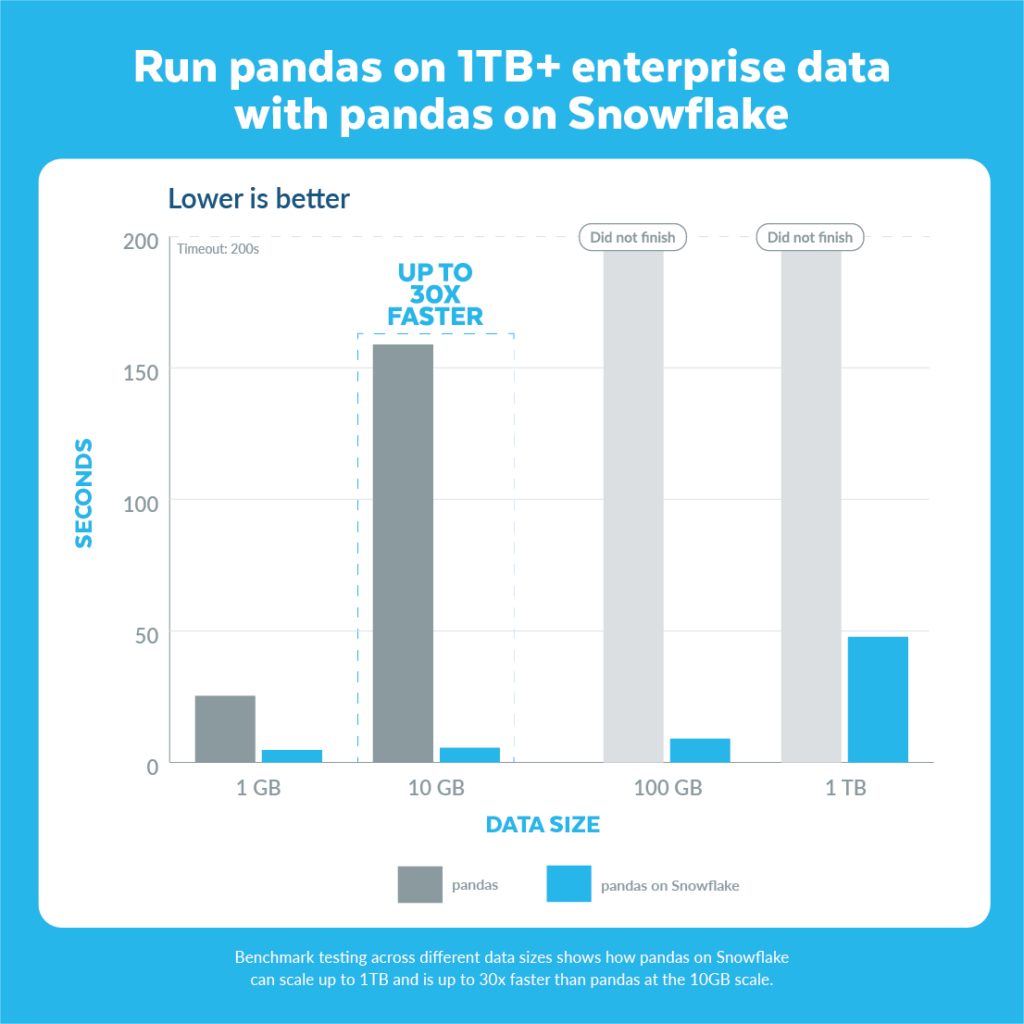
Nuestros estudios comparativos han demostrado que los pandas en Snowflake escalan a más de un terabyte de datos, para conjuntos de datos en los que la biblioteca de pandas normalizado se queda sin memoria incluso con menos de 100 GB. En promedio, en cargas de trabajo representativas, descubrimos que los pandas en Snowflake funcionan aproximadamente […]
The way to Deal with Outliers in Dataset with Pandas

Picture by Writer Outliers are irregular observations that differ considerably from the remainder of your information. They might happen resulting from experimentation error, measurement error, or just that variability is current throughout the information itself. These outliers can severely influence your mannequin’s efficiency, resulting in biased outcomes – very similar to how a prime […]