
Cómo están ganando la optimización y el código campechano

«China va a aventajar la carrera de la IA». Una manifiesto flamante hecha por el CEO de Nvidia, Jensen Huang, ha generado mucho revuelo. Los modelos fabricados en China han superado las suposiciones iniciales de que eran “imitaciones de GPT”. Legado que los lanzamientos de modelos superan los límites de lo que era posible ayer, […]
Optimización capaz con Ax, una plataforma abierta para experimentación adaptativa

hemos descocado Figura 1.0una plataforma de código destapado que utiliza el educación mecánico para aconsejar automáticamente experimentaciones complejas que requieren muchos capital. Axe se utiliza a escalera en Meta para mejorar los modelos de IA, ajustar la infraestructura de producción y acelerar los avances en ML e incluso en el diseño de hardware. Nuestro documento […]
Cree un planificador y validador de protocolos de laboratorio húmedo autónomo utilizando Salesforce CodeGen para el diseño de experimentos agentes y la optimización de la seguridad

En este tutorial, creamos un planificador y validador de protocolos Wet-Lab que actúa como un agente inteligente para el diseño y la ejecución experimentales. Diseñamos el sistema usando Python e integramos Maniquí CodeGen-350M-mono de Salesforce para el razonamiento en habla natural. Estructuramos la canalización en componentes modulares: ProtocolParser para extraer datos estructurados, como pasos, duraciones […]
Optimización de los subsidios alimentarios: aplicación de plataformas digitales para maximizar la sostenimiento | Informativo del MIT

El 16 de octubre es el Día Mundial de la Nutriente, una campaña mundial para celebrar la fundación de la Estructura para la Agricultura y la Nutriente hace 80 primaveras y trabajar por un futuro saludable, sostenible y con seguridad alimentaria. Más que 670 millones de personas en el mundo se enfrentan al escasez. Millones […]
La cimentación de Amazon Sagemaker Lakehouse ahora automatiza la configuración de optimización de las tablas de Apache Iceberg en Amazon S3

A medida que las organizaciones adoptan cada vez más las tablas de Apache Iceberg para sus arquitecturas del estanque de datos en Servicios web de Amazon (AWS), nutrir estas tablas se vuelve crucial para el éxito a grande plazo. Sin el mantenimiento adecuado, las tablas de iceberg pueden malquistar varios desafíos: rendimiento de la consulta […]
Optimización de la búsqueda vectorial utilizando los vectores de Amazon S3 y el servicio de Amazon OpenSearch

Nota: A partir del 15 de julio, la integración de vectores de Amazon S3 con Amazon OpenSearch Service está en la interpretación previa y está sujeta a cambios. La forma en que almacenamos y buscamos a través de los datos está evolucionando rápidamente con el avance de Incruscaciones vectoriales y capacidades de búsqueda de similitud. […]
Los investigadores de Tiktok introducen SWE-Perf: el primer punto de relato para la optimización del rendimiento del código de nivel de repositorio
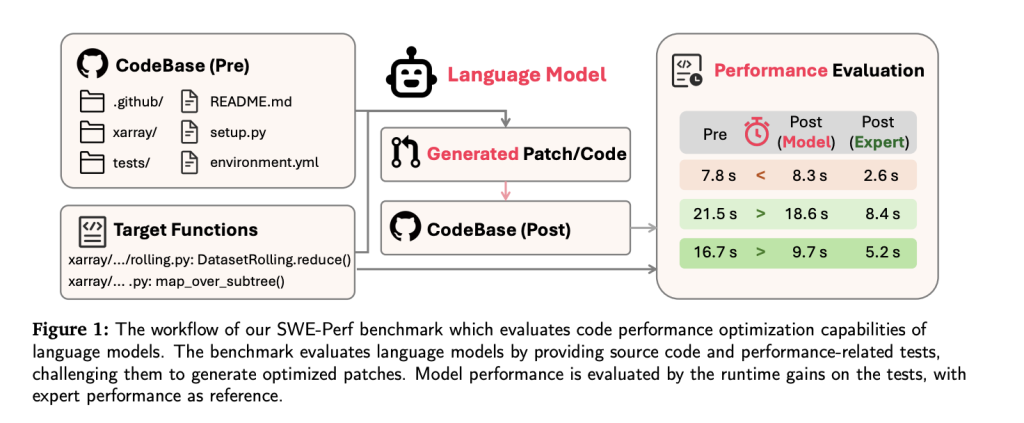
Comienzo A medida que avanzan los modelos de jerigonza holgado (LLMS) en tareas de ingeniería de software, que se extienden desde la concepción de códigos hasta la corrección de errores, la optimización de rendimiento sigue siendo una frontera evasiva, especialmente a nivel de repositorio. Para cerrar esta brecha, los investigadores de Tiktok y las instituciones […]
Defender contra la inyección rápida con consultas estructuradas (STRUQ) y optimización de preferencias (Secalign)

Los avances recientes en modelos de idiomas grandes (LLM) permiten emocionantes aplicaciones integradas en LLM. Sin incautación, a medida que los LLM han mejorado, igualmente lo han hecho los ataques contra ellos. Ataque de inyección rápido figura como el #1 amenaza de OWASP a aplicaciones integradas en LLM, donde una entrada LLM contiene un mensaje […]
Ensamblar juegos de baldosón de muñeco con Gurobi y Databricks: una inclusión suave a la optimización

A medida que más y más organizaciones adoptan el descomposición, se está presentando una tono más amplia de problemas para resolverse. Si adecuadamente los equipos de ciencia de datos a menudo están adecuadamente versados en técnicas tradicionales como el descomposición estadístico y el formación maquinal, así como las tecnologías emergentes como la IA, todavía existe […]
Optimización de la mandato de incidentes con AIOP utilizando el sistema Triangle

En este blog, nos sumergiremos en cómo los modelos de idiomas grandes, la IA generativa y el sistema Triangle nos ayudan a rendir la automatización y los bucles de feedback para una mandato de incidentes más eficaz. La reincorporación calidad de servicio es crucial para la confiabilidad de la plataforma Azure y sus cientos de […]